
4
J. Jiang
,
H. Zhang
和
D.Pi
等人专家系统与应用:
X 1
(
2019
)
100003
算法:BLSM
(
T
,
M
,
r
,
k
,
s
)。
输入:
T
-
训练集
M-
少数民族范例集
r
,
k
-最近邻
s-
合成示例的数量,其占给定类
输出:
合成少数样本集:
M
r
1.
D
=0
//
D
是包含边界样本的集合
2.
对于
M
do
中的所有
m
i
3.
N
m
i
←
m
i
在T中的r个最近邻
4.
n
←
N
m
i
中的样本数,而不是
M
中的
5.
如果
r
/
2
≤
nr
,则
r/
m
i
是边界样本
<
6.
将m
i
加到D
7.
end if
8.
端
9. M
r
=
m
//
M
r
是包含合成样本
10
的集合。
对于
所有
d
i
in
Ddo
11.
N
d
i
←
M
中
d
i
的
k
个最近邻居
12.
对于
i
=1
到
s
,
13.
m
←
从
N
d
i
14.
d
i
r
<$
d
i
+
p
<$
(
d
i
−
m
)
//
p是
(
0
,
1
)中的随机数
,
d
i
r
是合成样本
15
。
将
d
i
r加
到
M
r
16.
端
17.
端
18.
M
r
=
M
r
<$
M
//
M
r
是少数样本和合成样本的并集
19
。
返回
M
r
图二
.
MMNNS示意图
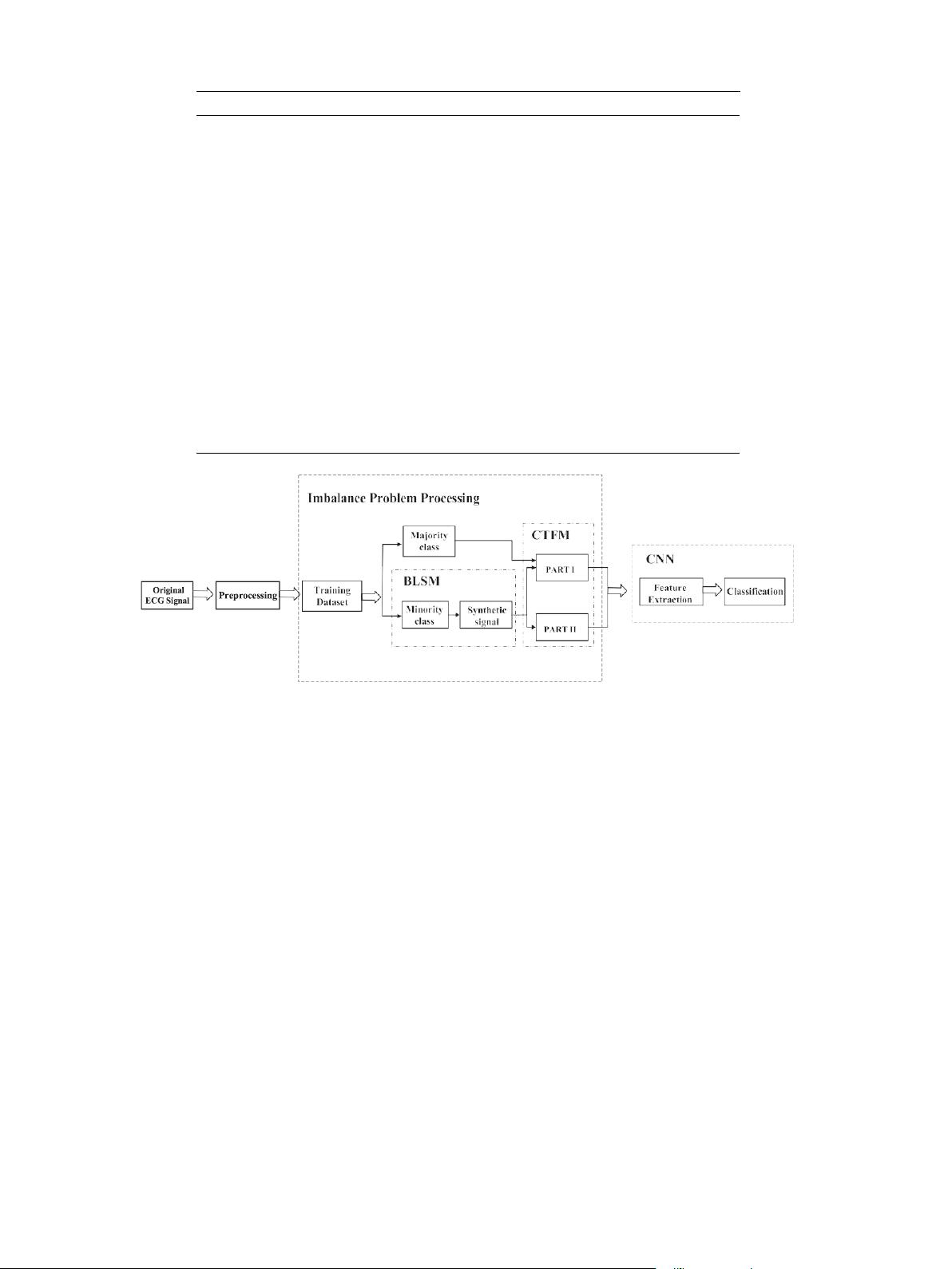
3.2.
不平衡问题处理
数据不平衡是指训练集中某个类的数量相对于其他类过多
的现象。数字太多的类称为多数类,而其他类称为少数类。
大多数真实世界的数据集是不平衡的。例如,MIT-BIH心律
失常数据库中N型心跳的数量是Q型的8000多倍,是F型的
100倍在医疗诊断中,错误地将少数人(即异常样本),这
将延迟最佳 治 疗 时 间 , 远远 高 于 大 多数类别( 即 正 常 样
本)。此外,大多数机器学习算法都是在假设基础训练集是
平衡的情况下设计的。训练数据的这种高度偏斜的分布将倾
向于迫使学习算法偏向多数类。这不仅限制了 训练阶段的
收敛性,也影响模型的泛化能力和测试集的准确性。因此,
少数民族阶层的重要性不容忽视,它是解决本研究失衡问题
的关键。
解 决 阶 级 不 平衡 的 方 法 可 以 分 为 三 大 类 (
Buda
,
Maki
,
&Mazurowski
,
2017;Guo
,
Li
,
Shang
,
Gu
,
Huang
,
&Gong
,
2017
)。
数据级方法主要通过过采样或欠采样来改变训练数据的分
布。过采样的基本方法是从少数类中随机抽取样本进行简单的
重复,称为随机过采样。
然而,随机过采样容易导致过拟合。作为 因 此 ,提出了更先
进的技术,如
SMOTE
,基于过采样的过采样,
DataBoost-IM
,
类感知采样和其他调整的
SMOTE
策略(
Chawla
,
Bowyer
,
Hall
,
&Kegelmeyer
,
2002; Guo& Viktor
,
2004; Jo&
Japkowicz
,
2004;Maldonado
,
López
,
&Vairetti
,
2019; Shen
,
Lin
,
&Huang
,
2016
)。欠采样与过采样不同,欠采样从多数
中随机删除样本,直到分布达到平衡。使用欠采样时,必须注
意避免在数据选择中丢失有用信息。
算法级方法通过在训练数据分布不变的情况下调整算法来克
服类不平衡,包括保留算法、代价敏感学习、增强方法和单类
分类(
Elkan
,
2001; Lee &Cho
,
2006; Sun
,
Kamel
,
Wong
,
&Wang
,
2007; Zhou& Liu
,
2006
)。虽然成本敏感学习可以显
著提高分类性能,但它们仅适用于错误分类成本已知的情况。
不幸的是,确定某些特定领域的错误分类成本是相当具有挑战
性的,甚至是不可能的(
Wang
等人,
2016
年)。至于集成方
法,需要相当长的时间来训练多个分类器,当我们使用深度神
经网络作为基础分类器时,这是不切实际的。因此,已经提出
了诸如二阶锥编程
SVM
(
Maldonado& López
,
2014
)的新 方
法。
混合方法结合了数据层和算法层的方法,如
EasyEntrance
、
BalanceCasecade
、
SMOTEBoost
、
Two-Phase Training
等
.
(
Chawla
,
Lazarevic
,
Hall
,
Bowyer
,
2003
年
;
剩余15页未读,继续阅读

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 贵州煤矿矿井水分类与处理策略:悬浮物、酸性与非酸性
- 醛固酮增多症肾上腺静脉采样对比:ACTH后LR-CAV的最优评估
- 开源云连接传感器监控平台:农业土壤湿度远程监测
- 母婴用品企业年度生产计划线性规划优化模型:实证与应用
- 井下智能变电站:Rogowski线圈电流检测系统的研发与性能验证
- 霍州矿区煤巷稳定性分析及支护策略
- ARM嵌入式系统远程软件更新方案:基于TFTP协议
- 煤炭选煤中汞分布规律与洗选脱汞效果
- 提升码垛机器人性能:拉格朗日动力学模型与滑模模糊控制的应用
- 增强现实技术提升学前手写教学:设计与开发案例
- 不规则工作面沉陷三角剖分算法提升与应用
- 卡尔曼滤波在瞬变电磁干扰压制中的应用研究
- 煤矿安全能力研究:理论与系统构建
- LonWorks总线技术在斜巷运输车辆定位与跑车防护中的应用
- 神东煤炭集团高效煤粉锅炉系统:节能环保新实践
- Ti/SnO2+Sb2Ox/PbO2电极分形维数与电催化性能研究
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


