初识 TensorFlow:安装与配置指南
发布时间: 2024-05-03 00:51:08 阅读量: 9 订阅数: 12 

# 2.1 TensorFlow 的环境配置
TensorFlow 的环境配置是使用 TensorFlow 的第一步,它涉及到系统要求、虚拟环境的创建和激活。
### 2.1.1 系统要求和版本兼容性
TensorFlow 对系统环境有一定的要求,包括操作系统、Python 版本和 CUDA 版本。具体要求如下:
- 操作系统:Windows、macOS 或 Linux
- Python 版本:Python 3.6 或更高版本
- CUDA 版本:CUDA 10.0 或更高版本(仅适用于 GPU 加速)
### 2.1.2 虚拟环境的创建和激活
为了隔离 TensorFlow 的依赖项并避免与系统环境的冲突, рекомендуется使用虚拟环境。在 Python 中,可以使用 `venv` 模块创建虚拟环境:
```bash
python3 -m venv tensorflow-env
```
激活虚拟环境:
```bash
source tensorflow-env/bin/activate
```
# 2. TensorFlow 配置技巧
### 2.1 TensorFlow 的环境配置
#### 2.1.1 系统要求和版本兼容性
* **操作系统:** TensorFlow 支持 Windows、macOS 和 Linux 系统。
* **Python 版本:** TensorFlow 2.x 及更高版本要求 Python 3.6 或更高版本。
* **CUDA 版本:** 如果需要使用 GPU 加速,需要安装与 TensorFlow 版本兼容的 CUDA 版本。
* **cuDNN 版本:** cuDNN 是一个用于 GPU 加速的深度学习库,需要与 TensorFlow 和 CUDA 版本兼容。
#### 2.1.2 虚拟环境的创建和激活
为了隔离 TensorFlow 的依赖项并避免与系统其他部分冲突,建议在虚拟环境中安装 TensorFlow。
**创建虚拟环境:**
```bash
python3 -m venv venv
```
**激活虚拟环境:**
```bash
source venv/bin/activate
```
### 2.2 TensorFlow 的硬件优化
#### 2.2.1 GPU 加速的安装和配置
GPU 加速可以显著提高 TensorFlow 训练和推理的性能。
**安装 GPU 驱动:**
* **NVIDIA 显卡:** 安装 NVIDIA 官方驱动程序。
* **AMD 显卡:** 安装 AMD 官方驱动程序。
**安装 TensorFlow GPU 版本:**
```bash
pip install tensorflow-gpu
```
**配置 GPU:**
```python
import tensorflow as tf
# 创建一个 GPU 设备
device = tf.config.list_physical_devices('GPU')[0]
# 将设备分配给 TensorFlow
tf.config.experimental.set_memory_growth(device, True)
```
#### 2.2.2 多 GPU 并行计算的设置
多 GPU 并行计算可以进一步提升训练速度。
**配置多 GPU:**
```python
import tensorflow as tf
# 创建一个多 GPU 设备列表
devices = tf.config.list_physical_devices('GPU')
# 将设备分配给 TensorFlow
for device in devices:
tf.config.experimental.set_memory_growth(device, True)
# 创建一个并行策略
strategy = tf.distribute.MirroredStrategy(devices)
```
### 2.3 TensorFlow 的调试和故障排除
#### 2.3.1 常见错误和解决方法
| 错误 | 原因 | 解决方法 |
|---|---|---|
| `ModuleNotFoundError: No module named 'tensorflow'` | TensorFlow 未安装 | 安装 TensorFlow |
| `ImportError: cannot import name 'keras'` | Keras 未安装 | 安装 Keras |
| `ValueError: Cannot convert a symbolic Tensor to a numpy array` | 试图将符号张量转换为 NumPy 数组 | 使用 `tf.keras.backend.eval()` 转换张量 |
| `RuntimeError: Failed to get convolution algorithm` | GPU 内存不足 | 增加 GPU 内存 |
#### 2.3.2 日志记录和调试工具的使用
* **日志记录:** TensorFlow 提供了日志记录功能,可以帮助调试问题。
* **TensorBoard:** TensorBoard 是一个可视化工具,可以帮助监控训练过程和调试模型。
* **tfdbg:** tfdbg 是一个 TensorFlow 调试器,可以帮助调试 TensorFlow 代码。
# 3.1 TensorFlow 的图像处理
#### 3.1.1 图像预处理和增强
图像预处理是图像处理中的关键步骤,它可以提高模型的性能和训练效率。TensorFlow 提供了丰富的图像预处理操作,包括:
- **调整大小和裁剪:**将图像调整为特定大小或从图像中裁剪特定区域。
- **旋转和翻转:**旋转或翻转图像以增加数据集的多样性。
- **颜色变换:**调整图像的亮度、对比度、饱和度和色相。
- **归一化:**将图像像素值缩放到特定范围内,通常是 [0, 1] 或 [-1, 1]。
```python
import tensorflow as tf
# 调整图像大小
image = tf.image.resize(image, [224, 224])
# 裁剪图像
image = tf.image.crop_to_bounding_box(image, 0, 0, 224, 224)
# 旋转图像
image = tf.image.rot90(image, k=1)
# 翻转图像
image = tf.image.flip_left_right(image)
# 调整图像亮度
image = tf.image.adjust_brightness(image, delta=0.5)
# 调整图像对比度
image = tf.image.adjust_contrast(image, contrast_factor=1.5)
# 调整图像饱和度
image = tf.image.adjust_saturation(image, saturation_factor=1.5)
# 调整图像色相
image = tf.image.adjust_hue(image, delta=0.5)
# 归一化图像
image = tf.image.per_image_standardization(image)
```
#### 3.1.2 图像分类和目标检测
TensorFlow 提供了多种图像分类和目标检测模型,包括:
- **图像分类:**识别图像中包含的对象或场景。
- **目标检测:**定位和识别图像中的对象。
```python
# 使用预训练的图像分类模型
model = tf.keras.applications.VGG16(weights='imagenet')
# 对图像进行预测
predictions = model.predict(image)
# 使用预训练的目标检测模型
model = tf.keras.models.load_model('model.h5')
# 对图像进行预测
predictions = model.predict(image)
```
# 4. TensorFlow 进阶应用
### 4.1 TensorFlow 的分布式训练
#### 4.1.1 分布式训练的原理和优势
分布式训练是一种在多台机器上并行训练机器学习模型的技术。它通过将训练数据集和计算任务分配到不同的机器上,可以显著提高训练速度和效率。
分布式训练的主要优势包括:
- **更快的训练速度:**多个机器同时训练模型,可以减少训练时间。
- **更大的数据集:**分布式训练可以处理更大的数据集,从而提高模型的准确性和泛化能力。
- **更好的模型并行化:**分布式训练允许将模型并行化到多个机器上,从而支持训练更大、更复杂的模型。
#### 4.1.2 TensorFlow 分布式训练的实现
TensorFlow 提供了多种分布式训练策略,包括:
- **数据并行:**将训练数据副本分配到不同的机器上,每个机器训练模型的不同部分。
- **模型并行:**将模型的不同部分分配到不同的机器上,每个机器训练模型的特定层或模块。
- **混合并行:**结合数据并行和模型并行,以实现最佳性能。
TensorFlow 提供了以下 API 来实现分布式训练:
- `tf.distribute.MirroredStrategy`:用于数据并行。
- `tf.distribute.TPUStrategy`:用于模型并行,需要使用 TPU。
- `tf.distribute.MultiWorkerMirroredStrategy`:用于混合并行,需要使用多个工作器机器。
### 4.2 TensorFlow 的自定义层和模型
#### 4.2.1 自定义层的创建和使用
自定义层允许开发人员创建自己的神经网络层,以满足特定的需求。要创建自定义层,需要实现以下方法:
- `build`:初始化层并创建可训练变量。
- `call`:定义层的前向传播行为。
```python
import tensorflow as tf
class MyCustomLayer(tf.keras.layers.Layer):
def __init__(self, units=32):
super(MyCustomLayer, self).__init__()
self.units = units
self.kernel = self.add_weight(name='kernel',
shape=(self.units, 1),
initializer='random_normal',
trainable=True)
def build(self, input_shape):
pass
def call(self, inputs):
return tf.matmul(inputs, self.kernel)
```
#### 4.2.2 预训练模型的微调和迁移学习
预训练模型是在大型数据集上训练的模型,可以作为迁移学习的起点。迁移学习涉及将预训练模型的权重用于新任务,并对其进行微调以适应新数据集。
TensorFlow 提供了以下 API 来微调预训练模型:
- `tf.keras.applications`:包含各种预训练模型,如 VGG16、ResNet50 和 MobileNetV2。
- `tf.keras.Model.load_weights`:加载预训练模型的权重。
- `tf.keras.Model.compile`:重新编译模型以适应新任务。
### 4.3 TensorFlow 的云计算集成
#### 4.3.1 TensorFlow Serving 的部署和使用
TensorFlow Serving 是一个用于部署和服务机器学习模型的平台。它提供了以下功能:
- **模型版本管理:**管理模型的不同版本,并轻松地进行模型更新。
- **预测服务:**通过 REST API 或 gRPC 提供模型预测。
- **监控和日志记录:**提供模型性能和使用情况的监控和日志记录。
#### 4.3.2 云平台上的 TensorFlow 训练和推理
TensorFlow 可以与各种云平台集成,包括 AWS、Azure 和 Google Cloud。这些平台提供以下优势:
- **弹性计算资源:**按需扩展计算资源,以满足训练和推理需求。
- **存储和数据管理:**提供大规模存储和数据管理服务,以处理大型数据集。
- **预建基础设施:**提供预建的 TensorFlow 环境,简化了部署和管理。
# 5. TensorFlow 进阶应用
### 5.1 TensorFlow 的分布式训练
#### 5.1.1 分布式训练的原理和优势
分布式训练是一种利用多个计算节点并行训练大型模型的技术。它通过将模型参数和数据分发到不同的节点上,同时进行训练,从而显著提高训练速度。
分布式训练的主要优势包括:
- **加速训练:**并行训练可以将训练时间缩短到单个节点的几分之一。
- **处理更大数据集:**分布式训练可以处理单个节点无法容纳的大型数据集。
- **提高模型性能:**分布式训练可以稳定训练过程,提高模型的泛化性能。
#### 5.1.2 TensorFlow 分布式训练的实现
TensorFlow 提供了分布式策略 API,用于在多个 GPU 或 TPU 上进行分布式训练。以下代码演示了如何使用 `MirroredStrategy` 策略在两个 GPU 上进行分布式训练:
```python
import tensorflow as tf
# 创建分布式策略
strategy = tf.distribute.MirroredStrategy()
# 定义模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 分布式训练
with strategy.scope():
model.fit(x_train, y_train, epochs=10)
```
在这个示例中,`strategy.scope()` 上下文管理器确保模型在分布式策略的范围内训练。分布式策略负责将模型参数和数据分发到不同的 GPU 上,并协调它们的训练过程。
0
0
相关推荐

专栏简介
本专栏全面涵盖了 TensorFlow 的安装、配置和使用。从初学者指南到深入的技术解析,文章涵盖了广泛的主题,包括:
* TensorFlow 的安装和常见问题解决
* TensorFlow 的核心组件和 GPU 加速配置
* 使用 Anaconda 管理 TensorFlow 环境
* TensorFlow 数据集加载和预处理技巧
* TensorFlow 中的张量操作和模型保存/加载
* TensorFlow 模型部署到生产环境的最佳实践
* 使用 TensorFlow Serving 构建高性能模型服务器
* TensorFlow 在自然语言处理和数据增强中的应用
* TensorFlow 中的优化器、多任务学习和分布式训练
* TensorFlow 的加密和隐私保护技术
* TensorFlow 模型压缩和轻量化技术
* TensorFlow 生态系统和模型评估指标
* TensorFlow 在大规模数据处理中的优化方案
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB阶乘大数据分析秘籍:应对海量数据中的阶乘计算挑战,挖掘数据价值
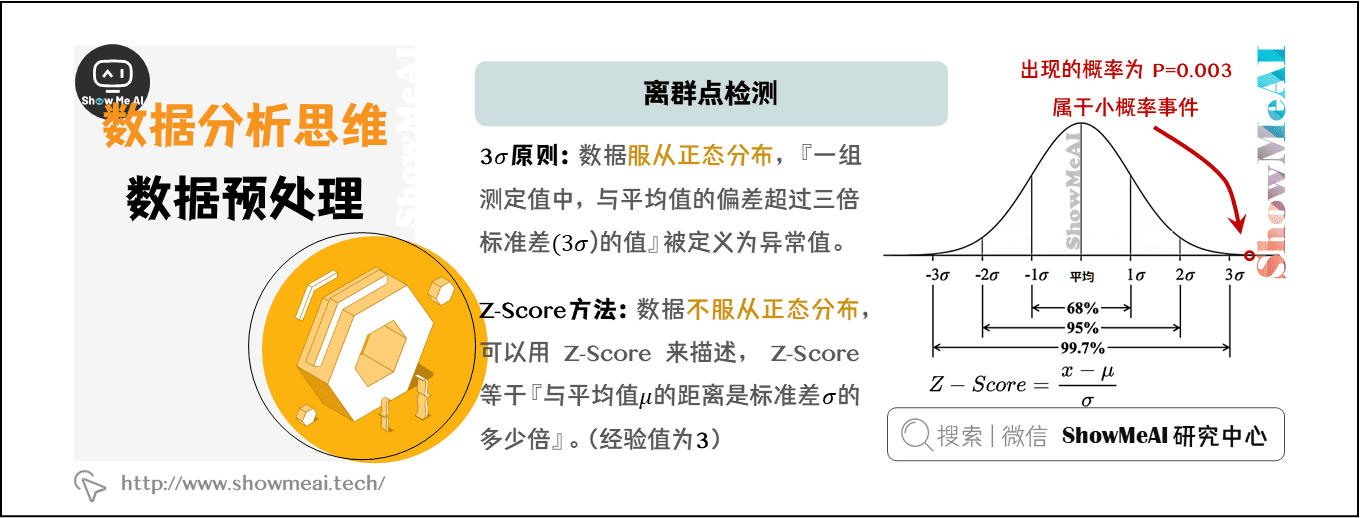
# 1. MATLAB阶乘计算基础**
MATLAB阶乘函数(factorial)用于计算给定非负整数的阶乘。阶乘定义为一个正整数的所有正整数因子的乘积。例如,5的阶乘(5!)等于120,因为5! = 5 × 4 × 3 × 2 × 1。
MATLAB阶乘函数的语法如下:
```
y = factorial(x)
```
其中:
* `x`:要计算阶
MATLAB数值计算高级技巧:求解偏微分方程和优化问题

# 1. MATLAB数值计算概述**
MATLAB是一种强大的数值计算环境,它提供了一系列用于解决各种科学和工程问题的函数和工具。MATLAB数值计算的主要优
MATLAB随机数交通规划中的应用:从交通流量模拟到路线优化

# 1.1 交通流量的随机特性
交通流量具有明显的随机性,这主要体现在以下几个方面:
- **车辆到达时间随机性:**车辆到达某个路口或路段的时间不是固定的,而是服从一定的概率分布。
- **车辆速度随机性:**车辆在道路上行驶的速度会受到各种因素的影响,如道路状况、交通状况、天气状况等,因此也是随机的。
- **交通事故随机性:**交通事故的发生具有偶然性,其发生时间
MATLAB遗传算法交通规划应用:优化交通流,缓解拥堵难题

# 1. 交通规划概述**
交通规划是一门综合性学科,涉及交通工程、城市规划、经济学、环境科学等多个领域。其主要目的是优化交通系统,提高交通效率,缓解交通拥堵,保障交通安全。
交通规划的范围十分广泛,包括交通需求预测、交通网络规划、交通管理和控制、交通安全管理等。交通规划需要考虑多种因素,如人口分布、土地利用、经济发展、环境保护等,并综合运用各种技术手段和管理措施,实现交通系统的可持续发展。
# 2. 遗传算法原理
傅里叶变换在MATLAB中的云计算应用:1个大数据处理秘诀

# 1. 傅里叶变换基础**
傅里叶变换是一种数学工具,用于将时域信号分解为其频率分量。它在信号处理、图像处理和数据分析等领域有着广泛的应用。
傅里叶变换的数学表达式为:
```
F(ω) = ∫_{-\infty}^{\infty} f(t) e^(-iωt) dt
```
其中:
* `f(t)` 是时域信号
* `F(ω)` 是频率域信号
* `ω`
C++内存管理详解:指针、引用、智能指针,掌控内存世界
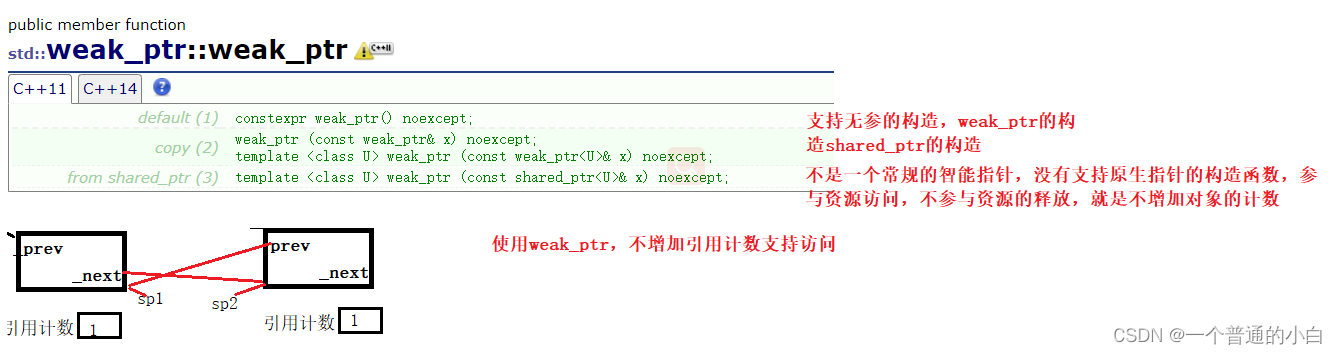
# 1. C++内存管理基础**
C++内存管理是程序开发中的关键环节,它决定了程序的内存使用效率、稳定性和安全性。本章将介绍C++内存管理的基础知识,为后续章节的深入探讨奠定基础。
C++中,内存管理主要涉及两个方面:动态内存分配和内存释放。动态内存分配是指在程序运行时从堆内存中分配内存空间,而内存释放是指释放不再使用的内存空间,将其返还给系统。
# 2. 指针与引用
### 2.1 指针的本
实现稳定性和鲁棒性:MATLAB数值积分在控制系统中的应用
# 1. MATLAB数值积分简介
数值积分是一种近似计算定积分的方法,在控制系统中广泛应用于求解微分方程和计算系统响应。MATLAB提供了一系列数值积分函数,如`trapz`、`simpson`和`ode45`,可以方便地进行数值积分计算。
数值积分方法的精度由积分区间、步长和积分方法决定。常用的积分方法包括梯形法则、辛普森法则和龙格-库塔法。梯形法则简单易用,但精度较低;辛普森
应用MATLAB傅里叶变换:从图像处理到信号分析的实用指南

# 1. MATLAB傅里叶变换概述
傅里叶变换是一种数学工具,用于将信号从时域转换为频域。它在信号处理、图像处理和通信等领域有着广泛的应用。MATLAB提供了一系列函
MATLAB等高线在医疗成像中的应用:辅助诊断和治疗决策,提升医疗水平
# 1. MATLAB等高线在医疗成像中的概述**
MATLAB等高线是一种强大的工具,用于可视化和分析医疗图像中的数据。它允许用户创建等高线图,显示图像中特定值或范围的区域。在医疗成像中,等高线可以用于各种应用,包括图像分割、配准、辅助诊断和治疗决策。
等高线图通过将图像中的数据点连接起来创建,这些数据点具有相同的特定值。这可以帮助可视化图像中的数据分布,并识别感兴趣
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )