

P
c
:=
x
c
w
,
y
c
l
∈ 0, 1½
2
, with c
w
: = coil width and c
l
: = coil length. ð3Þ
Consequently, the reachable synchronization accuracy can be calculated
dependent on the coil c, the coil dimensions c
w
, c
l
and the resolution stage s ∈ 0, 8½
as
Δx
c, s
=
c
w
s
resp Δy
c, s
=
c
l
s
ð4Þ
Some exemplary values for Δx
c, s
and Δy
c, s
are also given in Table 2.
Once each coil position is normalized, the transformation of point-based raw
data into the grid structure can be performed quite easy by simple cell-based
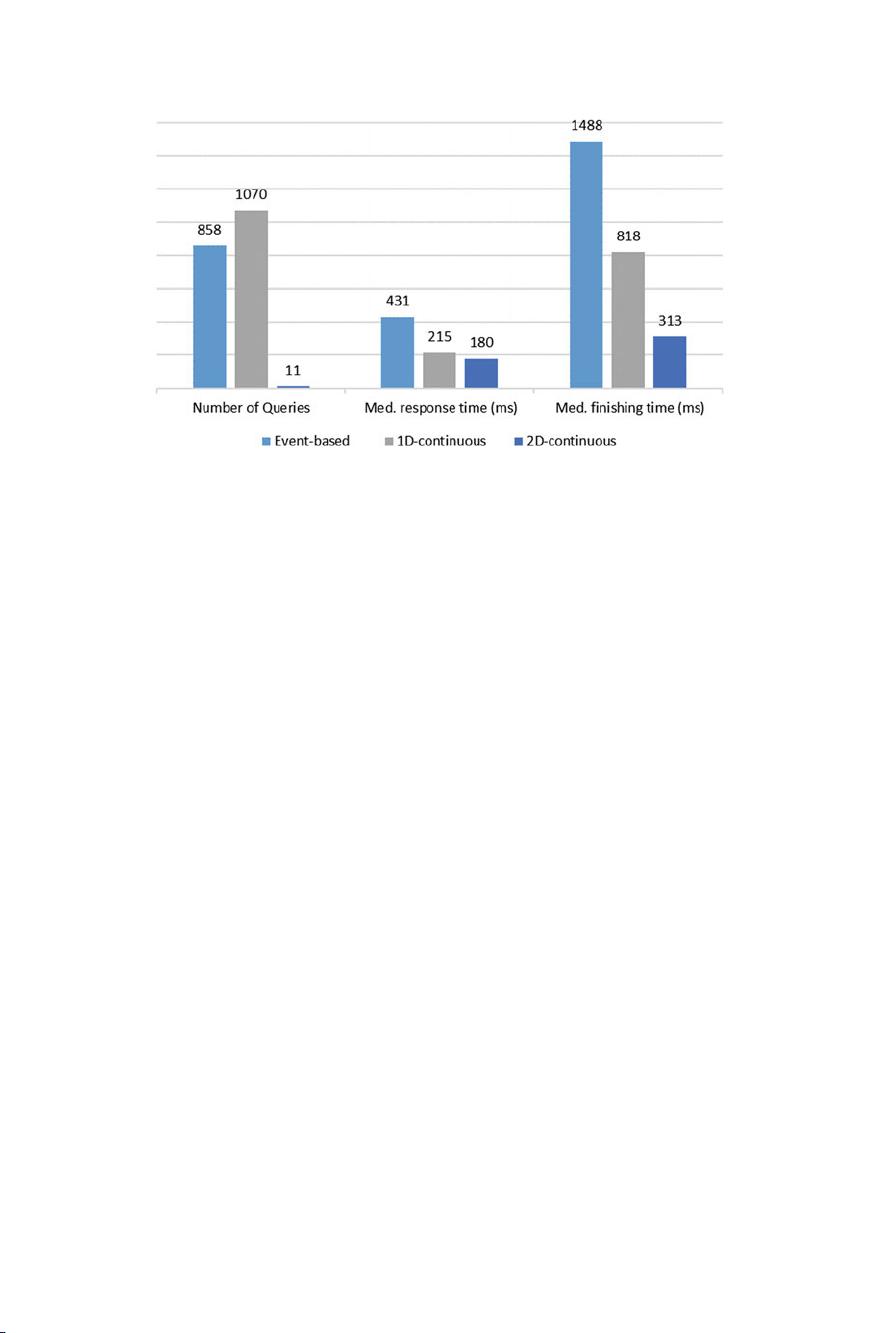
aggregation of all measurements falling into one specific grid cell. Regarding 1D
and 2D continuous measurements, the aggregations stored in the grid structure are
minimum, maximum, mean and count of the measuring values. Event-based data
(like surface defects) are usually stored as recta ngular regions combined with a
certain identifier describing the type of the event (e.g. defect class) and can either be
aggregated as absolute counts per grid cell or overlapping area relative to the full
cell area.
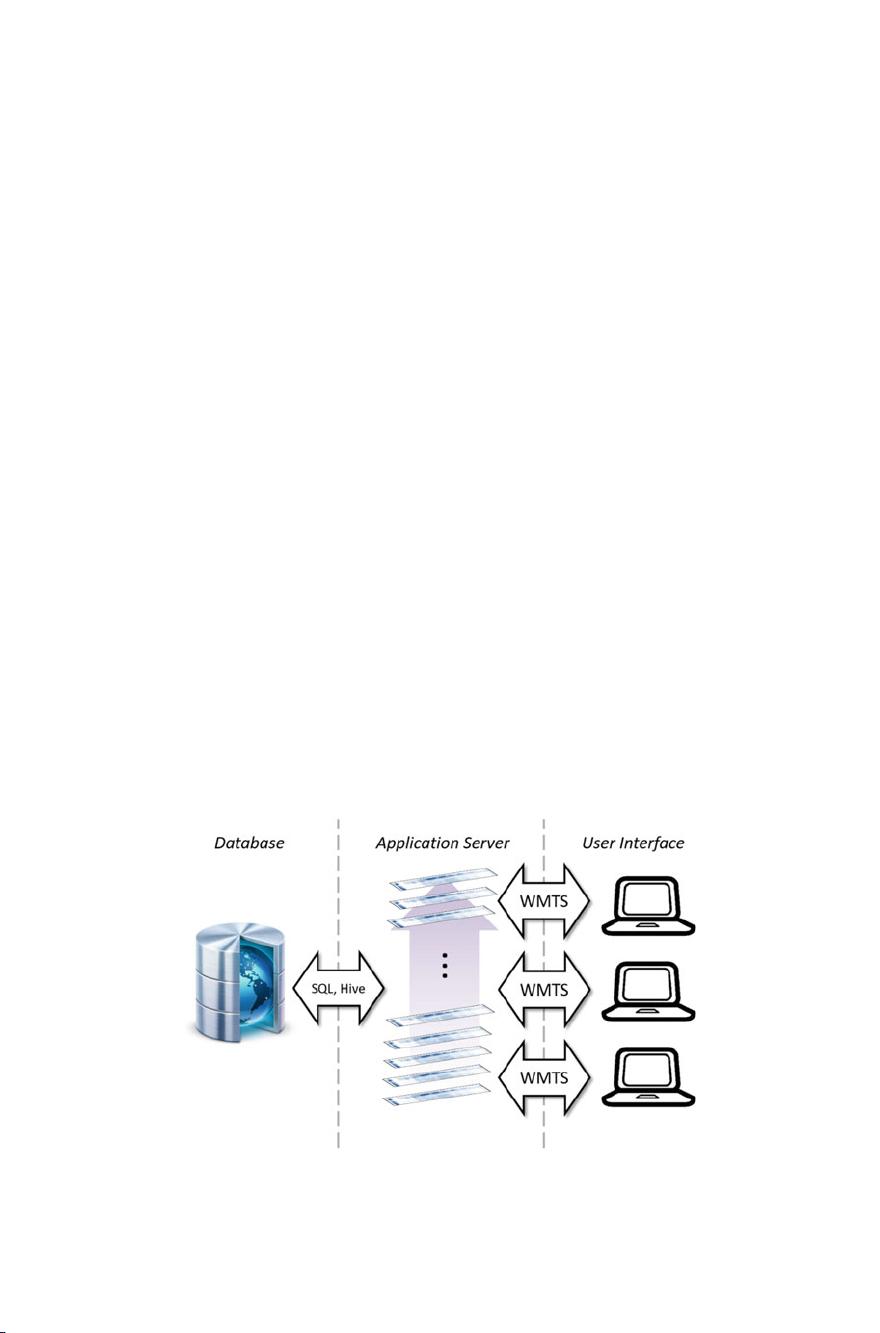
Given this multi-grid data representation, the question remains how to enable the
combination of data across production stages. This again can be easily solved by
not only simulta neous storage of data across different resolutions, but also across
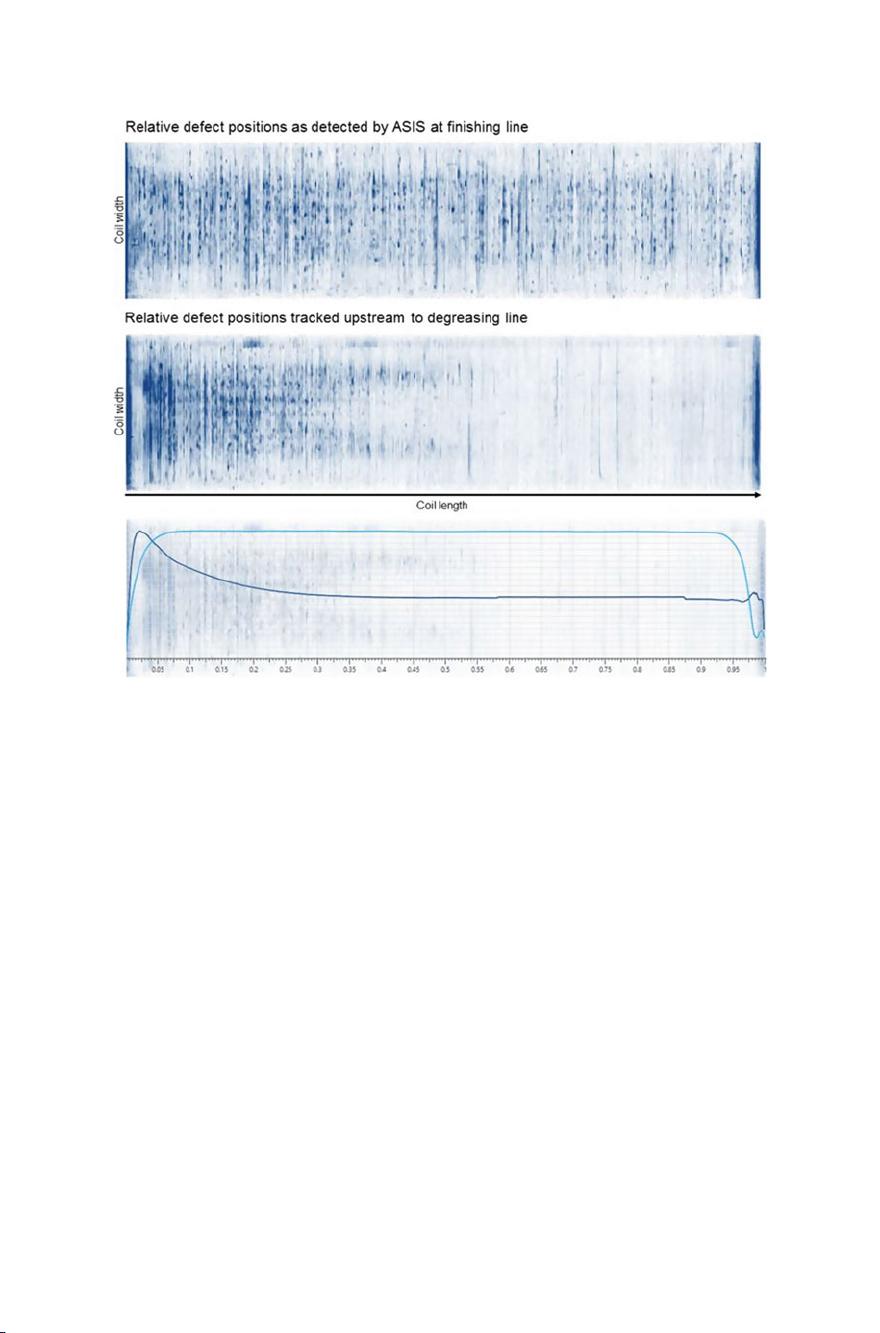
different perspectives. Assumed that the information about all coil transform ations
is given during data transformation, the data can be tracked upstream and/or
downstream and further grid data can be created and stored for each measurement
from the perspective of other production steps. The data is stored for each plant
separately according to the available material tracking information. Thus, the data is
available simultaneously in different plant coordinates enab ling fast HR data access
by means of redundant data storage.
Table 2 Grid definitions and exemplary sizes of grid cells for a coil length of 7500 m and a coil
width of 1500 mm
Stage Tiles CD Tiles MD Δx
c, s
(c
w
: = 1500 mm) (mm)
Δy
c, s
(c
l
: = 7500 m) (m)
0 1 2 1500 3750
1 2 4 750 1875
2 4 8 375 937.5
3 8 16 187.5 468.75
4 16 32 93.75 234.38
5 32 64 46.88 117.19
6 64 128 23.44 58.59
7 128 256 11.72 29.3
8 256 512 5.86 14.65
Applying Big Data Concepts to Improve Flat Steel … 9

剩余380页未读,继续阅读

寒沧
- 粉丝: 271
- 资源: 161
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


