【分治法:IT领域问题解决的利器】:掌握分治法,轻松应对复杂问题
发布时间: 2024-08-24 15:27:19 阅读量: 9 订阅数: 12 
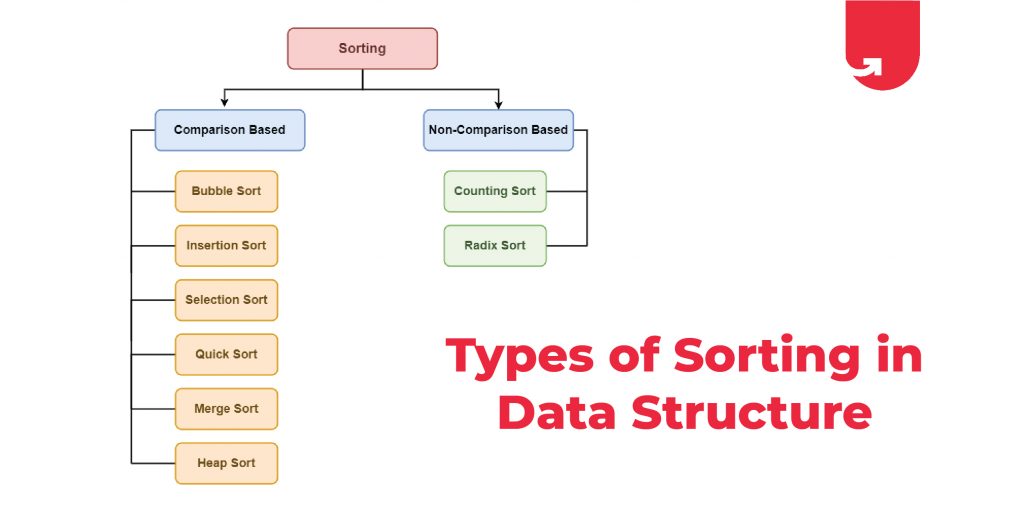
# 1. 分治法的基本概念和原理**
分治法是一种解决问题的经典算法范式,其核心思想是将一个复杂的问题分解成若干个较小的问题,分别解决这些小问题,然后再将它们的解合并得到原问题的解。分治法遵循“分而治之”的原则,通过递归的方式将问题不断分解,直至问题足够简单,可以直接求解。
分治法通常包含三个基本步骤:
1. **分解:**将原问题分解成若干个规模较小的子问题。
2. **解决:**递归地解决每个子问题。
3. **合并:**将子问题的解合并得到原问题的解。
# 2. 分治法在算法中的应用**
分治法是一种经典的算法设计范式,它将一个复杂的问题分解成一系列较小的子问题,然后递归地求解这些子问题,最后合并子问题的解得到原问题的解。分治法具有时间复杂度低、代码简洁等优点,广泛应用于各种算法中。
**2.1 分治法求解最大子数组和**
**问题描述:**
给定一个包含 n 个整数的数组 nums,求出其中连续子数组的最大和。
**分治算法:**
1. **基线条件:**如果数组 nums 只有一个元素,则最大子数组和为该元素本身。
2. **分治:**将数组 nums 分成左右两半,分别求出左右两半的最大子数组和。
3. **合并:**比较左右两半的最大子数组和,以及跨越中点的最大子数组和。跨越中点的最大子数组和可以通过扫描数组得到。
**代码实现:**
```python
def max_subarray_sum(nums):
"""
求解数组中连续子数组的最大和。
参数:
nums: 输入的整数数组。
返回:
连续子数组的最大和。
"""
n = len(nums)
if n == 1:
return nums[0]
mid = n // 2
left_max = max_subarray_sum(nums[:mid])
right_max = max_subarray_sum(nums[mid:])
max_left = nums[mid - 1]
max_right = nums[mid]
for i in range(mid - 2, -1, -1):
max_left = max(max_left, max_left + nums[i])
for i in range(mid + 1, n):
max_right = max(max_right, max_right + nums[i])
return max(left_max, right_max, max_left + max_right)
```
**逻辑分析:**
该代码首先检查数组 nums 是否只有一个元素,如果是,则直接返回该元素。否则,将数组分成左右两半,递归求解左右两半的最大子数组和。然后,比较左右两半的最大子数组和,以及跨越中点的最大子数组和。跨越中点的最大子数组和可以通过扫描数组得到。最后,返回三个值中的最大值。
**2.2 分治法求解逆序对数目**
**问题描述:**
给定一个长度为 n 的整数数组 nums,求出其中逆序对的数目。逆序对是指一对元素 (i, j) 满足 i < j 且 nums[i] > nums[j]。
**分治算法:**
1. **基线条件:**如果数组 nums 只有一个元素,则没有逆序对。
2. **分治:**将数组 nums 分成左右两半,分别求出左右两半的逆序对数目。
3. **合并:**计算跨越中点的逆序对数目。跨越中点的逆序对数目可以通过扫描数组得到。
**代码实现:**
```python
def count_inversions(nums):
"""
求解数组中逆序对的数目。
参数:
nums: 输入的整数数组。
返回:
逆序对的数目。
"""
n = len(nums)
if n == 1:
return 0
mid = n // 2
left_inversions = count_inversions(nums[:mid])
right_inversions = count_inversions(nums[mid:])
inversions = left_inversions + right_inversions
i, j, k = 0, mid, 0
while i < mid and j < n:
if nums[i] <= nums[j]:
nums[k] = nums[i]
i += 1
else:
nums[k] = nums[j]
j += 1
inversions += mid - i
k += 1
return inversions
```
**逻辑分析:**
该代码首先检查数组 nums 是否只有一个元素,如果是,则直接返回 0。否则,将数组分成左右两半,递归求出左右两半的逆序对数目。然后,计算跨越中点的逆序对数目。跨越中点的逆序对数目可以通过扫描数组得到。最后,返回三个值之和。
**2.3 分治法求解最近点对**
**问题描述:**
给定一个包含 n 个点的集合 points,求出其中距离最小的两点之间的距离。
**分治算法:**
1. **基线条件:**如果集合 points 只有两个点,则距离最小的两点之间的距离为这两个点之间的距离。
2. **分治:**将集合 points 沿 x 轴或 y 轴分成左右两半,分别求出左右两半的距离最小的两点之间的距离。
3. **合并:**计算跨越中点的距离最小的两点之间的距离。跨越中点的距离最小的两点之间的距离可以通过扫描数组得到。
**代码实现:**
```python
import math
def closest_pair(points):
"""
求解集合中距离最小的两点之间的距离。
参数:
points: 输入的点集合。
返回:
距离最小的两点之间的距离。
"""
n = len(points)
if n <= 1:
return float('inf')
if n == 2:
return math.sqrt((points[0][0] - points[1][0]) ** 2 + (points[0][1] - points[1][1]) ** 2)
points.sort(key=lambda point: point[0])
left_min = closest_pair(points[:n // 2])
right_min = closest_pair(points[n // 2:])
min_distance = min(left_min, right_min)
# 计算跨越中点的距离最小的两点之间的距离
strip = []
for point in points:
if abs(point[0] - points[n // 2][0]) < min_distance:
strip.append(point)
for i in range(len(strip)):
for j in range(i + 1, len(strip)):
distance = math.sqrt((strip[i][0] - strip[j][0]) ** 2 + (strip[i][1] - strip[j][1]) ** 2)
min_distance = min(min_distance, distance)
return min_distance
```
**逻辑分析:**
该代码首先检查集合 points 是否只有一个或两个点,如果是,则直接返回距离。否则,将集合 points 沿 x 轴或 y 轴分成左右两半,递归求出左右两半的距离最小的两点之间的距离。然后,计算跨越中点的距离最小的两点之间的距离。跨越中点的距离最小的两点之间的距离可以通过扫描数组得到。最后,返回三个值中的最小值。
# 3. 分治法在数据结构中的应用
分治法在数据结构中有着广泛的应用,它可以有效地解决复杂的数据处理问题。本章节将介绍分治法在快速排序、归并排序和二叉搜索树中的应用。
### 3.1 分治法实现快速排序
快速排序是一种基于分治思想的排序算法,其平均时间复杂度为 O(n log n),最坏时间复杂度为 O(n^2)。
**算法步骤:**
1. **选择一个基准元素:**从数组中选择一个元素作为基准元素。
2. **分区:**将数组分为两部分,一部分包含比基准元素小的元素,另一部分包含比基准元素大的元素。
3. **递归:**对两个分区分别应用快速排序。
**代码实现:**
```python
def quick_sort(arr):
"""
快速排序算法
:param arr: 待排序数组
:return: 排序后的数组
"""
if len(arr) <= 1:
return arr
# 选择基准元素
pivot = arr[len(arr) // 2]
# 分区
left = []
right = []
for num in arr:
if num < pivot:
left.append(num)
elif num > pivot:
right.append(num)
# 递归
return quick_sort(left) + [pivot] + quick_sort(right)
```
**逻辑分析:**
* 第 1 行:边界条件判断,如果数组长度小于或等于 1,则直接返回。
* 第 4-6 行:选择基准元素,这里选择数组中位数作为基准。
* 第 8-12 行:分区,将数组分为两部分,分别包含比基准元素小的元素和比基准元素大的元素。
* 第 14-16 行:递归地对两个分区应用快速排序,最后将排序后的两个分区和基准元素合并返回。
### 3.2 分治法实现归并排序
归并排序是一种基于分治思想的稳定排序算法,其时间复杂度为 O(n log n)。
**算法步骤:**
1. **递归:**将数组分为两部分,对两个部分分别应用归并排序。
2. **合并:**将排序后的两个部分合并为一个排序的数组。
**代码实现:**
```python
def merge_sort(arr):
"""
归并排序算法
:param arr: 待排序数组
:return: 排序后的数组
"""
if len(arr) <= 1:
return arr
# 分区
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
# 合并
return merge(left, right)
def merge(left, right):
"""
合并两个排序的数组
:param left: 排序的左数组
:param right: 排序的右数组
:return: 合并后的排序数组
"""
i = 0
j = 0
merged = []
while i < len(left) and j < len(right):
if left[i] <= right[j]:
merged.append(left[i])
i += 1
else:
merged.append(right[j])
j += 1
while i < len(left):
merged.append(left[i])
i += 1
while j < len(right):
merged.append(right[j])
j += 1
return merged
```
**逻辑分析:**
* 第 1 行:边界条件判断,如果数组长度小于或等于 1,则直接返回。
* 第 4-6 行:分区,将数组分为两部分,分别应用归并排序。
* 第 8-15 行:合并两个排序的数组,通过比较两个数组中的元素,将较小的元素添加到合并的数组中。
* 第 16-18 行:将剩余的元素添加到合并的数组中。
### 3.3 分治法实现二叉搜索树
二叉搜索树是一种基于分治思想的数据结构,它可以高效地存储和查找数据。
**算法步骤:**
1. **插入:**将新元素插入二叉搜索树,根据元素的值与根节点的值比较,递归地插入到左子树或右子树。
2. **查找:**在二叉搜索树中查找一个元素,根据元素的值与根节点的值比较,递归地查找左子树或右子树。
**代码实现:**
```python
class Node:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
class BinarySearchTree:
def __init__(self):
self.root = None
def insert(self, value):
"""
插入一个元素到二叉搜索树中
:param value: 待插入的元素值
"""
if self.root is None:
self.root = Node(value)
else:
self._insert(value, self.root)
def _insert(self, value, node):
"""
递归插入一个元素到二叉搜索树中
:param value: 待插入的元素值
:param node: 当前节点
"""
if value < node.value:
if node.left is None:
node.left = Node(value)
else:
self._insert(value, node.left)
else:
if node.right is None:
node.right = Node(value)
else:
self._insert(value, node.right)
def search(self, value):
"""
在二叉搜索树中查找一个元素
:param value: 待查找的元素值
:return: True/False
"""
if self.root is None:
return False
node = self.root
while node is not None:
if value == node.value:
return True
elif value < node.value:
node = node.left
else:
node = node.right
return False
```
**逻辑分析:**
* 第 1-3 行:定义节点类,包含值、左子树和右子树。
* 第 5-7 行:定义二叉搜索树类,包含根节点。
* 第 9-15 行:插入一个元素到二叉搜索树中,根据元素的值与根节点的值比较,递归地插入到左子树或右子树。
* 第 17-28 行:在二叉搜索树中查找一个元素,根据元素的值与根节点的值比较,递归地查找左子树或右子树。
# 4. 分治法在图论中的应用
分治法在图论中有着广泛的应用,它可以有效地解决图论中的许多问题,例如连通分量、最小生成树和最短路径。
### 4.1 分治法求解连通分量
**问题描述:**
给定一个无向图 G,求出图中所有连通分量的集合。
**分治算法:**
1. **递归基:**如果图 G 只有一个顶点,则其本身就是一个连通分量。
2. **分解:**将图 G 分解成两个子图 G1 和 G2,其中 G1 包含所有与顶点 v1 相连的顶点,G2 包含所有与顶点 v2 相连的顶点(v1 和 v2 是图 G 中任意两个不同的顶点)。
3. **求解:**递归地求解子图 G1 和 G2 中的连通分量集合。
4. **合并:**将子图 G1 和 G2 中的连通分量集合合并,得到图 G 中的连通分量集合。
**代码实现:**
```python
def connected_components(graph):
"""
求解无向图的连通分量。
参数:
graph: 无向图,用邻接表表示。
返回:
连通分量集合。
"""
def dfs(v, component):
"""
深度优先搜索,标记连通分量。
参数:
v: 当前顶点。
component: 连通分量编号。
"""
visited[v] = True
component_map[v] = component
for u in graph[v]:
if not visited[u]:
dfs(u, component)
visited = [False] * len(graph)
component_map = {}
component = 0
for v in graph:
if not visited[v]:
dfs(v, component)
component += 1
components = []
for v in graph:
if v not in components:
components.append([v])
for v in graph:
components[component_map[v]].append(v)
return components
```
**逻辑分析:**
该算法使用深度优先搜索(DFS)来标记连通分量。它从一个未访问的顶点 v1 开始,并递归地访问与 v1 相连的所有顶点。这些顶点被标记为同一个连通分量。算法继续递归地访问图中所有未访问的顶点,直到所有顶点都被标记。
### 4.2 分治法求解最小生成树
**问题描述:**
给定一个带权无向图 G,求出图 G 的最小生成树。
**分治算法:**
1. **递归基:**如果图 G 只有一个顶点,则其本身就是最小生成树。
2. **分解:**将图 G 分解成两个子图 G1 和 G2,其中 G1 包含所有与顶点 v1 相连的顶点,G2 包含所有与顶点 v2 相连的顶点(v1 和 v2 是图 G 中任意两个不同的顶点)。
3. **求解:**递归地求解子图 G1 和 G2 的最小生成树。
4. **合并:**将子图 G1 和 G2 的最小生成树合并,得到图 G 的最小生成树。
**代码实现:**
```python
def minimum_spanning_tree(graph, weights):
"""
求解带权无向图的最小生成树。
参数:
graph: 无向图,用邻接表表示。
weights: 边权重。
返回:
最小生成树的边集合。
"""
def dfs(v, tree):
"""
深度优先搜索,标记最小生成树。
参数:
v: 当前顶点。
tree: 最小生成树的边集合。
"""
visited[v] = True
for u in graph[v]:
if not visited[u]:
if (v, u) not in tree and (u, v) not in tree:
tree.add((v, u))
dfs(u, tree)
visited = [False] * len(graph)
tree = set()
for v in graph:
if not visited[v]:
dfs(v, tree)
return tree
```
**逻辑分析:**
该算法使用深度优先搜索(DFS)来标记最小生成树。它从一个未访问的顶点 v1 开始,并递归地访问与 v1 相连的所有顶点。如果当前边不在最小生成树中,则将它添加到最小生成树中。算法继续递归地访问图中所有未访问的顶点,直到所有顶点都被标记。
### 4.3 分治法求解最短路径
**问题描述:**
给定一个带权有向图 G,求出从源点 s 到所有其他顶点的最短路径。
**分治算法:**
1. **递归基:**如果图 G 只有一个顶点,则从源点 s 到该顶点的最短路径为 0。
2. **分解:**将图 G 分解成两个子图 G1 和 G2,其中 G1 包含所有从源点 s 到子图 G1 中顶点的最短路径,G2 包含所有从源点 s 到子图 G2 中顶点的最短路径。
3. **求解:**递归地求解子图 G1 和 G2 中从源点 s 到所有其他顶点的最短路径。
4. **合并:**将子图 G1 和 G2 中的最短路径合并,得到图 G 中从源点 s 到所有其他顶点的最短路径。
**代码实现:**
```python
def shortest_path(graph, weights, source):
"""
求解带权有向图从源点到所有其他顶点的最短路径。
参数:
graph: 有向图,用邻接表表示。
weights: 边权重。
source: 源点。
返回:
从源点到所有其他顶点的最短路径。
"""
def dfs(v, path):
"""
深度优先搜索,标记最短路径。
参数:
v: 当前顶点。
path: 从源点到当前顶点的最短路径。
"""
visited[v] = True
shortest_path[v] = path
for u in graph[v]:
if not visited[u]:
dfs(u, path + weights[(v, u)])
visited = [False] * len(graph)
shortest_path = [float('inf')] * len(graph)
shortest_path[source] = 0
dfs(source, 0)
return shortest_path
```
**逻辑分析:**
该算法使用深度优先搜索(DFS)来标记最短路径。它从源点 s 开始,并递归地访问与 s 相连的所有顶点。如果当前边不在最短路径中,则将它添加到最短路径中。算法继续递归地访问图中所有未访问的顶点,直到所有顶点都被标记。
# 5. 分治法在实际问题中的应用
### 5.1 分治法解决汉诺塔问题
汉诺塔问题是一个经典的数学问题,其目标是将一组塔从一个杆移动到另一个杆,每次只能移动一个塔,并且较大的塔不能放在较小的塔之上。
**分治法步骤:**
1. **递归基线:**当塔数为 1 时,直接移动到目标杆。
2. **分治:**将塔分为两部分,一部分包含最大的塔,另一部分包含其余的塔。
3. **解决子问题:**递归地将较小的塔移动到中间杆。
4. **解决原问题:**将最大的塔移动到目标杆。
5. **解决子问题:**递归地将较小的塔从中间杆移动到目标杆。
**代码:**
```python
def hanoi(n, source, destination, auxiliary):
if n == 1:
print(f"Move disk 1 from {source} to {destination}")
return
hanoi(n-1, source, auxiliary, destination)
print(f"Move disk {n} from {source} to {destination}")
hanoi(n-1, auxiliary, destination, source)
```
### 5.2 分治法解决约瑟夫环问题
约瑟夫环问题是一个数学问题,其目标是确定一个圆形队列中,从某个位置开始报数,每报到某个数字的人就会被淘汰,最后剩下的人是胜者。
**分治法步骤:**
1. **递归基线:**当环中只剩下一个人时,这个人就是胜者。
2. **分治:**将环分为两部分,一部分包含胜者,另一部分包含其余的人。
3. **解决子问题:**递归地解决较小的环,找出其胜者。
4. **解决原问题:**根据子问题的胜者位置,确定原环的胜者。
**代码:**
```python
def josephus(n, k):
if n == 1:
return 0
else:
return (josephus(n-1, k) + k) % n
```
### 5.3 分治法解决背包问题
背包问题是一个组合优化问题,其目标是将一组物品装入背包,使得背包的总价值最大,且不超过背包的容量。
**分治法步骤:**
1. **递归基线:**当物品数或背包容量为 0 时,背包价值为 0。
2. **分治:**将物品分为两部分,一部分包含最重的物品,另一部分包含其余的物品。
3. **解决子问题:**递归地解决较小的背包问题,找出不包含最重物品的背包的最大价值。
4. **解决原问题:**比较包含和不包含最重物品的背包的最大价值,选择较大的值。
**代码:**
```python
def knapsack(items, capacity):
if not items or capacity == 0:
return 0
item, weight, value = items[0]
if weight > capacity:
return knapsack(items[1:], capacity)
else:
return max(knapsack(items[1:], capacity), value + knapsack(items[1:], capacity - weight))
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了分治法,一种强大的问题解决技术,在 IT 领域中的应用。从基本思想的阐述到实战应用的指南,专栏提供了全面的分治法教程。此外,专栏还深入研究了 MySQL 数据库性能优化和数据分析技术,提供了案例解析和最佳实践,帮助读者提升技术技能。通过掌握分治法和这些先进技术,读者将能够有效解决复杂问题,提升 IT 领域的专业能力。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Expert Tips and Secrets for Reading Excel Data in MATLAB: Boost Your Data Handling Skills
# MATLAB Reading Excel Data: Expert Tips and Tricks to Elevate Your Data Handling Skills
## 1. The Theoretical Foundations of MATLAB Reading Excel Data
MATLAB offers a variety of functions and methods to read Excel data, including readtable, importdata, and xlsread. These functions allow users to
Styling Scrollbars in Qt Style Sheets: Detailed Examples on Beautifying Scrollbar Appearance with QSS
# Chapter 1: Fundamentals of Scrollbar Beautification with Qt Style Sheets
## 1.1 The Importance of Scrollbars in Qt Interface Design
As a frequently used interactive element in Qt interface design, scrollbars play a crucial role in displaying a vast amount of information within limited space. In
PyCharm Python Version Management and Version Control: Integrated Strategies for Version Management and Control
# Overview of Version Management and Version Control
Version management and version control are crucial practices in software development, allowing developers to track code changes, collaborate, and maintain the integrity of the codebase. Version management systems (like Git and Mercurial) provide
Technical Guide to Building Enterprise-level Document Management System using kkfileview
# 1.1 kkfileview Technical Overview
kkfileview is a technology designed for file previewing and management, offering rapid and convenient document browsing capabilities. Its standout feature is the support for online previews of various file formats, such as Word, Excel, PDF, and more—allowing user
Image Processing and Computer Vision Techniques in Jupyter Notebook
# Image Processing and Computer Vision Techniques in Jupyter Notebook
## Chapter 1: Introduction to Jupyter Notebook
### 2.1 What is Jupyter Notebook
Jupyter Notebook is an interactive computing environment that supports code execution, text writing, and image display. Its main features include:
-
Parallelization Techniques for Matlab Autocorrelation Function: Enhancing Efficiency in Big Data Analysis
# 1. Introduction to Matlab Autocorrelation Function
The autocorrelation function is a vital analytical tool in time-domain signal processing, capable of measuring the similarity of a signal with itself at varying time lags. In Matlab, the autocorrelation function can be calculated using the `xcorr
Statistical Tests for Model Evaluation: Using Hypothesis Testing to Compare Models
# Basic Concepts of Model Evaluation and Hypothesis Testing
## 1.1 The Importance of Model Evaluation
In the fields of data science and machine learning, model evaluation is a critical step to ensure the predictive performance of a model. Model evaluation involves not only the production of accura
Installing and Optimizing Performance of NumPy: Optimizing Post-installation Performance of NumPy
# 1. Introduction to NumPy
NumPy, short for Numerical Python, is a Python library used for scientific computing. It offers a powerful N-dimensional array object, along with efficient functions for array operations. NumPy is widely used in data science, machine learning, image processing, and scient
Analyzing Trends in Date Data from Excel Using MATLAB
# Introduction
## 1.1 Foreword
In the current era of information explosion, vast amounts of data are continuously generated and recorded. Date data, as a significant part of this, captures the changes in temporal information. By analyzing date data and performing trend analysis, we can better under
[Frontier Developments]: GAN's Latest Breakthroughs in Deepfake Domain: Understanding Future AI Trends
# 1. Introduction to Deepfakes and GANs
## 1.1 Definition and History of Deepfakes
Deepfakes, a portmanteau of "deep learning" and "fake", are technologically-altered images, audio, and videos that are lifelike thanks to the power of deep learning, particularly Generative Adversarial Networks (GANs
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )