【基础】Python的安装方法及环境配置指南
发布时间: 2024-06-24 10:34:32 阅读量: 70 订阅数: 122 
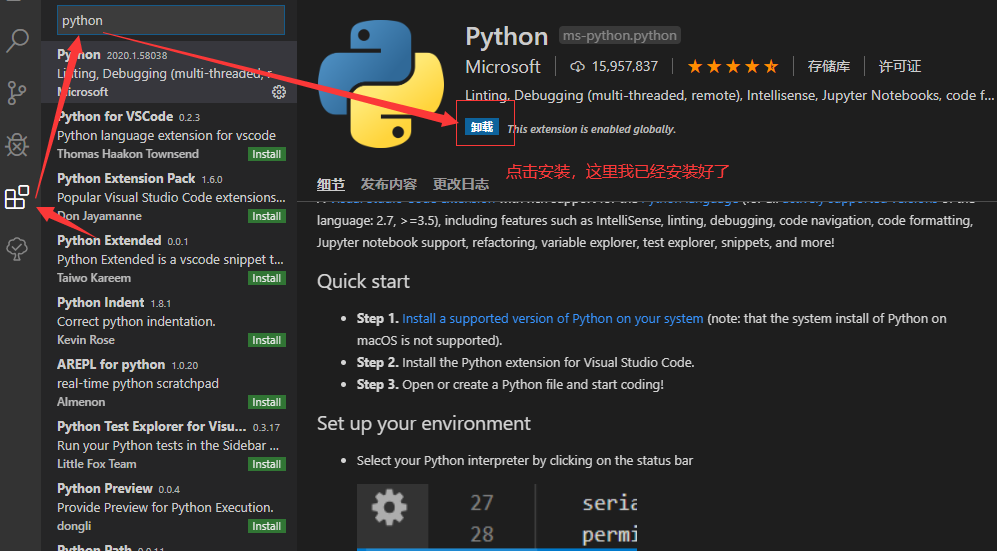
# 2.1 Python解释器安装
Python解释器是运行Python程序必备的环境,安装解释器是使用Python的第一步。不同的操作系统有不同的安装方式,下面分别介绍。
### 2.1.1 Windows系统安装
1. 访问Python官方网站(https://www.python.org/downloads/)下载Windows安装程序。
2. 双击安装程序,按照提示进行安装。
3. 安装完成后,在命令提示符中输入`python --version`命令,查看是否成功安装。
# 2. Python环境配置
Python环境配置是Python开发的基础,它决定了Python的运行环境和可用的工具。本章节将介绍Python解释器的安装和环境变量配置,为后续的Python开发做好准备。
### 2.1 Python解释器安装
Python解释器是执行Python代码的程序,它将Python代码翻译成机器可执行的指令。不同操作系统需要不同的安装方式。
#### 2.1.1 Windows系统安装
**步骤:**
1. 访问Python官方网站(https://www.python.org/downloads/)下载适用于Windows系统的Python安装程序。
2. 运行安装程序,选择自定义安装。
3. 勾选"将Python添加到PATH"选项,以便在命令行中直接使用Python命令。
4. 完成安装。
#### 2.1.2 Linux系统安装
**步骤:**
1. 使用包管理器(如apt、yum)安装Python:
```
sudo apt install python3 # Ubuntu/Debian
sudo yum install python3 # CentOS/Red Hat
```
2. 验证安装:
```
python3 --version
```
#### 2.1.3 macOS系统安装
**步骤:**
1. 使用Homebrew安装Python:
```
brew install python
```
2. 验证安装:
```
python3 --version
```
### 2.2 Python环境变量配置
环境变量告诉操作系统Python解释器的路径,以便在命令行中使用Python命令。
#### 2.2.1 Windows系统配置
**步骤:**
1. 右键点击"此电脑",选择"属性"。
2. 点击"高级系统设置",在"环境变量"中找到"Path"变量。
3. 点击"编辑",在变量值末尾添加Python解释器的路径(例如:C:\Python310)。
4. 点击"确定"保存更改。
#### 2.2.2 Linux系统配置
**步骤:**
1. 编辑`.bashrc`文件:
```
nano ~/.bashrc
```
2. 在文件末尾添加以下行:
```
export PATH=$PATH:/usr/local/bin/python3
```
3. 保存并退出文件。
4. 刷新环境变量:
```
source ~/.bashrc
```
#### 2.2.3 macOS系统配置
**步骤:**
1. 编辑`.zshrc`文件:
```
nano ~/.zshrc
```
2. 在文件末尾添加以下行:
```
export PATH=$PATH:/usr/local/bin/python3
```
3. 保存并退出文件。
4. 刷新环境变量:
```
source ~/.zshrc
```
# 3.1 数据类型
Python是一门动态类型语言,这意味着变量在运行时可以存储不同类型的数据。Python支持多种内置数据类型,包括数值类型、字符串类型、列表类型和字典类型。
#### 3.1.1 数值类型
数值类型用于表示数字,包括整数、浮点数和复数。
- 整数(int):表示没有小数部分的整数,例如:10、-5
- 浮点数(float):表示带小数部分的数字,例如:3.14、-1.23
- 复数(complex):表示具有实部和虚部的数字,例如:1+2j、3-4j
#### 3.1.2 字符串类型
字符串类型用于表示文本数据,由单引号(')或双引号(")括起来。字符串可以包含字母、数字、特殊字符和转义序列。
- 转义序列:用于表示特殊字符,例如:
- \n:换行符
- \t:制表符
- \': 单引号
- \": 双引号
#### 3.1.3 列表类型
列表类型用于存储有序的数据集合,元素可以是任何类型。列表使用方括号([])表示,元素之间用逗号(,)分隔。
- 创建列表:```python
my_list = [1, 2.5, 'Hello', True]
```
- 访问元素:```python
print(my_list[0]) # 输出:1
```
- 修改元素:```python
my_list[2] = 'World'
```
#### 3.1.4 字典类型
字典类型用于存储键值对的集合,其中键是唯一的,值可以是任何类型。字典使用大括号({})表示,键值对之间用冒号(:)分隔。
- 创建字典:```python
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
```
- 访问值:```python
print(my_dict['name']) # 输出:John
```
- 添加键值对:```python
my_dict['email'] = 'john@example.com'
```
# 4. Python进阶语法
### 4.1 函数
#### 4.1.1 函数定义
在Python中,使用`def`关键字定义函数。函数定义的语法如下:
```python
def function_name(parameters):
"""函数描述"""
# 函数体
```
* `function_name`:函数名称,遵循Python变量命名规范。
* `parameters`:函数参数,可以有多个,用逗号分隔。
* `"""函数描述"""`:函数描述,使用三引号包裹,可省略。
* `函数体`:函数执行的代码块,缩进表示代码块的开始和结束。
**示例:**
```python
def greet(name):
"""向指定名称的人打招呼"""
print(f"Hello, {name}!")
```
#### 4.1.2 函数调用
使用函数名称和括号调用函数。括号内可以传递实际参数,与函数定义中的参数一一对应。
```python
greet("John") # 输出:"Hello, John!"
```
#### 4.1.3 函数参数传递
函数参数传递有三种方式:
* **位置参数:**按照参数顺序传递,与函数定义中的参数位置对应。
* **关键字参数:**使用参数名传递,可以改变参数传递顺序。
* **默认参数:**在函数定义时指定默认值,如果调用时不传递参数,则使用默认值。
**示例:**
```python
def calculate_area(length, width, unit="cm"):
"""计算矩形的面积"""
area = length * width
return f"{area} {unit}"
print(calculate_area(5, 10)) # 输出:"50 cm"
print(calculate_area(5, 10, "m")) # 输出:"50 m"
```
### 4.2 类和对象
#### 4.2.1 类定义
在Python中,使用`class`关键字定义类。类定义的语法如下:
```python
class ClassName:
"""类描述"""
# 类属性
# 构造函数
def __init__(self, parameters):
"""构造函数描述"""
# 实例属性
# 实例方法
```
* `ClassName`:类名称,遵循Python变量命名规范。
* `"""类描述"""`:类描述,使用三引号包裹,可省略。
* `类属性`:属于类的属性,所有实例共享。
* `__init__()`:构造函数,在创建实例时自动调用,用于初始化实例属性。
* `实例属性`:属于实例的属性,每个实例独立拥有。
* `实例方法`:属于实例的方法,可以操作实例属性。
**示例:**
```python
class Person:
"""表示一个人的类"""
species = "Homo sapiens" # 类属性
def __init__(self, name, age):
"""构造函数"""
self.name = name # 实例属性
self.age = age # 实例属性
```
#### 4.2.2 对象创建
使用`Class()`语法创建类实例。
```python
person = Person("John", 30)
```
#### 4.2.3 对象方法
对象方法是属于实例的方法,可以通过实例调用。
```python
person.get_name() # 调用实例方法
```
### 4.3 模块和包
#### 4.3.1 模块导入
模块是包含相关函数、类和变量的文件。使用`import`语句导入模块。
```python
import module_name
```
**示例:**
```python
import math
print(math.pi) # 输出:3.141592653589793
```
#### 4.3.2 包管理
包是一组相关的模块的集合。使用`import`语句导入包,然后使用点号访问包中的模块。
```python
import package_name.module_name
```
**示例:**
```python
import numpy as np
print(np.array([1, 2, 3])) # 输出:[1 2 3]
```
# 5.1 文件操作
### 5.1.1 文件读写
**读文件**
```python
with open('file.txt', 'r') as f:
content = f.read()
```
**写文件**
```python
with open('file.txt', 'w') as f:
f.write('Hello, world!')
```
**追加文件**
```python
with open('file.txt', 'a') as f:
f.write('Hello, world!')
```
### 5.1.2 文件路径操作
**获取文件路径**
```python
import os
file_path = os.path.abspath('file.txt')
```
**获取文件目录**
```python
file_dir = os.path.dirname(file_path)
```
**获取文件扩展名**
```python
file_ext = os.path.splitext(file_path)[1]
```
### 5.1.3 文件权限管理
**获取文件权限**
```python
import stat
file_mode = os.stat('file.txt').st_mode
```
**设置文件权限**
```python
os.chmod('file.txt', 0o755)
```
**转换权限模式**
```python
mode = stat.S_IRUSR | stat.S_IWUSR | stat.S_IRGRP | stat.S_IROTH
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏集结了 Python 语言学习的全面基础知识,涵盖了从安装和环境配置到语言语法、数据类型、运算符、控制流、函数、模块、异常处理、面向对象编程、迭代器、装饰器、闭包、内置函数、字符串处理和正则表达式等各个方面。专栏中每一篇文章都深入浅出地讲解了 Python 的核心概念和语法规则,并提供了丰富的示例和代码片段,帮助初学者快速上手 Python 编程。通过学习本专栏,读者可以掌握 Python 的基础语法、数据结构、算法和编程技巧,为进一步深入学习 Python 奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【科大讯飞语音识别:二次开发的6大技巧】:打造个性化交互体验
# 摘要
科大讯飞作为领先的语音识别技术提供商,其技术概述与二次开发基础是本篇论文关注的焦点。本文首先概述了科大讯飞语音识别技术的基本原理和API接口,随后深入探讨了二次开发过程中参数优化、场景化应用及后处理技术的实践技巧。进阶应用开发部分着重讨论了语音识别与自然语言处理的结合、智能家居中的应用以及移动应用中的语音识别集成。最后,论文分析了性能调优策略、常见问题解决方法,并展望了语音识别技术的未来趋势,特别是人工
【电机工程独家技术】:揭秘如何通过磁链计算优化电机设计

# 摘要
电机工程的基础知识与磁链概念是理解和分析电机性能的关键。本文首先介绍了电机工程的基本概念和磁链的定义。接着,通过深入探讨电机电磁学的基本原理,包括电磁感应定律和磁场理论基础,建立了电机磁链的理论分析框架。在此基础上,详细阐述了磁链计算的基本方法和高级模型,重点包括线圈与磁通的关系以及考虑非线性和饱和效应的模型。本文还探讨了磁链计算在电机设计中的实际应
【用户体验(UX)在软件管理中的重要性】:设计原则与实践

# 摘要
用户体验(UX)是衡量软件产品质量和用户满意度的关键指标。本文深入探讨了UX的概念、设计原则及其在软件管理中的实践方法。首先解析了用户体验的基本概念,并介绍了用户中心设计(UCD)和设计思维的重要性。接着,文章详细讨论了在软件开发生命周期中整合用户体验的重要性,包括敏捷开发环境下的UX设计方法以及如何进行用户体验度量和评估。最后,本文针对技术与用户需求平
【MySQL性能诊断】:如何快速定位和解决数据库性能问题

# 摘要
MySQL作为广泛应用的开源数据库系统,其性能问题一直是数据库管理员和技术人员关注的焦点。本文首先对MySQL性能诊断进行了概述,随后介绍了性能诊断的基础理论,包括性能指标、监控工具和分析方法论。在实践技巧章节,文章提供了SQL优化策略、数据库配置调整和硬件资源优化建议。通过分析性能问题解决的案例,例如慢
【硬盘管理进阶】:西数硬盘检测工具的企业级应用策略(企业硬盘管理的新策略)

# 摘要
硬盘作为企业级数据存储的核心设备,其管理与优化对企业信息系统的稳定运行至关重要。本文探讨了硬盘管理的重要性与面临的挑战,并概述了西数硬盘检测工具的功能与原理。通过深入分析硬盘性能优化策略,包括性能检测方法论与评估指标,本文旨在为企业提供硬盘维护和故障预防的最佳实践。此外,本文还详细介绍了数据恢复与备份的高级方法,并探讨了企业硬盘管理的未来趋势,包括云存储和分布式存储的融合,以及智能化管理工具的发展
【sCMOS相机驱动电路调试实战技巧】:故障排除的高手经验
# 摘要
sCMOS相机驱动电路是成像设备的重要组成部分,其性能直接关系到成像质量与系统稳定性。本文首先介绍了sCMOS相机驱动电路的基本概念和理论基础,包括其工作原理、技术特点以及驱动电路在相机中的关键作用。其次,探讨了驱动电路设计的关键要素,
【LSTM双色球预测实战】:从零开始,一步步构建赢率系统
# 摘要
本文旨在通过LSTM(长短期记忆网络)技术预测双色球开奖结果。首先介绍了LSTM网络及其在双色球预测中的应用背景。其次,详细阐述了理
EMC VNX5100控制器SP更换后性能调优:专家的最优实践

# 摘要
本文全面介绍了EMC VNX5100存储控制器的基本概念、SP更换流程、性能调优理论与实践以及故障排除技巧。首先概述了VNX5100控制器的特点以及更换服务处理器(SP)前的准备工作。接着,深入探讨了性能调优的基础理论,包括性能监控工具的使用和关键性能参数的调整。此外,本文还提供了系统级性能调优的实际操作指导
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )