
4
Input Output
Block
Input
Output
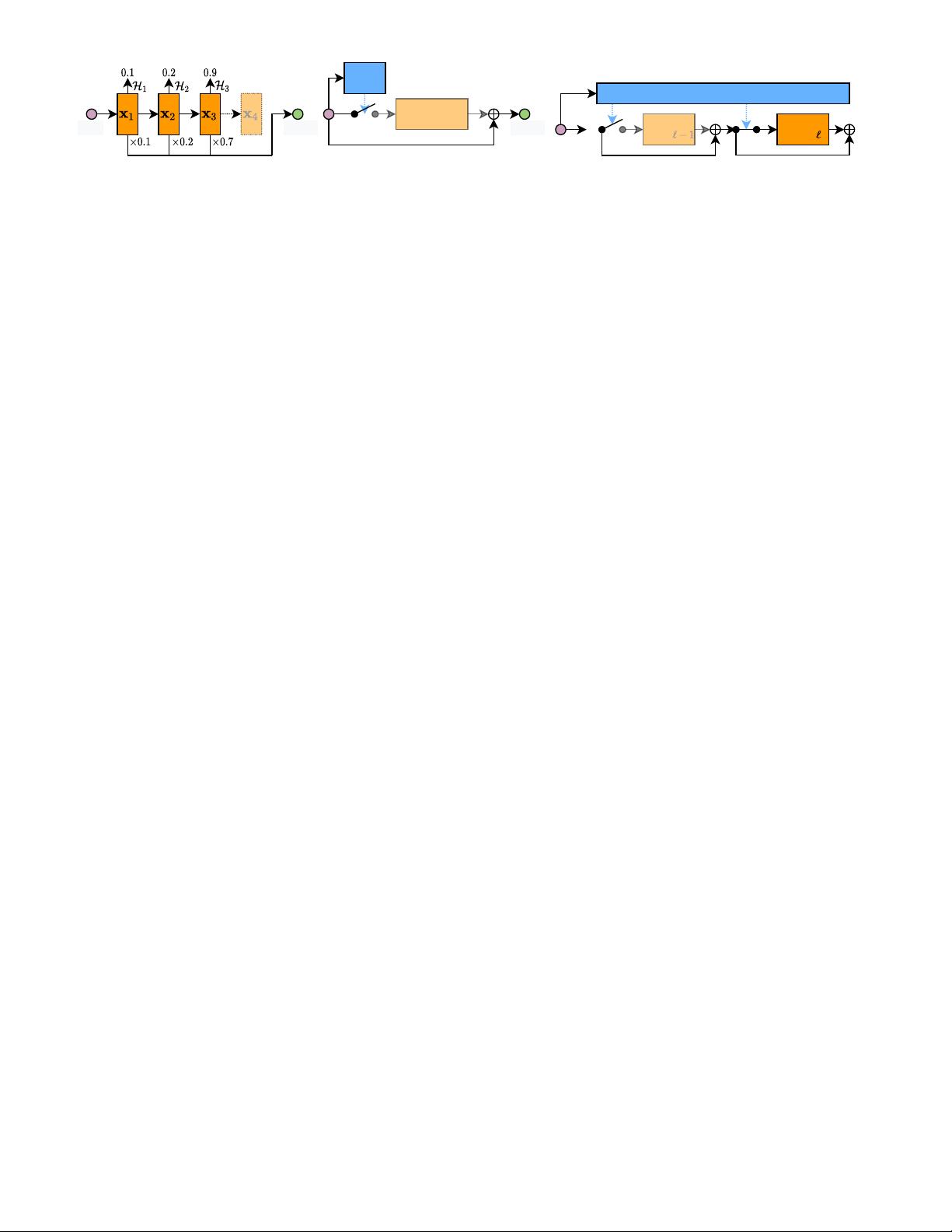
(a) Layer skipping based on halting score. (b) Layer skipping based on a gating function.
Gating
Module
... ...
Policy Network
(c) Layer skipping based on a policy network.
Input
Block Block
Fig. 4. Dynamic layer skipping. The dashed features in (a) are not calculated conditioned on the halting score, and the gating module in (b) decides
whether to execute the layer/block. The extra policy network in (c) directly generates the skipping decisions for all layers in the main network.
c) Multi-scale architecture with early exits. Researchers [12]
have observed that in chain-structured networks, the multi-
ple classifiers may interfere with each other, which degrades
the overall performance. A reasonable interpretation could
be that in regular CNNs, the high-resolution features lack
the global information that is essential for classification,
leading to unsatisfying results for early exits. Moreover,
early classifiers would force the shallow layers to generate
task-specialized features, while a part of general information
is lost, leading to degraded performance for deep exits.
To address this issue, multi-scale dense network (MSDNet)
[12] adopts 1) a multi-scale architecture, to quickly gener-
ate coarse-level features that are suitable for classification;
2) dense connections, to reuse early features and improve
the performance of deep classifiers (see Fig. 2 (a)). Such
a specially-designed architecture effectively enhances the
overall accuracy of all the classifiers in the network.
Besides the architecture design, the exiting policies and
training techniques are also important for the model per-
formance. Apart from the confidence-based criteria in [12],
policy networks are built for the multi-scale dynamic mod-
els with early classifiers (see Fig. 2 (b)) [61], [62] to make
decisions on whether each instance should exit. As for
training, specific techniques are studied in [63] for multi-exit
networks. More discussion about the inference and training
schemes for dynamic models will be reviewed in Sec. 5.
The methods discussed above mostly implement the
early-exiting scheme via depth adaptation. From the per-
spective of exploiting spatial redundancy in features, res-
olution adaptive network (RANet, see Fig. 2 (c)) [30] fur-
ther achieves resolution adaptation with depth adaptation
simultaneously. Specifically, the network first processes each
instance with low-resolution features, while high-resolution
representations are utilized conditioned on the prediction
confidence of early classifiers.
2) Layer skipping. In the aforementioned early-exiting
paradigm, the general idea is skipping the execution of all
the deep layers after a certain classifier. More flexibly, the
network depth can also be adapted on the fly by strategi-
cally skipping the calculation of intermediate layers without
placing extra classifiers. Given the i-th input instance x
i
,
dynamic layer skipping could be generally written as
y
i
= (1
L
◦ F
L
) ◦ (1
L−1
◦ F
L−1
) ◦ · · · ◦ (1
1
◦ F
1
)(x
i
), (3)
where 1
`
denotes the indicator function determining the
execution of layer F
`
, 1 ≤ ` ≤ L. This scheme is typically im-
plemented on structures with skip connections (e.g. ResNet
[4]) to guarantee the continuity of forward propagation, and
here we summarize three representative approaches.
a) The halting score. Adaptive computation time (ACT)
[11] is achieved based on an RNN, where a scalar named
halting score is accumulated as multiple layers are sequen-
tially executed within a time step, and the hidden state of
the RNN will be directly fed to the next step if the score
exceeds a threshold. The ACT method is further extended
to ResNet for vision tasks [31] by viewing residual blocks
within a stage
1
as linear layers within a step of RNN (see
Fig. 4 (a)). Moreover, the halting score in [31] is allowed
to vary across spatial locations. Rather than skipping the
execution of layers with independent parameters, iterative
and adaptive mobile neural network (IamNN) [64] replaces
multiple residual blocks in each ResNet stage by one block
with shared weights, leading to a significant reduction of
parameters. In every stage, the block is executed for an
adaptive number of steps according to the halting score.
In addition to RNNs and CNNs, the halting scheme is
further implemented on Transformers [6] by [33] and [34] to
achieve dynamic network depth on NLP tasks.
b) Gating function. Apart from comparing the calculated
halting scores with certain thresholds as in aforementioned
approaches, gating function is also a prevalent option for
making discrete decisions due to its plug-and-play property.
By generating binary values based on intermediate features,
a gating function can determine the skipping/execution of
a layer (block) on the fly (see Fig. 4 (b)).
Take the layer skipping in ResNet as an example, let x
`
denote the input feature of the `-th residual block, gating
function G
`
generates a binary value to determine the exe-
cution of F
`
. This procedure could be represented by
2
x
`+1
= G
`
(x
`
)F
`
(x
`
) + x
`
. (4)
SkipNet [45] and convolutional network with adaptive
inference graph (conv-AIG) [46] are two representative ap-
proaches to enabling dynamic layer skipping. Both methods
induce lightweight computational overheads to efficiently
produce the binary decisions on whether skipping the calcu-
lation of a residual block. Specifically, Conv-AIG utilizes two
FC layers in each residual block, while the gating function in
SkipNet is implemented as an RNN for parameter sharing.
Rather than skipping layers in classic ResNets, dynamic
recursive network [65] iteratively executes one block with
shared parameters in each residual stage. Although being
seemingly similar to the aforementioned IamNN [64], its
decision policies differs significantly. Without tuning the
threshold for halting scores as IamNN, gating modules are
exploited by [65] to decide the recursion depth.
Instead of either skipping a layer, or executing it thor-
oughly with a full numerical precision, a line of work [66],
[67] studies adaptive bit-width for different layers condi-
tioned on the resource budget. Furthermore, fractional skip-
1. Here we refer to a stage as a stack of multiple residual blocks with
the same feature resolution.
2. For simplicity and without generality, the subscript for sample
index will be omitted in the following.
剩余19页未读,继续阅读

曾荣飞
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


