揭秘Pandas数据清洗秘籍:让脏数据无处遁形,分析更精准
发布时间: 2024-07-20 21:57:33 阅读量: 35 订阅数: 43 
# 1. Pandas数据清洗概述**
数据清洗是数据分析和机器学习中的关键步骤,它涉及识别、纠正和处理数据中的错误和不一致。Pandas是Python中用于数据操作和分析的流行库,它提供了广泛的数据清洗功能。
在本章中,我们将介绍Pandas数据清洗的基础知识,包括:
* 数据清洗的重要性及其在数据分析中的作用
* Pandas库中可用的数据清洗功能
* 数据清洗的常见步骤和技术
# 2. 数据清洗基础
### 2.1 数据类型检测和转换
**数据类型检测**
Pandas提供了`dtypes`属性来检测数据框中每列的数据类型:
```python
import pandas as pd
df = pd.DataFrame({'name': ['John', 'Mary', 'Bob'], 'age': [20, 25, 30]})
print(df.dtypes)
```
输出:
```
name object
age int64
dtype: object
```
**数据类型转换**
Pandas提供了`astype()`方法来转换数据类型:
```python
df['age'] = df['age'].astype(float)
print(df.dtypes)
```
输出:
```
name object
age float64
dtype: object
```
### 2.2 缺失值处理
**检测缺失值**
Pandas提供了`isnull()`和`notnull()`方法来检测缺失值:
```python
print(df.isnull())
print(df.notnull())
```
输出:
```
name age
0 False False
1 False False
2 False False
name age
0 True True
1 True True
2 True True
```
**处理缺失值**
* **删除缺失值:**`dropna()`方法可以删除包含缺失值的整个行或列。
* **填充缺失值:**`fillna()`方法可以填充缺失值,可以使用指定值、平均值或中位数等。
```python
# 删除缺失值
df.dropna(inplace=True)
# 填充缺失值
df['age'].fillna(df['age'].mean(), inplace=True)
```
### 2.3 重复数据处理
**检测重复数据**
Pandas提供了`duplicated()`方法来检测重复数据:
```python
print(df.duplicated())
```
输出:
```
False False False
dtype: bool
```
**删除重复数据**
Pandas提供了`drop_duplicates()`方法来删除重复数据:
```python
df.drop_duplicates(inplace=True)
```
# 3. 高级数据清洗技术
### 3.1 正则表达式清洗
正则表达式(Regex)是一种强大的模式匹配语言,广泛用于数据清洗中。它允许您使用模式来搜索和替换字符串中的文本。
#### 正则表达式语法
正则表达式语法包括以下元素:
- **字符类:**匹配特定字符集,如 `[abc]`、`[0-9]`
- **元字符:**具有特殊含义的字符,如 `.`(匹配任何字符)、`*`(匹配零次或多次)
- **量词:**指定匹配次数,如 `{3}`(匹配 3 次)、`+`(匹配一次或多次)
- **分组:**使用圆括号将模式分组,以便以后引用
#### 正则表达式清洗示例
以下示例演示如何使用正则表达式清洗数据:
```python
import pandas as pd
# 创建 DataFrame
df = pd.DataFrame({'name': ['John Doe', 'Jane Doe', 'John Smith', 'Jane Smith'],
'email': ['john.doe@example.com', 'jane.doe@example.com', 'john.smith@example.com', 'jane.smith@example.com']})
# 提取姓氏
df['last_name'] = df['name'].str.extract(r'(\w+)\s+(\w+)')
# 替换电子邮件中的点
df['email'] = df['email'].str.replace(r'\.', '_')
```
**代码逻辑分析:**
- `df['name'].str.extract(r'(\w+)\s+(\w+)')`:使用正则表达式模式 `(\w+)\s+(\w+)` 提取姓氏。`(\w+)` 匹配一个或多个单词字符,`\s+` 匹配一个或多个空格字符。
- `df['email'].str.replace(r'\.', '_')`:使用正则表达式模式 `\.` 替换电子邮件中的点为下划线。
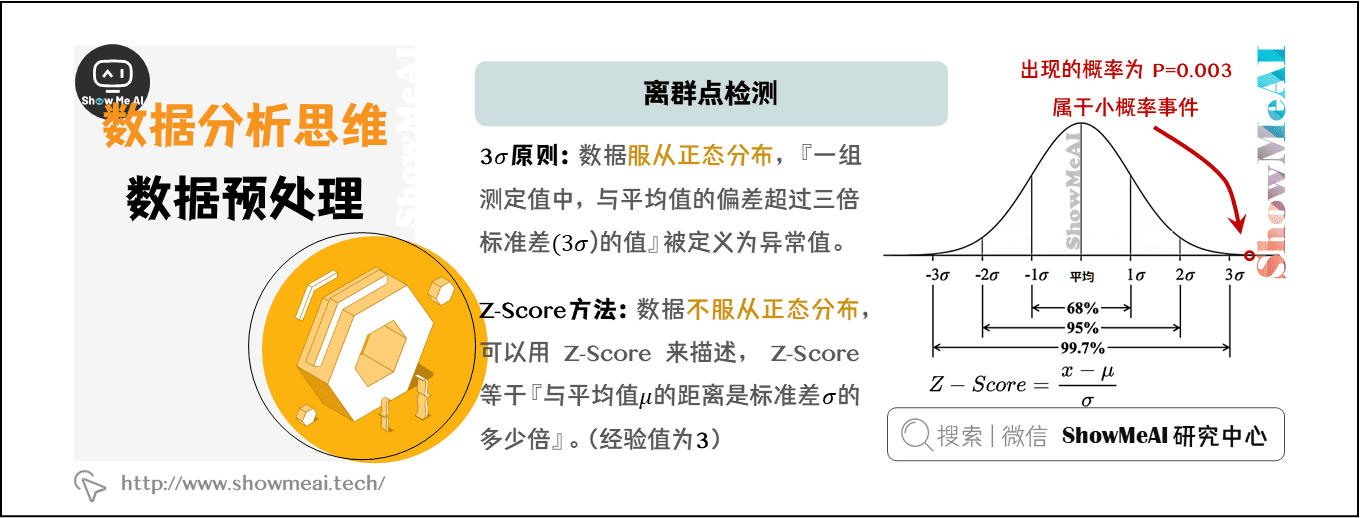
### 3.2 异常值检测和处理
异常值是与数据集中的其他数据点明显不同的数据点。它们可能由数据输入错误、测量错误或其他原因引起。检测和处理异常值对于确保数据的准确性和可靠性至关重要。
#### 异常值检测方法
常见的异常值检测方法包括:
- **统计方法:**使用标准差或四分位数范围等统计指标识别异常值
- **机器学习算法:**使用孤立森林或局部异常因子检测算法检测异常值
#### 异常值处理技术
异常值处理技术包括:
- **删除:**从数据集中删除异常值
- **替换:**用中位数或平均值等统计指标替换异常值
- **转换:**将异常值转换为更接近正常范围的值
#### 异常值检测和处理示例
以下示例演示如何检测和处理异常值:
```python
import pandas as pd
import numpy as np
# 创建 DataFrame
df = pd.DataFrame({'age': [20, 25, 30, 35, 40, 50, 100]})
# 检测异常值(年龄超过 60)
outliers = df[df['age'] > 60]
# 替换异常值
df['age'] = df['age'].replace(outliers['age'], np.nan)
```
**代码逻辑分析:**
- `df[df['age'] > 60]`:使用布尔索引检测年龄超过 60 的异常值。
- `df['age'].replace(outliers['age'], np.nan)`:用 `np.nan` 替换异常值。
### 3.3 数据标准化和归一化
数据标准化和归一化是将数据转换为具有更一致范围和分布的技术。这对于机器学习和数据分析至关重要,因为它可以提高模型的性能和结果的可比性。
#### 数据标准化
数据标准化通过减去均值并除以标准差将数据转换为均值为 0、标准差为 1 的分布。
#### 数据归一化
数据归一化通过将数据转换为 0 到 1 之间的范围,使数据具有相同的范围。
#### 标准化和归一化示例
以下示例演示如何对数据进行标准化和归一化:
```python
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 创建 DataFrame
df = pd.DataFrame({'age': [20, 25, 30, 35, 40, 50],
'height': [1.70, 1.75, 1.80, 1.85, 1.90, 1.95]})
# 标准化年龄
scaler = StandardScaler()
df['age_std'] = scaler.fit_transform(df['age'].values.reshape(-1, 1))
# 归一化身高
scaler = MinMaxScaler()
df['height_norm'] = scaler.fit_transform(df['height'].values.reshape(-1, 1))
```
**代码逻辑分析:**
- `scaler.fit_transform(df['age'].values.reshape(-1, 1))`:使用 `StandardScaler` 对年龄进行标准化。`reshape(-1, 1)` 将数据转换为一维数组。
- `scaler.fit_transform(df['height'].values.reshape(-1, 1))`:使用 `MinMaxScaler` 对身高进行归一化。
# 4. Pandas数据清洗实践
### 4.1 数据导入和预处理
**数据导入**
Pandas提供多种数据导入方法,包括:
- `read_csv()`: 从CSV文件导入数据
- `read_excel()`: 从Excel文件导入数据
- `read_json()`: 从JSON文件导入数据
- `read_sql()`: 从SQL数据库导入数据
**代码块:**
```python
import pandas as pd
# 从CSV文件导入数据
df = pd.read_csv('data.csv')
# 从Excel文件导入数据
df = pd.read_excel('data.xlsx')
# 从JSON文件导入数据
df = pd.read_json('data.json')
# 从SQL数据库导入数据
df = pd.read_sql('SELECT * FROM table', 'sqlite:///data.db')
```
**参数说明:**
- `filepath`: 数据文件路径
- `index_col`: 指定索引列
- `header`: 指定表头行数
- `dtype`: 指定数据类型
**逻辑分析:**
Pandas根据文件类型自动检测数据类型,但也可以通过`dtype`参数手动指定。指定索引列可以提高数据访问效率。
**数据预处理**
数据预处理包括以下步骤:
- **数据类型转换:**将数据类型转换为适当的格式,例如将字符串转换为数字。
- **缺失值处理:**处理缺失值,例如用均值或中位数填充。
- **重复数据处理:**删除或保留重复数据。
**代码块:**
```python
# 数据类型转换
df['age'] = df['age'].astype(int)
# 缺失值处理
df['salary'].fillna(df['salary'].mean(), inplace=True)
# 重复数据处理
df.drop_duplicates(inplace=True)
```
**参数说明:**
- `astype()`: 指定目标数据类型
- `fillna()`: 指定填充值
- `inplace`: 直接修改数据框
**逻辑分析:**
数据类型转换确保数据的一致性。缺失值处理防止数据分析中的错误。重复数据处理避免冗余和数据偏差。
### 4.2 数据清洗案例分析
**案例:客户数据清洗**
**任务:**清洗客户数据,包括:
- 删除无效的电子邮件地址
- 标准化姓名格式
- 处理缺失的电话号码
**代码块:**
```python
# 删除无效的电子邮件地址
df = df[df['email'].str.contains('@')]
# 标准化姓名格式
df['name'] = df['name'].str.title()
# 处理缺失的电话号码
df['phone'].fillna('N/A', inplace=True)
```
**参数说明:**
- `str.contains()`: 检查字符串是否包含指定子字符串
- `str.title()`: 将字符串转换为首字母大写格式
**逻辑分析:**
通过正则表达式删除无效的电子邮件地址。使用`str.title()`标准化姓名格式,确保一致性。用`N/A`填充缺失的电话号码,表示不可用。
### 4.3 数据清洗自动化
**自动化脚本**
Pandas提供自动化数据清洗功能,例如:
- **`apply()`方法:**对数据框中的每一行或列应用函数。
- **`pipe()`方法:**将数据框作为管道传递给一组函数。
**代码块:**
```python
# 使用apply()方法标准化姓名格式
df['name'] = df['name'].apply(lambda x: x.title())
# 使用pipe()方法自动化数据清洗
df.pipe(lambda df: df.dropna()).pipe(lambda df: df.drop_duplicates())
```
**参数说明:**
- `apply()`: 应用指定函数
- `pipe()`: 将数据框传递给函数管道
**逻辑分析:**
`apply()`方法允许对数据框中的每个元素执行自定义操作。`pipe()`方法提供了一种简便的方法来链接多个数据清洗操作。
# 5.1 数据清洗流程优化
数据清洗流程优化旨在提高数据清洗效率和准确性。以下是一些优化策略:
- **自动化数据清洗:**使用Pandas内置函数或第三方库自动化重复性任务,例如缺失值处理、数据类型转换和重复数据删除。
- **并行处理:**利用多核处理器并行执行数据清洗任务,以缩短处理时间。
- **数据验证:**在数据清洗过程中进行数据验证,以确保清洗后的数据满足预期要求。
- **单元测试:**编写单元测试来验证数据清洗函数的正确性,确保数据清洗流程的稳定性。
- **性能优化:**通过优化数据结构、使用索引和避免不必要的计算来提高数据清洗性能。
## 5.2 数据清洗工具选择
选择合适的工具对于高效的数据清洗至关重要。以下是一些考虑因素:
- **功能性:**评估工具是否提供所需的数据清洗功能,例如缺失值处理、重复数据删除和数据标准化。
- **易用性:**选择易于使用和理解的工具,以减少学习曲线和提高生产率。
- **可扩展性:**考虑工具的可扩展性,以处理大型数据集和复杂的数据清洗任务。
- **集成性:**评估工具是否与其他数据处理工具和平台集成,以实现无缝的工作流。
- **成本:**考虑工具的成本,包括许可证费用、支持费用和维护成本。
## 5.3 数据清洗质量评估
数据清洗质量评估对于确保清洗后的数据满足预期要求至关重要。以下是一些评估方法:
- **数据完整性:**验证清洗后的数据是否完整,没有缺失值或重复值。
- **数据准确性:**检查清洗后的数据是否准确,没有错误或异常值。
- **数据一致性:**确保清洗后的数据与其他相关数据集一致,没有矛盾或冲突。
- **数据格式:**验证清洗后的数据是否符合预期的格式和数据类型。
- **数据可视化:**使用数据可视化工具,例如直方图和散点图,检查清洗后的数据分布和模式,以识别潜在问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Pandas库入门宝典》专栏是数据处理领域的权威指南,涵盖了从基础知识到高级技巧的全面内容。专栏以循序渐进的方式介绍了Pandas库,从数据合并、分组分析、可视化到数据类型转换、内存管理和性能优化。通过深入浅出的讲解和丰富的实战案例,专栏帮助读者掌握Pandas库的精髓,提升数据处理能力。无论是数据分析新手还是经验丰富的从业者,本专栏都提供了宝贵的知识和实践指导,助力读者在数据处理领域取得成功。
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
动态规划的R语言实现:solnp包的实用指南
# 1. 动态规划简介
## 1.1 动态规划的历史和概念
动态规划(Dynamic Programming,简称DP)是一种数学规划方法,由美国数学家理查德·贝尔曼(Richard Bellman)于20世纪50年代初提出。它用于求解多阶段决策过程问题,将复杂问题分解为一系列简单的子问题,通过解决子问题并存储其结果来避免重复计算,从而显著提高算法效率。DP适用于具有重叠子问题和最优子
【R语言Web开发实战】:shiny包交互式应用构建
# 1. Shiny包简介与安装配置
## 1.1 Shiny概述
Shiny是R语言的一个强大包,主要用于构建交互式Web应用程序。它允许R开发者利用其丰富的数据处理能力,快速创建响应用户操作的动态界面。Shiny极大地简化了Web应用的开发过程,无需深入了解HTML、CSS或JavaScript,只需专注于R代码即可。
## 1.2 安装Shiny包
要在R环境中安装Shiny包,您只需要在R控制台输入以下命令:
```R
install.p
constrOptim在生物统计学中的应用:R语言中的实践案例,深入分析

# 1. constrOptim在生物统计学中的基础概念
在生物统计学领域中,优化问题无处不在,从基因数据分析到药物剂量设计,从疾病风险评估到治疗方案制定。这些问题往往需要在满足一定条件的前提下,寻找最优解。constrOptim函数作为R语言中用于解决约束优化问题的一个重要工具,它的作用和重
【R语言高性能计算】:并行计算框架与应用的前沿探索

# 1. R语言简介及其计算能力
## 简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。自1993年问世以来,它已经成为数据科学领域内最流行的工具之一,尤其是受到统计学家和研究人员的青睐。
## 计算能力
R语言拥有强大的计算能力,特别是在处理大量数据集和进行复杂统计分析
【R语言跨语言交互指南】:在R中融合Python等语言的强大功能

# 1. R语言简介与跨语言交互的需求
## R语言简介
R语言是一种广泛使用的开源统计编程语言,它在统计分析、数据挖掘以及图形表示等领域有着显著的应用。由于其强健的社区支持和丰富的包资源,R语言在全球数据分析和科研社区中享有盛誉。
## 跨语言交互的必要性
在数据科学领域,不
【nlminb项目应用实战】:案例研究与最佳实践分享
# 1. nlminb项目概述
## 项目背景与目的
在当今高速发展的IT行业,如何优化性能、减少资源消耗并提高系统稳定性是每个项目都需要考虑的问题。nlminb项目应运而生,旨在开发一个高效的优化工具,以解决大规模非线性优化问题。项目的核心目的包括:
- 提供一个通用的非线性优化平台,支持多种算法以适应不同的应用场景。
- 为开发者提供一个易于扩展
【R语言数据包性能监控实战】:实时追踪并优化性能指标

# 1. R语言数据包性能监控的概念与重要性
在当今数据驱动的科研和工业界,R语言作为一种强大的统计分析工具,其性能的监控与优化变得至关重要。R语言数据包性能监控的目的是确保数据分析的高效性和准确性,其重要性体现在以下几个方面:
1. **提升效率**:监控能够发现数据处理过程中的低效环节,为改进算法提供依据,从而减少计算资源的浪费。
2. **保证准确性**:通过监控数据包的执行细节,可以确保数据处理的正确性
【R语言性能提速】:数据包加载速度与运行效率优化攻略(速度狂飙)
# 1. R语言性能优化概述
R语言,作为一种流行的统计分析工具,在数据科学和统计建模中发挥着重要作用。随着数据分析任务的复杂性和数据量的增加,性能优化成为了提升工作效率的关键。本章节将简要介绍R语言性能优化的基本概念,方法论,以及为什么要进行性能优化。
## 1.1 为
【数据挖掘应用案例】:alabama包在挖掘中的关键角色

# 1. 数据挖掘简介与alabama包概述
## 1.1 数据挖掘的定义和重要性
数据挖掘是一个从大量数据中提取或“挖掘”知识的过程。它使用统计、模式识别、机器学习和逻辑编程等技术,以发现数据中的有意义的信息和模式。在当今信息丰富的世界中,数据挖掘已成为各种业务决策的关键支撑技术。有效地挖掘数据可以帮助企业发现未知的关系,预测未来趋势,优化
质量控制中的Rsolnp应用:流程分析与改进的策略

# 1. 质量控制的基本概念
## 1.1 质量控制的定义与重要性
质量控制(Quality Control, QC)是确保产品或服务质量
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )