TensorFlow 中的张量操作详解
发布时间: 2024-05-03 01:00:19 阅读量: 97 订阅数: 40 

浅谈tensorflow中张量的提取值和赋值

# 2.1 张量运算的数学原理
### 2.1.1 张量乘法
张量乘法是张量运算中最基本的操作之一。对于两个张量 A 和 B,它们的乘积 C 可以表示为:
```python
C = A @ B
```
其中,`@` 符号表示张量乘法运算。张量乘法的维度计算规则如下:
* 如果 A 的形状为 (m, n),B 的形状为 (n, k),则 C 的形状为 (m, k)。
* 两个张量的最后一个维度必须相同,否则无法进行乘法运算。
### 2.1.2 张量求导
张量求导是计算张量相对于某个变量的导数。在 TensorFlow 中,可以使用 `tf.gradients` 函数来计算张量求导。
```python
grads = tf.gradients(loss, var_list)
```
其中,`loss` 是要计算导数的损失函数,`var_list` 是要计算导数的变量列表。`grads` 是一个列表,其中包含每个变量相对于损失函数的导数。
# 2. 张量操作的理论与实践
### 2.1 张量运算的数学原理
#### 2.1.1 张量乘法
张量乘法是张量操作中的一种基本运算,用于计算两个或多个张量之间的乘积。张量乘法有两种主要类型:点积和矩阵乘法。
**点积**计算两个向量的标量乘积。对于两个向量 `a` 和 `b`,它们的点积定义为:
```
a · b = ∑(a_i * b_i)
```
其中 `a_i` 和 `b_i` 分别是向量 `a` 和 `b` 中的第 `i` 个元素。
**矩阵乘法**计算两个矩阵之间的乘积。对于两个矩阵 `A` 和 `B`,它们的乘积 `C` 定义为:
```
C = A * B
```
其中 `C` 的元素 `c_ij` 由以下公式计算:
```
c_ij = ∑(a_ik * b_kj)
```
其中 `a_ik` 是矩阵 `A` 的第 `i` 行和第 `k` 列的元素,`b_kj` 是矩阵 `B` 的第 `k` 行和第 `j` 列的元素。
#### 2.1.2 张量求导
张量求导是计算张量相对于其他张量的导数。张量求导在机器学习中非常重要,因为它用于计算梯度,从而优化模型参数。
对于一个标量函数 `f(x)`,其中 `x` 是一个张量,`f(x)` 的梯度定义为:
```
∇f(x) = [∂f/∂x_1, ∂f/∂x_2, ..., ∂f/∂x_n]
```
其中 `x_1`, `x_2`, ..., `x_n` 是张量 `x` 中的元素。
张量求导可以使用链式法则来计算。对于两个张量 `x` 和 `y`,其中 `y = f(x)`,`f(x)` 的梯度可以表示为:
```
∇f(x) = ∇f(y) * ∇y(x)
```
其中 `∇f(y)` 是 `f(y)` 的梯度,`∇y(x)` 是 `y` 相对于 `x` 的梯度。
### 2.2 TensorFlow中的张量操作函数
#### 2.2.1 基本张量操作
TensorFlow 提供了一系列基本张量操作函数,用于执行常见的张量操作。这些函数包括:
- `tf.add()`:张量加法
- `tf.subtract()`:张量减法
- `tf.multiply()`:张量乘法
- `tf.divide()`:张量除法
- `tf.matmul()`:矩阵乘法
- `tf.transpose()`:张量转置
- `tf.reshape()`:张量重塑
```python
import tensorflow as tf
# 创建两个张量
a = tf.constant([[1, 2], [3, 4]])
b = tf.constant([[5, 6], [7, 8]])
# 执行张量加法
c = tf.add(a, b)
# 打印结果
print(c) # 输出:[[ 6 8]
# [10 12]]
```
#### 2.2.2 高级张量操作
TensorFlow 还提供了高级张量操作函数,用于执行更复杂的张量操作。这些函数包括:
- `tf.reduce_sum()`:张量求和
- `tf.reduce_mean()`:张量求平均值
- `tf.reduce_max()`:张量求最大值
- `tf.reduce_min()`:张量求最小值
- `tf.argmax()`:张量求最大值索引
- `tf.argmin()`:张量求最小值索引
```python
# 创建一个张量
a = tf.constant([[1, 2], [3, 4]])
# 执行张量求和
b = tf.reduce_sum(a)
# 打印结果
print(b) # 输出:10
```
# 3. 张量处理的实践应用
### 3.1 图像处理中的张量操作
张量在图像处理领域有着广泛的应用,从图像预处理到图像增强,都能发挥重要作用。
#### 3.1.1 图像预处理
图像预处理是图像处理的第一步,通常包括以下操作:
- **图像大小调整:**将图像调整到所需的尺寸,以满足模型或算法的要求。
- **图像归一化:**将图像像素值归一化到[0, 1]或[-1, 1]的范围内,以减少像素值范围对模型的影响。
- **图像增强:**对图像进行增强操作,如锐化、对比度调整和颜色校正,以提高图像质量。
TensorFlow提供了多种用于图像预处理的函数,例如:
```python
import tensorflow as tf
# 图像大小调整
image = tf.image.resize(image, [224, 224])
# 图像归一化
image = tf.image.per_image_standardization(image)
# 图像锐化
image = tf.image.sharpness(image, 1.0)
```
#### 3.1.2 图像增强
图像增强是图像处理中另一个重要的步骤,它可以提高图像的质量和可读性。TensorFlow提供了多种图像增强函数,例如:
```python
import tensorflow as tf
# 对比度调整
image = tf.image.adjust_contrast(image, 1.5)
# 颜色校正
image = tf.image.adjust_hue(image, 0.1)
# 伽马校正
image = tf.image.adjust_gamma(image, 1.2)
```
### 3.2 自然语言处理中的张量操作
张量在自然语言处理(NLP)中也扮演着重要的角色,从文本预处理到文本分类,都能发挥作用。
#### 3.2.1 文本预处理
文本预处理是NLP的第一步,通常包括以下操作:
- **文本分词:**将文本分割成单词或词组。
- **文本去停用词:**去除文本中常见的无意义单词,如“the”、“and”、“of”。
- **文本词干化:**将单词还原为其词干,以减少单词变体的影响。
TensorFlow提供了多种用于文本预处理的函数,例如:
```python
import tensorflow as tf
# 文本分词
words = tf.strings.split(text, ' ')
# 文本去停用词
words = tf.strings.regex_replace(words, '[^a-zA-Z0-9]', '')
# 文本词干化
words = tf.strings.reduce_join(tf.strings.stem(words), ' ')
```
#### 3.2.2 文本分类
文本分类是NLP中的一个重要任务,它可以将文本分配到预定义的类别中。TensorFlow提供了多种用于文本分类的函数,例如:
```python
import tensorflow as tf
# 创建文本分类模型
model = tf.keras.Sequential([
tf.keras.layers.Embedding(10000, 128),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
# 训练文本分类模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)
# 评估文本分类模型
model.evaluate(x_test, y_test)
```
# 4.1 张量流的构建与训练
### 4.1.1 流图的定义
在 TensorFlow 中,张量流是一个表示计算图的数据结构。它定义了数据如何从输入张量流向输出张量。构建流图是 TensorFlow 编程的关键步骤。
```python
import tensorflow as tf
# 创建占位符
x = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
y = tf.placeholder(tf.float32, shape=[None, 10])
# 定义卷积层
conv1 = tf.layers.conv2d(x, 32, 5, activation=tf.nn.relu)
# 定义池化层
pool1 = tf.layers.max_pooling2d(conv1, 2, 2)
# 定义全连接层
fc1 = tf.layers.dense(pool1, 128, activation=tf.nn.relu)
# 定义输出层
logits = tf.layers.dense(fc1, 10)
# 定义损失函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
# 定义优化器
optimizer = tf.train.AdamOptimizer(learning_rate=0.001)
# 定义训练操作
train_op = optimizer.minimize(loss)
```
### 4.1.2 模型的训练和评估
构建流图后,就可以训练模型。训练过程包括以下步骤:
1. **初始化变量:**使用 `tf.global_variables_initializer()` 初始化模型中的所有变量。
2. **创建会话:**使用 `tf.Session()` 创建一个会话来运行流图。
3. **训练模型:**使用 `session.run(train_op, feed_dict={x: x_train, y: y_train})` 来训练模型,其中 `x_train` 和 `y_train` 是训练数据。
4. **评估模型:**使用 `session.run(loss, feed_dict={x: x_test, y: y_test})` 来评估模型的性能,其中 `x_test` 和 `y_test` 是测试数据。
```python
# 初始化变量
init = tf.global_variables_initializer()
# 创建会话
with tf.Session() as sess:
sess.run(init)
# 训练模型
for epoch in range(10):
for batch in range(100):
sess.run(train_op, feed_dict={x: x_train[batch], y: y_train[batch]})
# 评估模型
loss_value = sess.run(loss, feed_dict={x: x_test, y: y_test})
print("损失函数值:", loss_value)
```
# 5. TensorFlow中的张量操作实战
### 5.1 人工智能项目中的张量操作
#### 5.1.1 图像识别项目
**代码块:**
```python
import tensorflow as tf
# 加载图像数据
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 归一化图像数据
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# 创建模型
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10)
# 评估模型
model.evaluate(x_test, y_test)
```
**参数说明:**
* `x_train`:训练集图像数据
* `y_train`:训练集标签数据
* `x_test`:测试集图像数据
* `y_test`:测试集标签数据
* `model`:神经网络模型
* `optimizer`:优化算法
* `loss`:损失函数
* `metrics`:评估指标
**逻辑分析:**
该代码片段展示了如何使用TensorFlow构建和训练一个图像识别模型。它加载了MNIST数据集,预处理了图像数据,创建了一个神经网络模型,并使用Adam优化算法训练了模型。最后,它评估了模型在测试集上的性能。
#### 5.1.2 自然语言处理项目
**代码块:**
```python
import tensorflow as tf
# 加载文本数据
data = tf.keras.datasets.imdb.load_data(num_words=10000)
(x_train, y_train), (x_test, y_test) = data
# 转换为序列
x_train = tf.keras.preprocessing.sequence.pad_sequences(x_train, maxlen=256)
x_test = tf.keras.preprocessing.sequence.pad_sequences(x_test, maxlen=256)
# 创建模型
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(10000, 128),
tf.keras.layers.LSTM(128),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10)
# 评估模型
model.evaluate(x_test, y_test)
```
**参数说明:**
* `data`:文本数据集
* `x_train`:训练集文本数据
* `y_train`:训练集标签数据
* `x_test`:测试集文本数据
* `y_test`:测试集标签数据
* `model`:神经网络模型
* `optimizer`:优化算法
* `loss`:损失函数
* `metrics`:评估指标
**逻辑分析:**
该代码片段展示了如何使用TensorFlow构建和训练一个自然语言处理模型。它加载了IMDB数据集,预处理了文本数据,创建了一个神经网络模型,并使用Adam优化算法训练了模型。最后,它评估了模型在测试集上的性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面涵盖了 TensorFlow 的安装、配置和使用。从初学者指南到深入的技术解析,文章涵盖了广泛的主题,包括:
* TensorFlow 的安装和常见问题解决
* TensorFlow 的核心组件和 GPU 加速配置
* 使用 Anaconda 管理 TensorFlow 环境
* TensorFlow 数据集加载和预处理技巧
* TensorFlow 中的张量操作和模型保存/加载
* TensorFlow 模型部署到生产环境的最佳实践
* 使用 TensorFlow Serving 构建高性能模型服务器
* TensorFlow 在自然语言处理和数据增强中的应用
* TensorFlow 中的优化器、多任务学习和分布式训练
* TensorFlow 的加密和隐私保护技术
* TensorFlow 模型压缩和轻量化技术
* TensorFlow 生态系统和模型评估指标
* TensorFlow 在大规模数据处理中的优化方案
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【状态机深度解析】:在Verilog中如何设计高效自动售货机
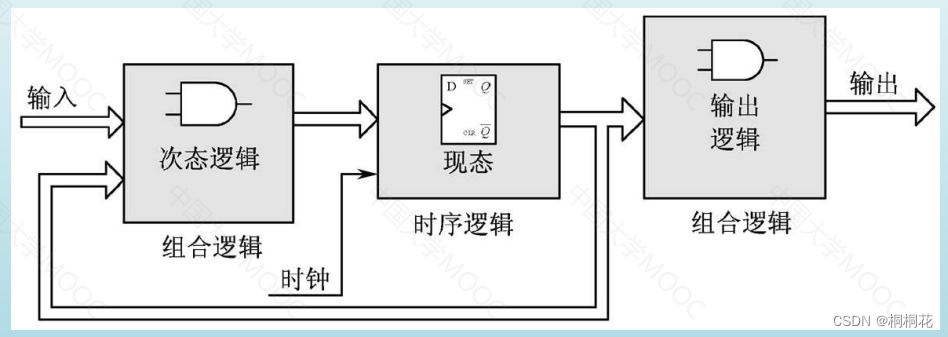
# 摘要
本文系统地探讨了状态机的设计与应用,首先介绍了状态机设计的基础知识,并详细阐述了在Verilog中实现状态机的设计原则,包括状态的分类、建模方法、状态编码及转换表的设计。接着,针对自动售货机的场景,本文详细描述了状态机的设计实现过程,包括用户界面交互、商品选择、货币处理和状态转换逻辑编写等。此外,还探讨了状态机的设计验证与测试,包括测试环境构建、仿真测试、调试和硬件实现验证。最后,本文提出了状态机优化的方法,并讨论了状态机在其他领域中的应
【MATLAB高级索引攻略】:解锁数据处理的隐藏技能

# 摘要
MATLAB作为一种高效的数据处理工具,其高级索引技术在数据科学领域发挥着重要作用。本文首先概述了MATLAB高级索引的基本概念与作用,随后深入探讨了索引操作的数学原理及数据结构。进一步,文章详细介绍了MATLAB高级索引实践技巧,包括复杂条件下的索引应用和高效数据提取与处理方法。在数据处理应用方面,本文阐述了处理大型数据集的索引策略、多维数据的可视化索引技术,以及M
C语言高级编程:子程序参数传递的全面解析
# 摘要
本文深入探讨了C语言中子程序参数传递的机制及其优化技术,首先概述了参数传递的基础知识,随后详细分析了按值传递和按引用传递的优缺点,以及在实现机制中的具体应用,包括内存中的参数布局、指针的作用和复合数据类型的传递。文章进一步探讨了高级参数传递技术,如指针的指针、const修饰符的使用以及可变参数列表的处理,并通过实践案例和最佳实践,讨论了在实际项目中应用这些技术的策略和技巧。本文旨在为C语言开发者提供系
【故障无忧】:西门子SINUMERIK 840D sl_828D测量循环问题全解析及解决之道

# 摘要
本文对西门子数控系统的核心组件SINUMERIK 840D sl/828D的测量循环功能进行了详尽的探讨。文章首先概述了测量循环的基本概念及其在制造业中的应用价值,然后详细介绍了测量循环的操作流程、编程指令以及高级应用技巧。通过故障分析章节,本文分类并识别了测量循环中常见的硬件和软件故障,提供了故障案例分析以及预防和监控策略。进一步地
数字签名机制全解析:RSA和ECDSA的工作原理及应用

# 摘要
本文全面概述了数字签名机制,详细介绍了公钥加密的理论基础,包括对称与非对称加密的原理和局限性、大数分解及椭圆曲线数学原理。通过深入探讨RSA和ECDSA算法的工作原理,本文揭示了两种算法在密钥生成、加密解密、签名验证等方面的运作机制,并分析了它们相对于传统加密方式
【CAD2002高级技巧】
# 摘要
本文对CAD2002软件进行全面的介绍和分析,从软件概述、界面布局、基础操作深入剖析,到绘图与编辑技巧实战,再到高级功能拓展以及优化与故障排除。文章详细阐述了CAD2002的工具与命令高级使用技巧、图层管理、块与外部参照应用等基础操作,深入探讨了精确绘图、高级编辑命令和综合绘图案例。此外,还介绍了CAD2002的参数化绘图、数据交换、自定义脚本编写等高级功能,以及性
Word 2016 Endnotes加载项疑难杂症:专家级解决方案
# 摘要
本文详细介绍了Word 2016中Endnotes功能的概述、工作原理、常见问题诊断以及应用实践,并展望了其发展。首先,对Endnotes功能进行了基础性的介绍,并探讨了其加载项的结构和作用。接着,分析了在使用Endnotes加载项时可能遇到的问题,包括不工作、冲突以及性能问题,并提
【搜索引擎查询优化】:提速与相关性提升的双重攻略

# 摘要
本文旨在综述搜索引擎查询优化的各个方面,从搜索引擎的工作原理、查询优化策略到实践案例分析,再到未来趋势。首先介绍了搜索引擎的基础工作流程,包括爬虫抓取、索引构建、查询处理和排名算法。随后,探讨了提升网页相关性、前端性能优化以及CDN和缓存机制的使用。案例分析部分深入研究了相关性改进、响应时间加
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )