RGB-D显著性检测:贝叶斯融合与深度学习提升
版权申诉
121 浏览量
更新于2024-06-27
1
收藏 2.01MB DOCX 举报
显著性检测是计算机视觉中的核心任务,旨在模仿人类视觉注意力机制,高效地定位图像中最吸引人或具有重要意义的部分。Borji等人提出的显著性定义强调了对象相对于周围环境的突出特性,这对于众多视觉处理应用至关重要,如目标检测、识别、检索、视频质量评估、压缩、图像裁剪和跟踪等。
在传统的RGB图像显著性检测模型中,研究人员常利用底层特征如亮度、颜色、方向和纹理进行计算,如全球特征对比模型、局部特征对比模型以及结合两者的方法。这些模型关注的是图像局部和整体的差异性,以捕捉显著区域的特征。
然而,单纯依赖底层特征可能存在局限性,比如在复杂背景下,显著区域可能与背景难以区分。为提高检测准确性,研究者引入了高层特征,如位置先验(如物体的预期位置)、背景先验(背景知识)、颜色先验(对常见颜色分布的理解)、形状先验(基于预设的形状模式)和边界先验(边缘特征的分析)。这些先验知识有助于弥补底层特征的不足,提升检测精度。
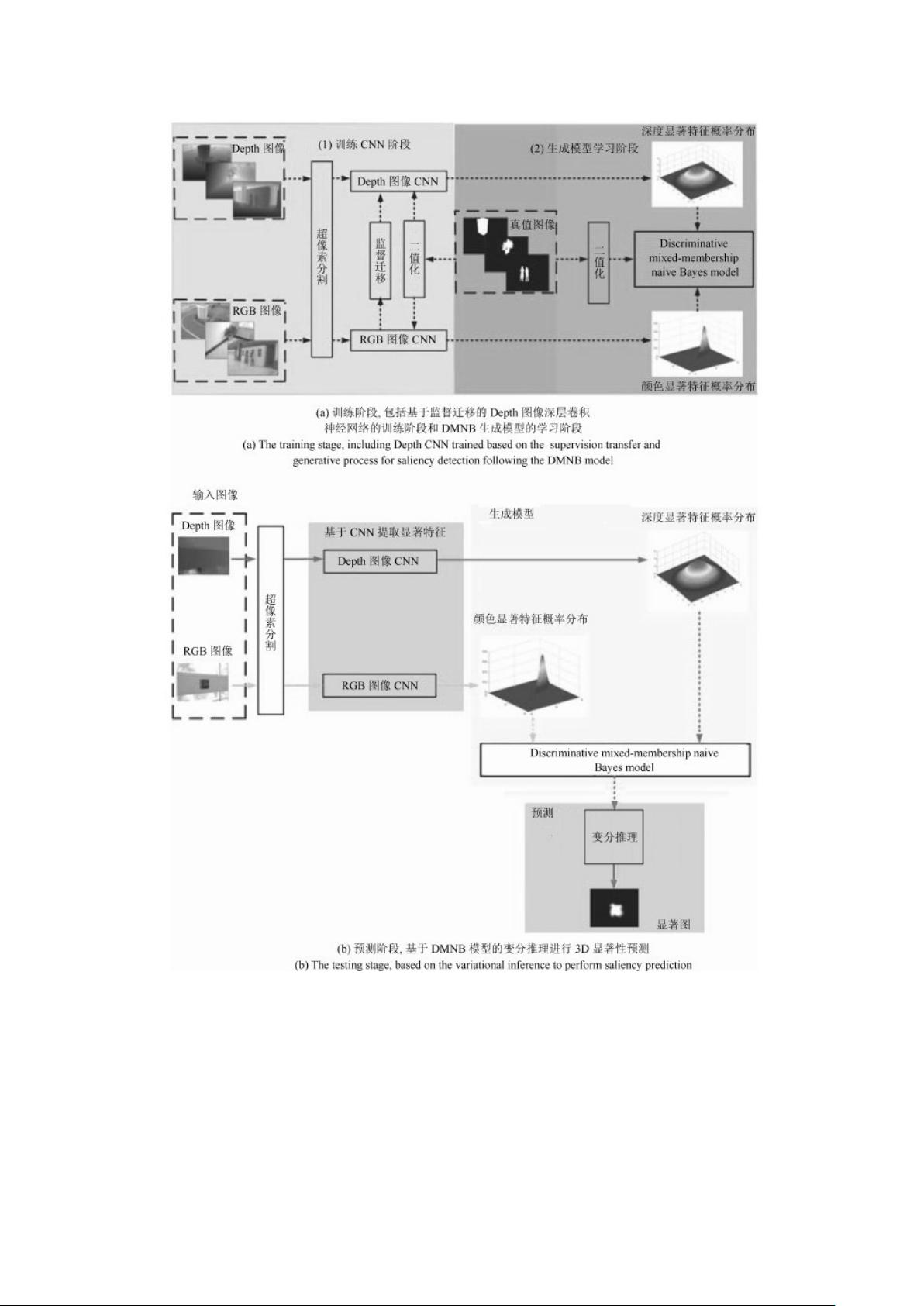
随着深度学习的兴起,特别是在目标检测领域的成功应用,显著性检测开始融合深度学习技术。例如,Zhao等人利用深层卷积神经网络(CNN)提取全局和局部上下文的语义特征,以类别对比差异作为显著性计算的基础。这种高级别类别特征(High-level category feature)的方法能够更好地适应复杂的图像场景,解决低层特征(如颜色)不显著的问题。
Li等人进一步发展了这一思路,通过多尺度分割和深度学习网络来增强显著性检测的鲁棒性和准确性。这些深度学习方法不仅提升了显著性检测的性能,还为3D图像和视频显著性检测开辟了新途径,如3D视频目标重定位、3D视频质量评估和3D超声波图像处理。
总结来说,基于贝叶斯框架融合的RGB-D图像显著性检测,是在传统特征对比和高层先验知识的基础上,结合深度学习技术,特别是利用高级别类别特征,以解决2D和3D场景中显著性检测的挑战,从而提升视觉信息处理的效率和精度。

剩余36页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-02-22 上传
2021-01-26 上传
2024-01-24 上传
2022-11-03 上传
2022-12-15 上传

罗伯特之技术屋
- 粉丝: 4459
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
