
从从Hive迁移到迁移到SparkSQL,有赞的大数据实践,有赞的大数据实践
前言
有赞数据平台从 2017 年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量
5000 个,占离线作业数目的 55%,消耗的 cpu 资源占集群总资源的 50% 左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到
的问题以及处理经验和优化建议,包括以下方面的内容:
有赞数据平台的整体架构。
SparkSQL 在有赞的技术演进。
从 Hive 到 SparkSQL 的迁移之路。
一. 有赞数据平台介绍
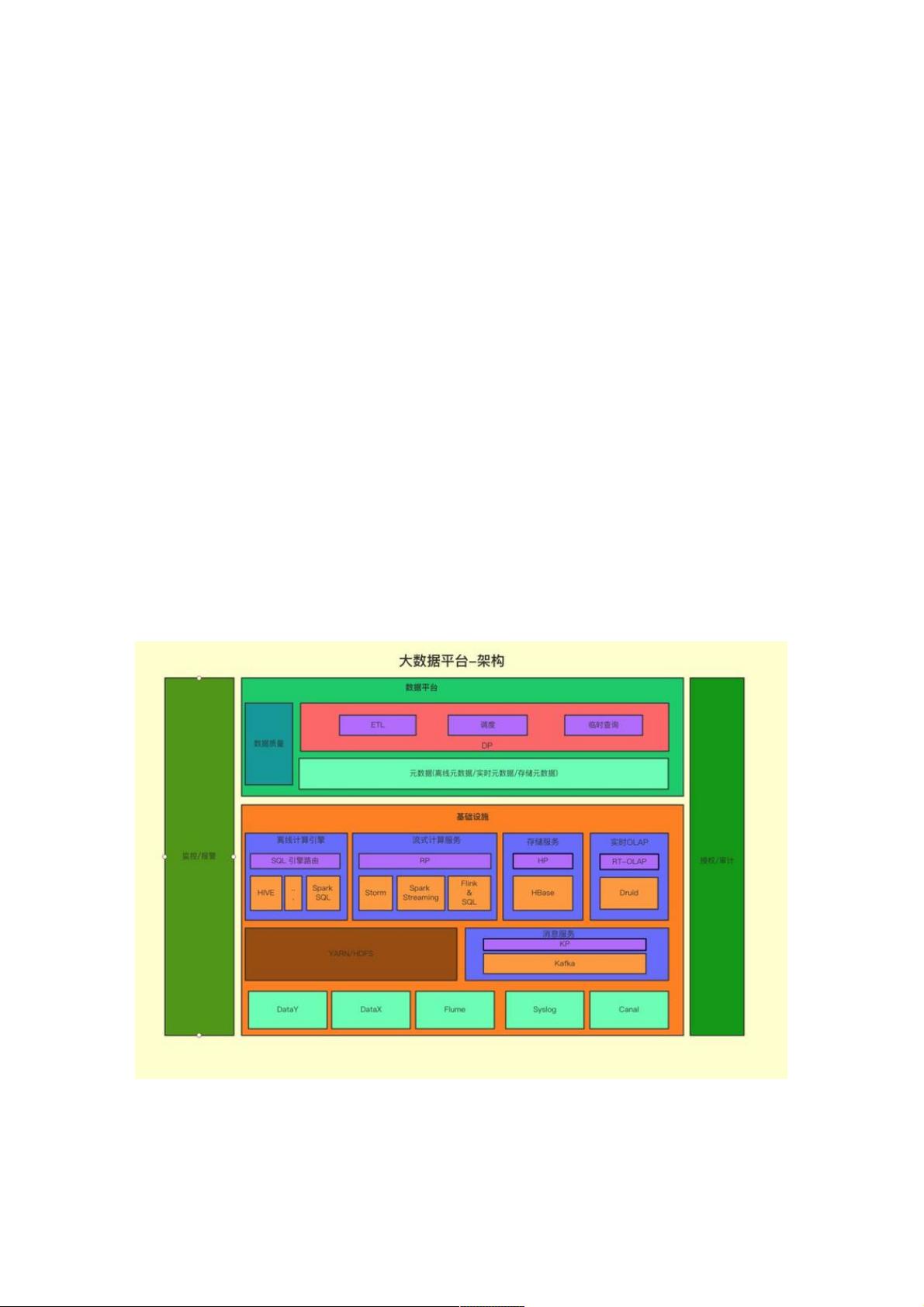
首先介绍一下有赞大数据平台总体架构:
如下图所示,底层是数据导入部分,其中 DataY 区别于开源届的全量导入导出工具 alibaba/DataX,是有赞内部研发的离线
Mysql 增量导入 Hive 的工具,把 Hive 中历史数据和当天增量部分做合并。DataX / DataY 负责将 Mysql 中的数据同步到数仓
当中,Flume 作为日志数据的主要通道,同时也是 Mysql binlog 同步到 HDFS 的管道,供 DataY 做增量合并使用。
第二层是大数据的计算框架,主要分成两部分:分布式存储计算和实时计算,实时框架目前主要支持 JStorm,Spark
Streaming 和 Flink,其中 Flink 是今年开始支持的;而分布式存储和计算框架这边,底层是 Hadoop 和 Hbase,ETL 主要使
用 Hive 和 Spark,交互查询则会使用 Spark,Presto,实时 OLAP 系统今年引入了 Druid,提供日志的聚合查询能力。
第三层是数据平台部分,数据平台是直接面对数据开发者的,包括几部分的功能,数据开发平台,包括日常使用的调度,数据
传输,数据质量系统;数据查询平台,包括 ad-hoc 查询以及元数据查询。有关有赞数据平台的详细介绍可以参考往期有赞数
据平台的博客内容。
二. SparkSQL 技术演进
从 2017 年二季度,有赞数据组的同学们开始了 SparkSQL 方面的尝试,主要的出发点是当时集群资源是瓶颈,Hive 跑任务
已经逐渐开始乏力,有些复杂的 SQL,通过 SQL 的逻辑优化达到极限,仍然需要几个小时的时间。业务数据量正在不断增
大,这些任务会影响业务对外服务的承诺。同时,随着 Spark 以及其社区的不断发展,Spark 及 Spark SQL 本身技术的不断
成熟,Spark 在技术架构和性能上都展示出 Hive 无法比拟的优势。
从开始上线提供离线任务服务,再到 Hive 任务逐渐往 SparkSQL 迁移,踩过不少坑,也填了不少坑,这里主要分两个方面介
绍,一方面是我们对 SparkSQL 可用性方面的改造以及优化,另一方面是 Hive 迁移时遇到的种种问题以及对策。

weixin_38695159
- 粉丝: 5
- 资源: 943
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 京瓷TASKalfa系列维修手册:安全与操作指南
- 小波变换在视频压缩中的应用
- Microsoft OfficeXP详解:WordXP、ExcelXP和PowerPointXP
- 雀巢在线媒介投放策划:门户网站与广告效果分析
- 用友NC-V56供应链功能升级详解(84页)
- 计算机病毒与防御策略探索
- 企业网NAT技术实践:2022年部署互联网出口策略
- 软件测试面试必备:概念、原则与常见问题解析
- 2022年Windows IIS服务器内外网配置详解与Serv-U FTP服务器安装
- 中国联通:企业级ICT转型与创新实践
- C#图形图像编程深入解析:GDI+与多媒体应用
- Xilinx AXI Interconnect v2.1用户指南
- DIY编程电缆全攻略:接口类型与自制指南
- 电脑维护与硬盘数据恢复指南
- 计算机网络技术专业剖析:人才培养与改革
- 量化多因子指数增强策略:微观视角的实证分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


