
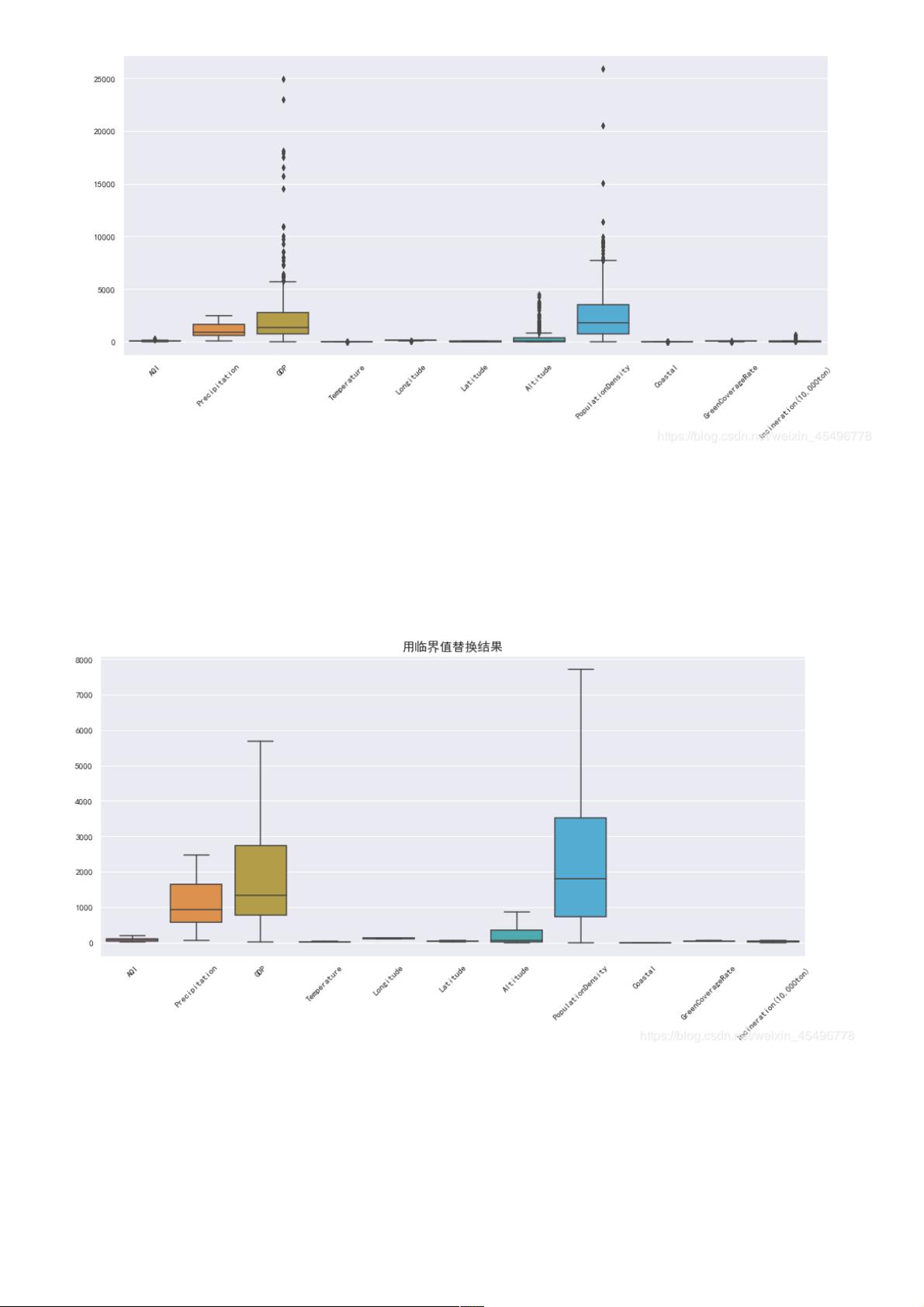
统一用临界值替换异常值统一用临界值替换异常值
for i in data:
#对数据集的每列循环
#循环 的 i 是列名称
if pd.api.types.is_numeric_dtype(data[i]):
#判断是否是数值型数据
descr = data[i].describe()#描述性统计。
IQR = descr.loc["75%"] - descr.loc["25%"] upper = descr.loc["75%"] + 1.5 * IQR
lower = descr.loc["25%"] - 1.5 * IQR
#对异常值进行处理 。填充临界值
data[i][data1[i] upper] = upper
异常值处理结果异常值处理结果
3、重复值处理、重复值处理
"""查看重复值的数据行数 """
print(data1.duplicated().sum())
#查看重复的记录
# data1[data1.duplicated(keep=False)] #False指保留重复的值(保留那些值)
"""重复值的处理"""
data.drop_duplicates(inplace=True)
data.duplicated().sum()#去重后检查
二、分析二、分析
1、空气质量最好、空气质量最好/差的差的5个城市个城市
最好的最好的5个城市个城市
剩余12页未读,继续阅读















