Hadoop数据仓库:Hive实战与详解
需积分: 0 185 浏览量
更新于2024-06-30
收藏 106KB DOCX 举报
"Hive实战使用指南1 - VERSION 1.0 - 创建于2016年09月"
在本《Hive实战使用指南》的第一部分中,我们主要介绍了Hive的基础知识和架构,包括它的编写背景、文档说明以及Hive的核心功能和体系结构。
1. 编写背景:
该指南的编写主要是由于项目交付中心预见到了未来对Hadoop和Hive大量需求的增加。为了分享和传授应用经验,这份文档应运而生,旨在帮助团队成员更好地理解和使用Hive。
2. 文档说明:
文档的阅读权限限制在核心员工之间,未经许可不得随意传播。文档的解释权归项目交付中心所有。
3. Hive简介:
Hive是一个基于Hadoop的数据仓库工具,它使得非Hadoop专家也能对大规模数据进行分析。Hive提供了类似SQL的语言HQL,使得熟悉SQL的用户能方便地进行数据查询。此外,对于更复杂的分析工作,Hive允许开发人员编写自定义的Mapper和Reducer来扩展其功能。
4. Hive体系架构:
- 用户接口:包括命令行接口(CLI)、客户端(Client)和Web用户界面(WUI)。CLI是最常用的,它会在启动时启动一个Hive实例。Client是用于连接HiveServer的客户端,而WUI则可以通过浏览器访问。
- 元数据存储:Hive将元数据(如表名、列、分区等信息)存储在像MySQL或Derby这样的数据库中。
- 解释器、编译器、优化器和执行器:这些组件负责HQL查询的处理,从解析到生成查询计划并存储在HDFS中,最终由MapReduce执行。
- Hadoop集成:Hive的数据存储在HDFS上,大多数查询通过MapReduce执行,但不包括简单的全列选择查询(如`select * from tbl`)。
5. 数据存储与数据类型:
- 数据存储:Hive的所有数据都存在于HDFS中,对数据存储格式无特殊要求,只需在创建表时指定列和行分隔符。
- 数据类型:Hive的基本数据类型与Java基本类型对应,包括string、int、boolean等。
本指南的后续部分可能会深入探讨Hive的表创建、查询语法、分区策略、优化技巧以及其他高级特性,以帮助读者全面掌握Hive的实战应用。对于初学者和Hadoop环境下的数据分析师来说,理解这些基础知识是至关重要的,这将使他们能够有效地利用Hive处理和分析大数据。
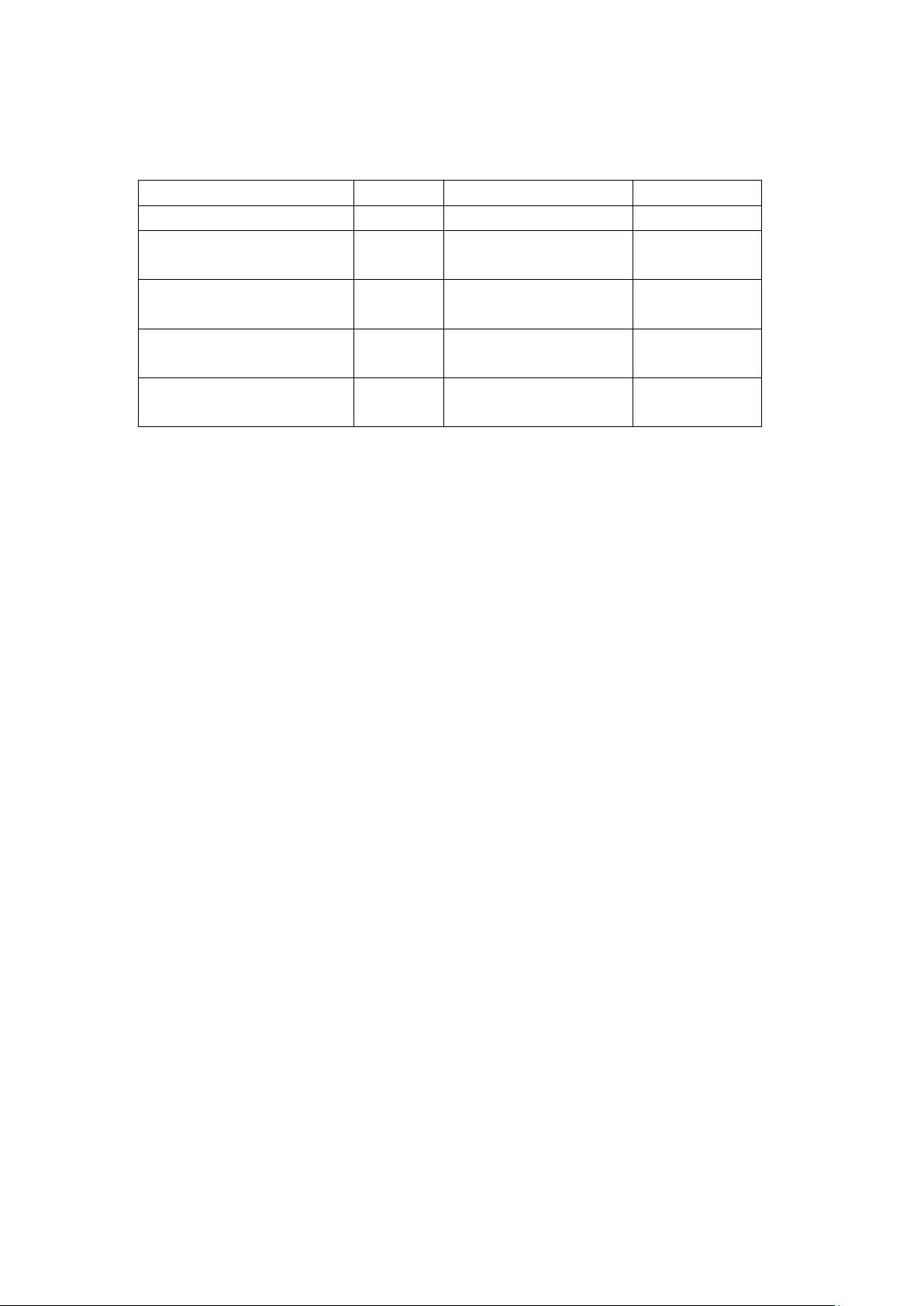
6.1 压缩格式对比
压缩方式
压缩比
优点
缺点
DefaultCodec
1:1
无需解压
存储大
BZip2Codec
1:5
压缩比最高
支持块分割
Cpu 开销最多
GzipCodec
1:3.5
压缩比高
CPU 开销多
不支持分割
LzopCodec
1:2.5
解压速度快
支持分割(需建索引)
压缩比小
SnappyCodec
1:2.5
解压速度快
压缩比小
不支持分割
基于用户所使用的 Hadoop 版本,会提供不同的编解码器,查看编解码器的方法两种,
使用 Hive 的 set io.compression.codecs;再者查看 Hadoop 集群的配置文件
示例:
hive (default)> set io.compression.codecs;
io.compression.codecs=org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.BZip2Codec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.SnappyCodec
6.2 压缩格式建议
在 O 域项目中,由于 O 域的数据量比较大,考虑到集群整体性能的因素,应用的压缩格
式为 Snappy。其他项目可以根据各自的数据量所选择,Lzo 是个不错的选择。
7 HiveQL:数据定义
HiveQL 是 Hive 查询语言。和普通使用的所有 SQL 方言一样,他不上网安全遵守任何一
种 ANSISQL 表针的修订版。HiveQL 和 MySQL 的方言最近进,但是两者还是存在显著性的差
异。Hive 不支持行级插入操作、更新、和删除操作。Hive 也不支持事物。Hive 增加了在 Hadoop
北京下的可以提供跟高性能的扩展,一级一些个性化的扩展,甚至还增加一些外部程序。
7.1 Hive 中的数据库
Hive 中数据库的概念本质上仅仅是表的一个目录或者命名空间。这样对于应用 Hive
搭建数据仓库,具有很多组合用户的集群来说,这是非常有用的,因为这样可以避免表


剩余67页未读,继续阅读
2022-08-03 上传
2024-04-24 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

我只匆匆而过
- 粉丝: 20
- 资源: 316
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
