Impala:实时大数据查询利器,挑战Hive的传统架构
需积分: 15 70 浏览量
更新于2024-09-11
收藏 164KB DOCX 举报
Impala与Hive是两种在大数据领域广泛应用的查询工具,尤其在处理实时交互式SQL查询时有着显著的区别。Impala是Cloudera基于Google的Dremel技术发展而来,旨在提供更快的查询性能,与传统的Hive+MapReduce批处理方式形成鲜明对比。
首先,从架构上看,Impala采用了更为现代化的设计,包括Query Planner(查询规划器)、Query Coordinator(查询协调器)和Query Exec Engine(查询执行引擎)这三个核心组件。这允许它直接从HDFS或HBase中进行实时查询,无需中间步骤,显著减少了延迟。相比之下,Hive依赖于MapReduce模型,处理速度受限于批处理周期。
Impala的查询流程是这样的:客户端发起查询请求后,由Impalad(类似DataNode的角色)接收,然后解析和优化SQL语句生成查询计划。这个过程通过JNI调用Java前端,形成查询树后,协调器负责将任务分配给各个有相应数据的Impalad执行。Impalad不仅负责数据处理,还与StateStore通信以维持集群状态信息,如Impalad的健康状况和位置。
StateStore作为重要的元数据管理组件,存储着Impalad的健康信息和位置,但同时也存在潜在问题。如果StateStore离线,Impalad会进入恢复模式,尝试重新连接。然而,由于缓存的存在,即使在StateStore离线期间,Impalad仍能继续执行查询,但可能因为缓存信息不准确导致分配到失效的Impalad,从而引发查询失败。
另一方面,Hive通常使用Hive Metastore来存储元数据,查询过程可能涉及多次元数据查询和调度,性能上不如Impala直接。Hive更适合离线批处理作业,而Impala则更适用于需要快速响应的实时分析场景。
Impala通过其高效的分布式查询引擎和流式传输机制,为大数据分析提供了更快的查询性能和更好的用户体验,尤其是在交互式查询和实时分析方面。而Hive则在批处理和历史数据处理方面拥有优势。企业可以根据具体需求,灵活选择适合自己的工具。
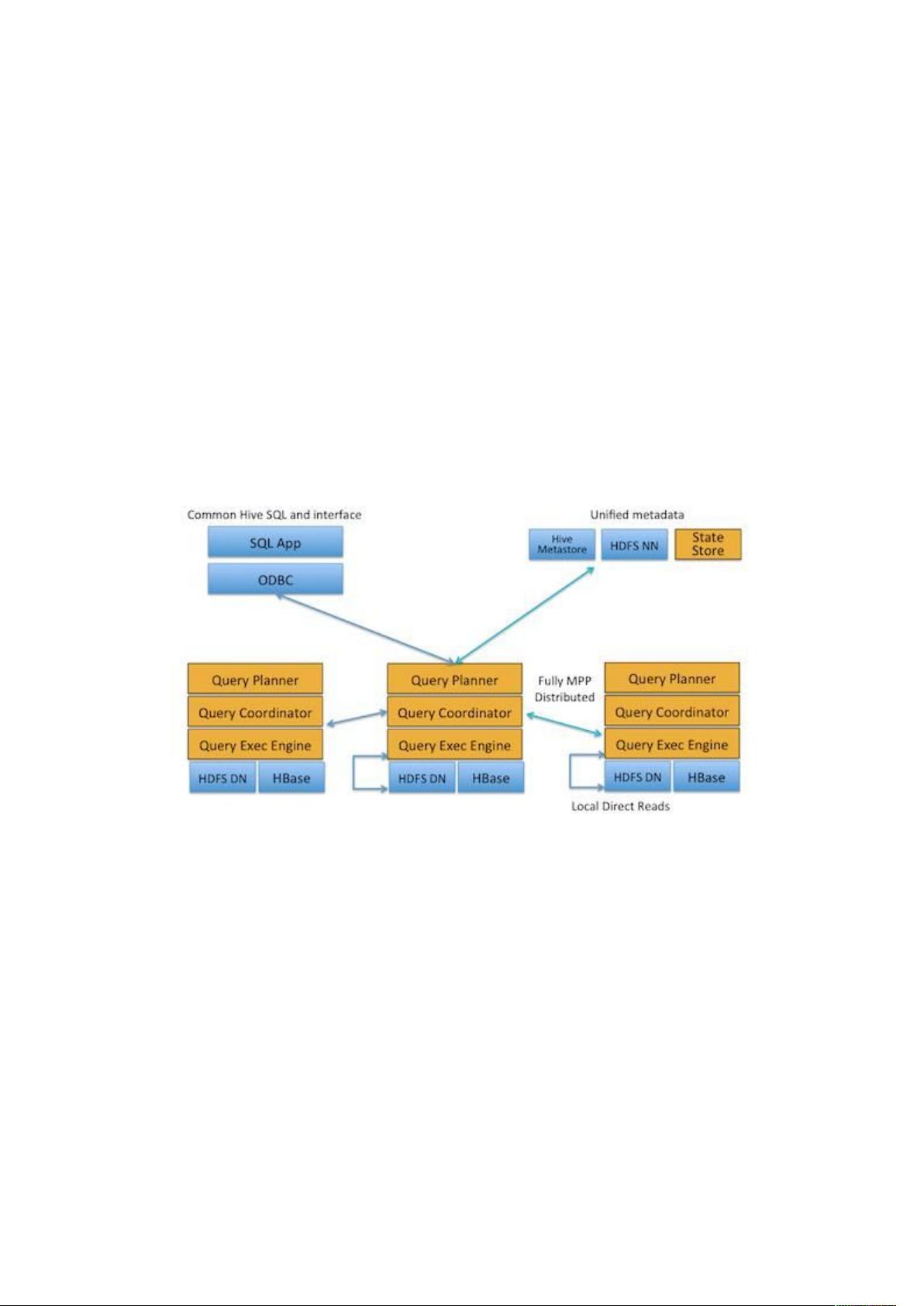
Impala 与 Hive 的比较
来源:tech.uc.cn 作者:jzou
1. Impala 架构
Impala 是 Cloudera 在受到 Google 的 Dremel 启发下开发的实时交互 SQL 大数据查询
工具,Impala 没有再使用缓慢的 Hive+MapReduce 批处理,而是通过使用与商用并行
关系数据库中类似的分布式查询引擎(由 Query Planner、Query Coordinator 和
Query Exec Engine 三部分组成),可以直接从 HDFS 或 HBase 中用 SELECT、JOIN
和统计函数查询数据,从而大大降低了延迟。其架构如图 1 所示,Impala 主要由
Impalad, State Store 和 CLI 组成。
图 1
Impalad: 与 DataNode 运行在同一节点上,由 Impalad 进程表示,它接收客户端的查
询请求(接收查询请求的 Impalad 为 Coordinator,Coordinator 通过 JNI 调用 java 前
端解释 SQL 查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的
其它 Impalad 进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给
Coordinator,由 Coordinator 返回给客户端。同时 Impalad 也与 State Store 保持连
接,用于确定哪个 Impalad 是健康和可以接受新的工作。在 Impalad 中启动三个
ThriftServer: beeswax_server(连接客户端),hs2_server(借用 Hive 元数据),
be_server(Impalad 内部使用)和一个 ImpalaServer 服务。
Impala State Store: 跟踪集群中的 Impalad 的健康状态及位置信息,由
下载后可阅读完整内容,剩余7页未读,立即下载
2018-06-21 上传
2016-05-09 上传
2022-08-08 上传
2018-05-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

董的一亩四分地
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
