【进阶篇】Python中的自然语言处理与NLTK库应用
发布时间: 2024-06-24 12:59:00 阅读量: 85 订阅数: 108 

Python自然语言处理 NLTK 库用法入门教程【经典】
# 1. Python中的自然语言处理概述**
自然语言处理(NLP)是计算机科学的一个分支,它专注于让计算机理解、解释和生成人类语言。NLP在各种应用程序中都有应用,包括文本分类、情感分析和机器翻译。
Python是一种流行的编程语言,它提供了广泛的NLP库和工具。NLTK(自然语言工具包)是Python中用于NLP的最受欢迎的库之一。NLTK提供了一系列用于文本预处理、分词、词性标注、句法分析和语义分析的工具。
# 2. NLTK库的安装和基本操作
### 2.1 NLTK库的安装和配置
NLTK库是一个用于自然语言处理的Python库,它提供了广泛的工具和资源,用于文本预处理、分词、词性标注、句法分析、语义分析和情感分析等任务。
**安装 NLTK 库**
可以通过以下命令安装 NLTK 库:
```bash
pip install nltk
```
**配置 NLTK 库**
安装完成后,需要下载 NLTK 数据集,其中包含用于训练和评估 NLTK 模型的语料库和词典。可以通过以下命令下载数据集:
```bash
python -m nltk.downloader all
```
### 2.2 NLTK库的基本数据结构和操作
NLTK 库提供了多种数据结构和操作来处理文本数据,包括:
**文本(Text)**
Text 类表示一个文本文档,它提供了对文本进行操作的方法,例如:
```python
import nltk
text = nltk.Text("This is a sample text.")
# 获取文本中的单词列表
words = text.words
# 获取文本中的词频分布
freq_dist = nltk.FreqDist(words)
```
**语料库(Corpus)**
Corpus 类表示一组文本文档,它提供了对语料库进行操作的方法,例如:
```python
import nltk
corpus = nltk.corpus.gutenberg.raw("austen-emma.txt")
# 获取语料库中的句子列表
sentences = nltk.sent_tokenize(corpus)
# 获取语料库中的单词列表
words = nltk.word_tokenize(corpus)
```
**词典(Dictionary)**
Dictionary 类表示一个单词到其词性的映射,它提供了对词典进行操作的方法,例如:
```python
import nltk
dictionary = nltk.corpus.wordnet.synsets("computer")
# 获取单词的同义词
synonyms = [synset.name() for synset in dictionary]
# 获取单词的定义
definitions = [synset.definition() for synset in dictionary]
```
**其他数据结构和操作**
NLTK 库还提供了其他数据结构和操作,例如:
* **TreeBank:** 表示句子的树形结构。
* **TaggedCorpus:** 表示带有词性标注的语料库。
* **Collocation:** 表示单词之间的搭配关系。
* **ConditionalFreqDist:** 表示条件下的词频分布。
# 3.1 文本预处理技术
文本预处理是自然语言处理中至关重要的一步,它可以去除文本中的噪声和不相关信息,为后续的处理步骤做好准备。文本预处理技术主要包括文本清洗和文本归一化。
#### 3.1.1 文本清洗
文本清洗旨在去除文本中的各种噪声和不相关信息,例如标点符号、数字、特殊字符和停用词。停用词是一些在文本中出现频率很高但信息量较少的词语,例如“the”、“and”、“of”等。去除停用词可以减少文本的冗余信息,提高后续处理的效率。
```python
import nltk
from nltk.corpus import stopwords
text = "This is a sample text with stopwords and punctuation."
# 去除标点符号
text = text.replace(".", "").replace(",", "").replace("!", "").replace("?", "")
# 去除数字
text = text.replace("0", "").replace("1", "").replace("2", "").replace("3", "").replace("4", "").replace("5", "").replace("6", "").replace("7", "").replace("8", "").replace("9", "")
# 去除特殊字符
text = text.replace("'", "").replace("\"", "").replace("-", "").replace("_", "")
# 去除停用词
stop_words = set(stopwords.words('english'))
text = ' '.join([word for wo
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏集结了 Python 语言学习的全面基础知识,涵盖了从安装和环境配置到语言语法、数据类型、运算符、控制流、函数、模块、异常处理、面向对象编程、迭代器、装饰器、闭包、内置函数、字符串处理和正则表达式等各个方面。专栏中每一篇文章都深入浅出地讲解了 Python 的核心概念和语法规则,并提供了丰富的示例和代码片段,帮助初学者快速上手 Python 编程。通过学习本专栏,读者可以掌握 Python 的基础语法、数据结构、算法和编程技巧,为进一步深入学习 Python 奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Paddle Fluid环境搭建攻略:新手入门与常见问题解决方案

# 摘要
Paddle Fluid是由百度研发的开源深度学习平台,提供了丰富的API和灵活的模型构建方式,旨在简化深度学习应用的开发与部署。本文首先介绍了Paddle Fluid的基本概念与安装前的准备工作,接着详细阐述了安装流程、基础使用方法、实践应用案例以及性能优化技巧。通过对Paddle Fluid的系统性介绍,本文旨在指导用户快速上手并有效利用Paddle Fluid进行深度学习项
Karel编程语言解析:一步到位,从新手到专家
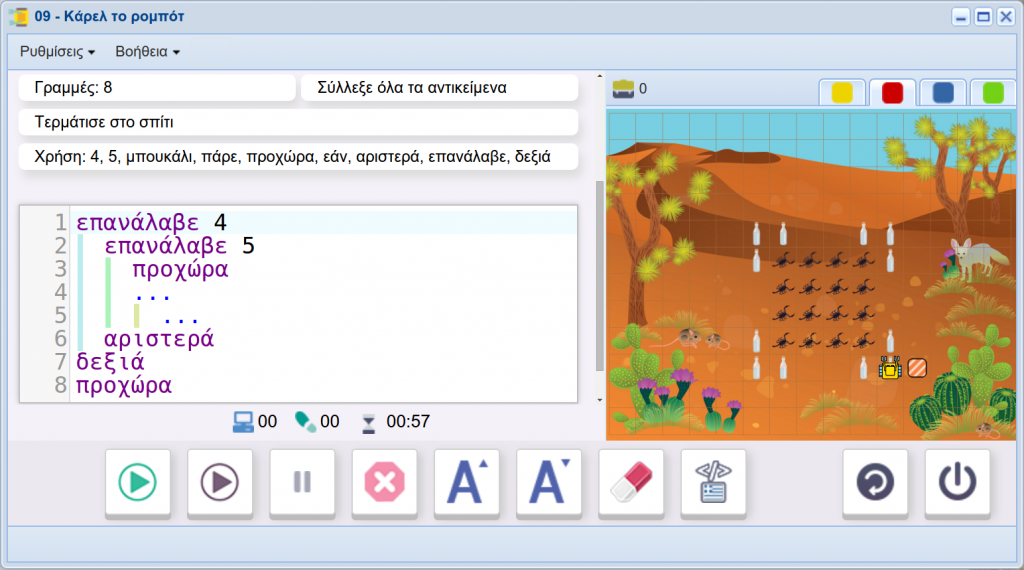
# 摘要
Karel编程语言是一门专为初学者设计的教育用语言,它以其简洁的语法和直观的设计,帮助学习者快速掌握编程基础。本文首先概述了Karel语言的基本概念和语法,包括数据结构、控制结构和数据类型等基础知识。继而深入探讨了Karel的函数、模块以及控制结构在编程实践中的应用,特别强调了异常处理和数据处理的重要性。文章进一步介绍了Karel的高级特性,如面向对象编程和并发编程,以及如何在项目实战中构建、管理和测试
【MSP430微控制器FFT算法全攻略】:一步到位掌握性能优化与实战技巧
# 摘要
本文全面探讨了MSP430微控制器上实现快速傅里叶变换(FFT)算法的理论基础与性能优化。首先介绍了FFT算法及其在信号处理和通信系统中的应用。随后,文章深入分析了FFT算法在MSP430上的数学工具和优化策略,包括内存管理和计算复杂度降低方法。此外,还讨论了性能测试与分析、实战应用案例研究以及代码解读。最
车载测试新手必学:CAPL脚本编程从入门到精通(全20篇)
# 摘要
CAPL脚本编程是用于车辆通信协议测试和仿真的一种强大工具。本文旨在为读者提供CAPL脚本的基础知识、语言构造、以及在车载测试中的应用。文章首先介绍了CAPL脚本编程基础和语言构造,包括变量、数据类型、控制结构、函数以及模块化编程。随后,章节深入探讨了CAPL脚本在模拟器与车辆通信中的应用,测试案例的设计与执行,以及异常处理和日志管理。在高级应用部分,本文详细论述
【掌握SimVision-NC Verilog】:两种模式操作技巧与高级应用揭秘
# 摘要
SimVision-NC Verilog是一种广泛应用于数字设计验证的仿真工具。本文全面介绍了SimVision-NC Verilog的基本操作技巧和高级功能,包括用户界面操作、仿真流程、代码编写与调试、高级特性如断言、覆盖率分析、
报表解读大揭秘:ADVISOR2002带你洞悉数据背后的故事

# 摘要
ADVISOR2002作为一款先进的报表工具,对数据解读提供了强大的支持。本文首先对ADVISOR2002进行了概述,并介绍了报表基础,然后深入探讨了数据解读的理论基础,包括数据与信息转化的基本原理、数据质量与管理、统计学在报表解读中的应用等。在实践章节,文章详细阐述了如何导入和整合报表数据,以及使用ADVISOR2002进行分析和解读,同时提供了成功与失败案例的剖析。文章还探讨了高级报表解读技巧与优化,如复杂问题处理和AI技术的应用。最后
【数据可视化】:Origin图表美化,坐标轴自定义与视觉传达技巧

# 摘要
数据可视化是将复杂数据信息转化为图形和图表的过程,以增强信息的可理解性和吸引力。本文从数据可视化的基础知识讲起,深入介绍Origin软件的使用,包括其操作界面、数据输入与管理、图表的创建与编辑,以及数据导入和预览技巧。随后,文章详细探讨了坐标轴的自定义技巧,包括格式化设置、尺度变换、单位转换和对数坐标的特性。接着,文章强调了提升图表视觉效果的重要性,介绍颜色与图
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )