HTTP Redirection Implementation in LabVIEW
发布时间: 2024-09-14 21:34:21 阅读量: 18 订阅数: 24 
# 1. Introduction
## 1.1 What is HTTP Redirection
HTTP redirection is a mechanism by which a web server returns a specific status code to instruct the browser to redirect to another URL. When a user accesses a webpage, there might be reasons to redirect them to a different page. In such cases, the server sends back a corresponding redirection status code, indicating to the browser which new URL it should navigate to.
## 1.2 Why Implement HTTP Redirection in LabVIEW
In real-world engineering applications, there are times when we need to execute HTTP redirection programmatically to achieve specific navigation logic in network communication. LabVIEW, as a graphical programming environment, offers an intuitive and user-friendly approach to implementing HTTP communications. Thus, implementing HTTP redirection in LabVIEW can provide a convenient development experience.
## 1.3 Objectives and Significance
This article aims to introduce how to implement HTTP redirection in LabVIEW. Through an in-depth discussion of HTTP fundamentals, implementation methods of HTTP communications in LabVIEW, the principles of HTTP redirection, and hands-on examples, the reader will gain an understanding of the HTTP redirection mechanism and master the techniques for implementing HTTP redirection in LabVIEW, enabling flexible application of this technology in practical scenarios.
# 2. A Review of HTTP Fundamentals
HTTP (Hypertext Transfer Protocol) is an application-layer protocol for transferring hypertext. It is the foundation of the Web. In this chapter, we will review the basics of HTTP, including the fundamental principles of HTTP requests and responses, the meanings of HTTP status codes, and redirection-specific HTTP status codes.
# 3. Implementing HTTP Communications in LabVIEW
In this chap

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深度剖析ECharts地图:自定义数值显示的10个实用技巧
# 摘要
ECharts地图的数值显示功能是实现数据可视化的重要组成部分。本文首先概述了ECharts地图的理论基础,并讨论了自定义数值显示的设计原则。在此基础上,本文详细介绍了实现自定义数值显示的各项技巧,包括标签和颜色的定制化方法以及交互功能的增强。进一步探讨了高级数值显示技术的应用,如视觉效果的丰富化、复杂数据的可视化处理和用户交互方式。为了提升性能,
西门子M430调试流程大公开

# 摘要
本文对西门子M430变频器进行了全面的介绍,涵盖了安装、接线、参数设置、调试步骤以及维护和故障处理等方面。首先,介绍了M430变频器的基本概念和安装要求,强调了正确的接线和安全措施的重要性。随后,详细说明了参数设置的步骤、方法和故障诊断技术。本文进一步探讨了调试变频器的最佳实践
【无线网络新手速成】:H3C室外AP安装与配置的5大必知

# 摘要
本文旨在系统介绍室外无线接入点(AP)的安装、配置和维护知识,特别是在H3C品牌设备的实际应用方面。首先,本文为读者提供了无线网络和H3C室外AP设备的基础知识。随后,详细阐述了室外AP安装前的准备工作,包括网络环境评估与规划,以及硬件安装环境的搭建。紧接着,本文逐步讲述了室外AP的安装步骤,并在进阶技巧章节中提供了高级无线功能配置和性能优化的实用建议。最后,文章强调了室外AP管理与维护的重要
高效代码审查与合并:IDEA Git操作的最佳实践秘籍
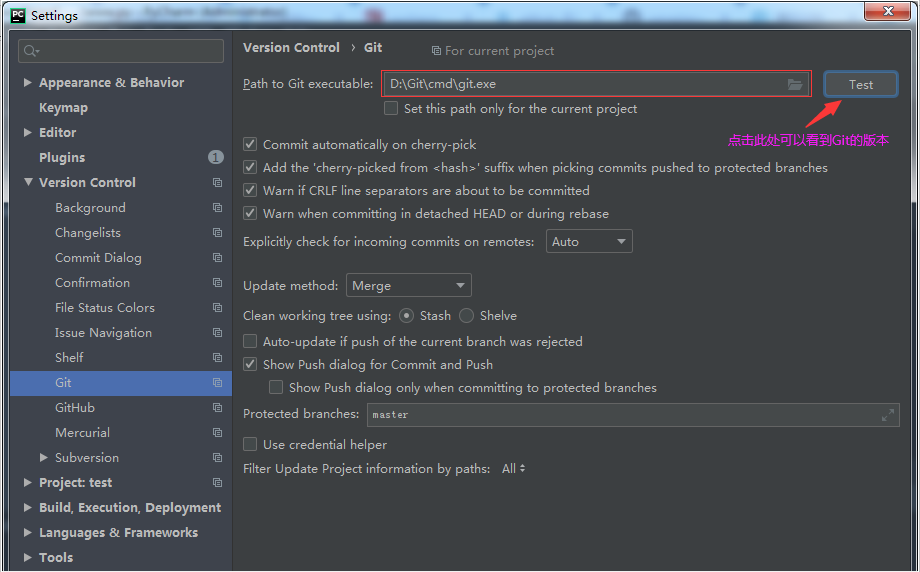
# 摘要
本文首先概述了Git作为版本控制工具的基础知识,然后详细介绍了在IntelliJ IDEA环境下Git的集成与配置方法,包括环境设置、界面与功能、分支管理等。接下来,文中探讨了高效代码审查流程的实施,涵盖审查准备、差
【TiDB技术创新】:新一代分布式数据库的优势与应用
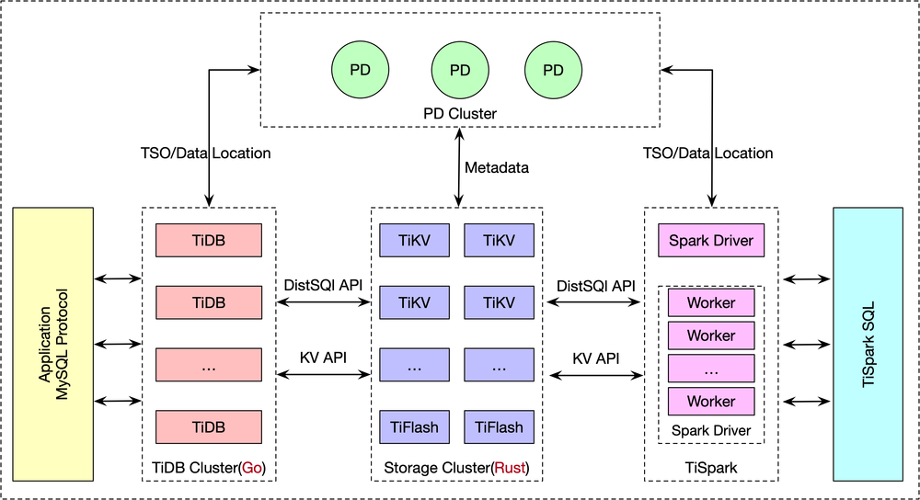
# 摘要
分布式数据库作为一种高效、可扩展的数据管理解决方案,在现代数据密集型应用中扮演着重要角色。本文首先介绍了分布式数据库的基本概念和原理,为读者提供了对分布式技术的基础理解。接着,详细解析了TiDB的创新架构设计及其关键技术特性,如存储和计算分离、HTAP能力、云原生支持和多版本并发控制(MVCC),并探讨了性能优化的各个方面。文章进一步通过多个行业
浪潮服务器RAID数据恢复:专家应急处理与预防策略
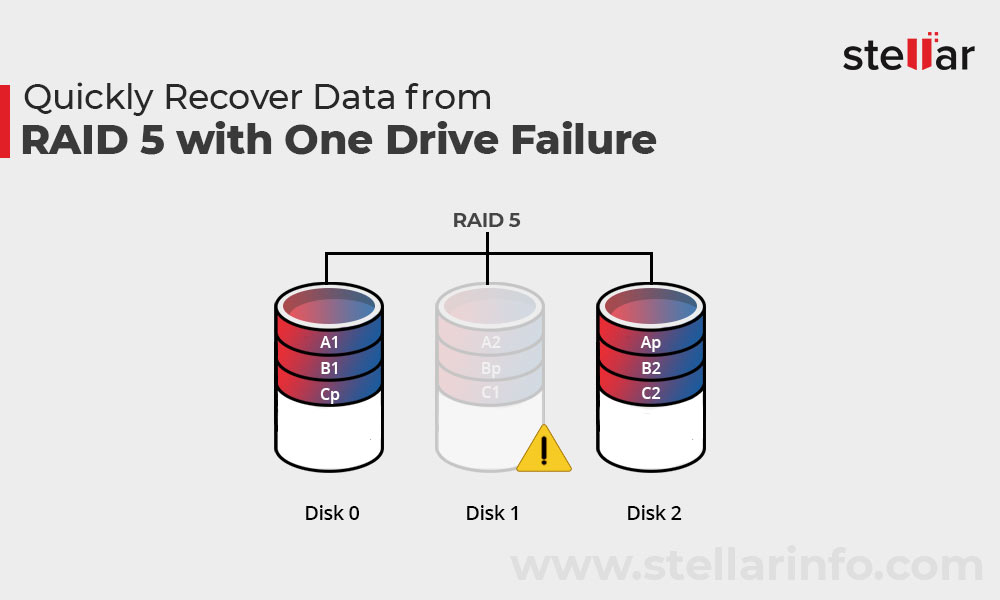
# 摘要
RAID技术作为一种常用的数据存储方案,提供了数据冗余与性能提升,但同时也存在数据丢失的风险。本文详细阐述了RAID技术的概念、配置步骤以及数据恢复的理论基础,并探讨了浪潮服务器RAID配置的具体方法。此外,本文还介绍了RAID数据恢复专家的应急处理流程、预防策略与系统维护的要点,通过分析浪潮服务器RA
【音频处理在CEA-861-G标准下的挑战】:同步与视频流的最佳实践

# 摘要
本文首先概述了CEA-861-G标准,随后深入探讨音频处理的基础理论,包括音频信号的数字化和压缩技术,以及音频格式的兼容性问题和同步机制。接着,文章详细介绍了在CEA-861-G标准下音频处理实践,包括音频在视频流中的应用、处理工具与平台的选取,以及音频质量的控制与测试。最后,本文分析了音频处理技术在CEA-
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )