

DNA 元基催化与肽计算_第 5 修订版本 V00058 16
avoiding, tunning the constant values, balancing the computing sets and the discrete conditions differentiations(Demorgan,
Frequency flows etc). and now those things widely were used in Deta’s catalytic family technology community (parser, word
segments, mindreading, NLP computing etc).
神经网络索引
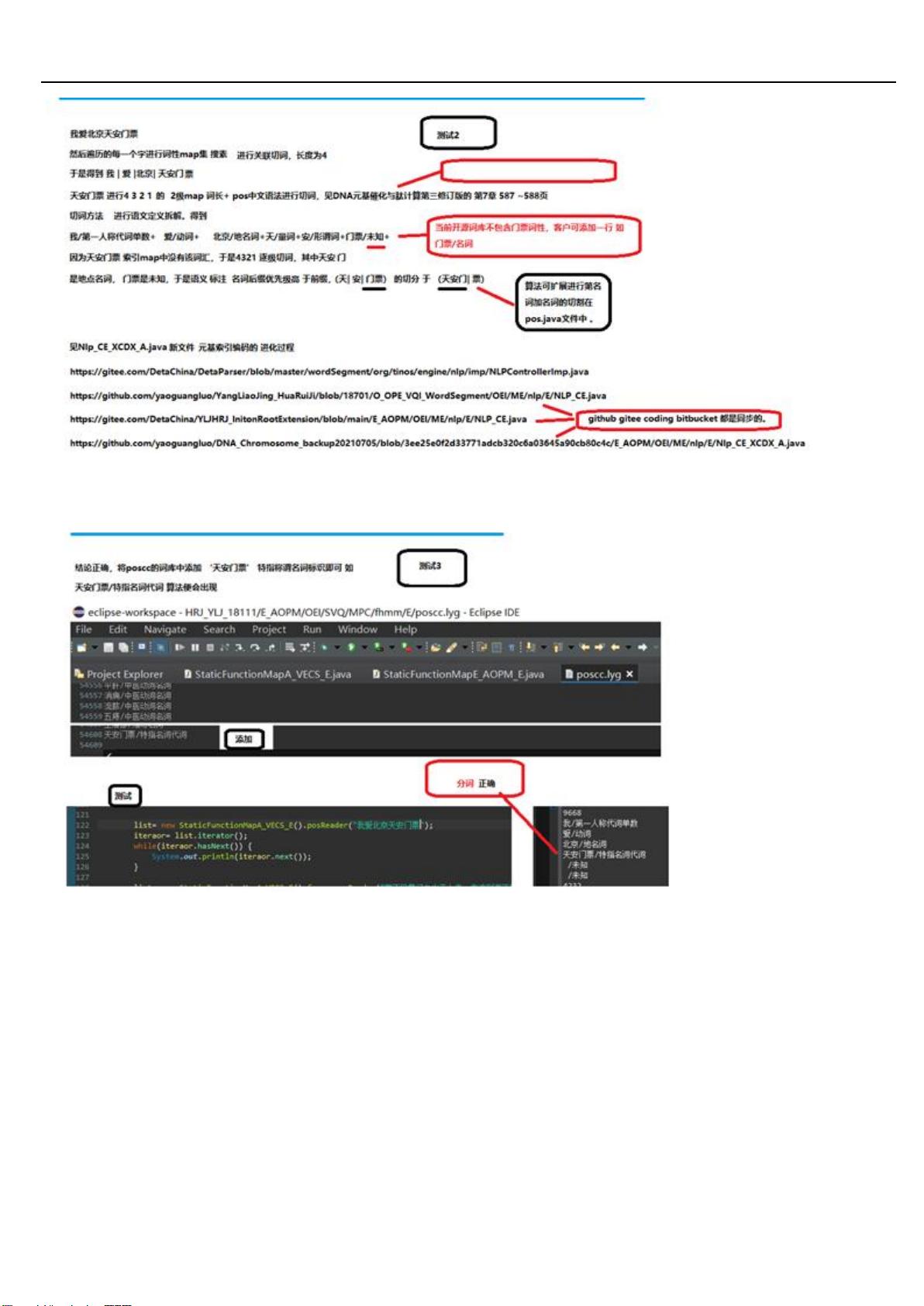
1 德塔分词的词汇字典用 map 进行索引, 因为 jdk8+的 map 对象的 key 支持 2 分搜索, 搜索速度到了峰值. refer
page, 129, 131
2 德塔分词的索引不断的将大 map 进行细化分类, 如词长 map, 词类 map, 词性 map, 让搜索再次加速. refer page 55,
3 德塔分词的索引 map 支持 2 次组合计算, 支持分布式服务器进行索引 cache. 关于 2 次组合计算作者不建议单机使用.
refer page 92,
4 德塔分词 map 的 key 用 string 的 char 对应 ASCII int 进行标识来执行 find key, 方便二分搜索存储和 StringBuilder
高速计算, 实现底层核统一. refer page 92
Nero Network Index Forest
1 Deta Parser did a word segment indexed map by using humanoid speech verbal dictionary, for the reason why using JDK8+ tool
to do the map search logic, is that it had already integrated the binary search tree, balanced map tree arrangement and other
technologies.
2 Deta Parser’s balanced binary search tree method makes an observer mode of averaged classification with all types of the
reflection java concurrent maps, those maps include the char word length, verbal types and Part of speech corpus, etc. The author
did it to accelerate the NERO marching speed for searching the words.
3 Deta Parser supports the secondary indexing computing combinations, this way could be suitable for the distributed cache
searching systems. The author does not suggest this technology be used on a single desktop.
4 For the computing logic, Finally Deta Parser functions use string builder to accelerate the searching engine.
神经网络索引的价值主要体现在 2 个地方, 切词的关联索引上和 词汇 map 索引上. 切词的关联索引价值, 主要体现在将
词汇的文字进行链化提取, 这种链化计算方式将词库中本相对独立的海量词汇进行了按人类语言文学中的顶针方法进行
了有效的前后长度关联(NERO), 其价值有利于大文本的文字进行有必要关联链的 小段小段的提取(NLP), 类似挤牙
膏一样, 挤出来就刷牙用掉(POS).
词汇 map 索引价值, 主要体现在 词汇的文字进行链化合理切分, 这种链化切分方式将词库中根据不同属性的分类 map
来组合匹配按人类语言文学中的词汇词性和主谓宾搭配严谨定义来切分. 其价值在这些分类 map 可以自适应设计和多
样化扩展. 增加切词准确度和灵活度, 适应各种不同的场景, 类似牙刷机制, 挤出牙膏根据 匹配不同的牙刷和刷牙方法
(NERO + POS), 匹配适应不同的口腔环境. 描述人 罗瑶光 , 稍后优化下
The accomplishment of the neural network index is mainly reflected in two sections, 1, the relevance index of word segmentation
and 2, the lexical index map. The associated relevance index value of word segmentation is mainly reflected in the chained
extraction of words. This chained calculation method effectively correlates the relatively independent of a large number of words
in the thesaurus, according to the Thimble Theory in human language and Literature (Nero). The value of the big data document
process splits the word chain links list into a small chars token(max 4) sections, and It is similar to squeezing toothpaste, and
brushing the teeth (POS) when squeezed out by the DetaParser marching engine.



剩余312页未读,继续阅读















