AQS的主要设计模式和思想
发布时间: 2024-02-16 09:10:42 阅读量: 69 订阅数: 41 

设计模式,程序模式思想
# 1. 引言
## AQS的概述
AQS(AbstractQueuedSynchronizer)是Java中用于构建锁和同步器的框架,它通过一个FIFO等待队列的方式实现对共享资源的访问控制。AQS提供了一种基于模板方法模式的同步器实现,使得开发者可以相对容易地构建自定义的同步器来实现各种线程协作机制。
## AQS的重要性和应用场景
AQS作为Java并发包中锁和同步器的核心部分,被广泛应用于各种多线程的场景中。常见的锁实现类如ReentrantLock、ReentrantReadWriteLock等都是基于AQS框架实现的。AQS的重要性主要体现在以下几个方面:
- 提供了高性能的、可重入的锁实现
- 支持公平性和非公平性的锁获取方式
- 可以用于构建各种线程协作机制,如倒计时门闩、信号量等
在并发编程中,AQS的应用场景非常广泛,能够满足不同类型的需求,比如实现高性能的并发容器、实现自定义的线程协作工具等。接下来我们将对AQS的基本结构和原理进行详细介绍。
# 2. AQS的基本结构和原理
AQS(AbstractQueuedSynchronizer)是Java并发包中一个重要的同步器,它提供了一种实现锁和其他同步器的框架。AQS的核心思想是,通过维护一个同步状态(State)来实现对线程的协调与控制。
#### 2.1 Node节点的定义与使用
在AQS的实现中,Node节点是一个重要的数据结构。每个等待获取共享资源或独占资源的线程都会被封装成一个Node节点,并且连接成一个FIFO的双向链表。
Node节点的定义如下:
```java
static final class Node {
// 线程等待状态
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
// 等待状态
volatile int waitStatus;
// 前驱节点
volatile Node prev;
// 后继节点
volatile Node next;
// 等待获取资源的线程
volatile Thread thread;
// 下一个等待条件的节点
Node nextWaiter;
// 构造方法
Node(Thread thread, Node mode) {
this.thread = thread;
this.nextWaiter = mode;
}
}
```
其中,waitStatus表示节点的等待状态,prev和next分别指向当前节点的前驱和后继节点,thread表示等待获取资源的线程,nextWaiter用于条件队列中。
Node节点的使用主要体现在等待队列的维护,当线程等待获取资源时,会被封装成Node节点并加入到等待队列中。当资源释放后,会唤醒等待队列中的头节点,使其重新尝试获取资源。
#### 2.2 Condition条件队列的作用与实现
AQS内部维护了一个条件队列,用于实现线程的等待与唤醒。Condition接口提供了await()和signal()等方法,可以让线程在条件满足时等待,以及在条件变化时进行通知。
条件队列的实现依赖于Node节点和等待队列的管理。在AQS中,每个条件对象都与一个条件队列相关联。当调用Condition的await()方法时,当前线程会释放锁,并被封装成一个CONDITION类型的Node节点加入到条件队列中。当其他线程调用signal()方法时,会从条件队列中唤醒一个等待线程。
#### 2.3 State变量的含义与作用
State变量是AQS中重要的同步状态,它通过CAS(Compare and Swap)操作进行更新。在独占模式中,State变量通常用于表示获取锁的状态(0表示锁可用,1表示锁被占用)。在共享模式中,State变量通常用于表示可用的共享资源数量。
当线程获取锁时,需要通过CAS操作来修改State变量的值,表示锁的占用情况。当线程释放锁时,也需要通过CAS操作来恢复State变量的值,以便其他线程能够获取到锁。
#### 2.4 AQS的互斥性和共享性
AQS具有互斥性和共享性,通过对State变量的不同处理来实现。
在独占模式下,AQS通过维护一个同步状态(State)来实现互斥锁的获取与释放。当一个线程成功获取到锁时,State变量的值被设置为1,表示锁被占用。其他线程需要等待该线程释放锁后才能获取到锁。
在共享模式下,AQS也通过维护一个同步状态(State)来实现共享锁的获取与释放。不同于独占模式,共享模式下的State变量可以表示多个共享资源的数量。当一个线程成功获取到共享资源时,State变量的值会相应减少,表示资源被占用。其他线程可以同时获取到剩余的共享资源。
AQS的互斥性和共享性为我们提供了一种灵活的同步机制,可以满足不同场景下对锁的需求。接下来,我们将分别介绍AQS的独占模式和共享模式的详细实现原理。
# 3. AQS的基本结构和原理
在这一节中,我们将深入探讨AQS(AbstractQueuedSynchronizer)的基本结构和原理。AQS是Java中并发编程领域中非常重要的一部分,其深刻影响了许多并发工具类的设计和实现。
#### 3.1 Node节点的定义与使用
AQS内部通过`Node`节点来实现线程的排队和等待,`Node`节点是AQS中的核心数据结构之一。每个线程在尝试获取锁的时候,都会被封装成一个`Node`节点,然后加入到AQS维护的队列中,这个队列被称为等待队列。`Node`节点的定义如下(Java语言):
```java
static final class Node {
// 实际上就是对线程的封装
Thread thread;
// 前驱节点
Node prev;
// 后继节点
Node next;
// 等待状态,用于标识节点的状态,如独占模式和共享模式
int waitStatus;
}
```
`Node`节点在AQS中的使用主要体现在构建等待队列、线程的排队和唤醒等操作上。
#### 3.2 Condition条件队列的作用与实现
AQS中的`Condition`对象通过条件队列来管理等待在某个条件上的线程。条件队列是通过`AbstractQueuedSynchronizer`内部的`Condition`对象来实现的。`Condition`的实现主要基于`Node`节点的操作,如入队、出队、唤醒等。
#### 3.3 State变量的含义与作用
`AbstractQueuedSynchronizer`内部的`state`变量是AQS的核心之一,它代表共享资源的状态。在独占模式下,`state`通常表示锁的状态(1表示已被占用,0表示未占用);在共享模式下,`state`通常表示锁的可重入次数。通过对`state`的操作,可以实现对共享资源的安全访问。
#### 3.4 AQS的互斥性和共享性
AQS既支持独占模式,也支持共享模式,因此具备互斥性和共享性。通过使用`tryAcquire`和`tryRelease`方法实现独占模式下的互斥访问,以及使用`tryAcquireShared`和`tryReleaseShared`方法实现共享模式下的共享访问。
在下一节中,我们将重点介绍AQS的独占模式,包括其获取与释放过程以及相关方法的实现原理。
# 4. AQS的共享模式
在前面的章节中,我们已经介绍了AQS的独占模式,本章将探讨AQS的共享模式。与独占模式不同,共享模式允许多个线程同时获取同一个资源,从而提高并发性能。
### 共享锁的获取与释放过程
在AQS中,共享锁的获取和释放过程与独占锁类似,都是通过acquire和release方法实现的。不同之处在于,AQS中的共享锁可以被多个线程同时获取。
共享锁的获取过程如下:
1. 当一个线程想要获取共享锁时,它会调用AQS的acquireShared方法。
2. 在acquireShared方法中,线程会先调用tryAcquireShared方法,尝试获取锁资源。
3. 如果tryAcquireShared返回一个负数,表示获取锁失败,线程会被加入到等待队列中。
4. 如果tryAcquireShared返回0,表示获取锁成功,线程可以继续往下执行。
5. 如果tryAcquireShared返回一个正数,表示获取锁成功,但还需要和其他线程竞争资源。此时,线程会进入阻塞状态,等待其他线程释放锁资源。
6. 一旦所有线程都释放了锁资源,等待队列中的线程都会被唤醒,它们可以再次尝试获取锁资源。
共享锁的释放过程如下:
1. 当一个线程释放共享锁时,它会调用AQS的releaseShared方法。
2. 在releaseShared方法中,线程会先调用tryReleaseShared方法,尝试释放锁资源。
3. 如果tryReleaseShared返回true,表示释放锁成功。
4. 释放锁成功后,AQS会唤醒等待队列中的某个线程,让它尝试获取锁资源。
### AQS的tryAcquireShared和tryReleaseShared方法的实现原理
在AQS中,tryAcquireShared方法和tryReleaseShared方法是实现共享锁的关键。它们的具体实现可以根据业务需求进行定制。
tryAcquireShared方法的默认实现是返回一个负数,表示获取锁失败。而tryReleaseShared方法的默认实现是抛出一个UnsupportedOperationException异常,表示释放锁失败。
如果我们想使用AQS的共享功能,我们需要重写tryAcquireShared和tryReleaseShared方法来实现实际的共享逻辑。例如,我们可以使用一个共享变量来表示锁的状态,在tryAcquireShared方法中判断锁是否可用,在tryReleaseShared方法中释放锁资源。
### 共享锁的公平性和非公平性
AQS中的共享锁可以是公平的或非公平的。在公平模式下,多个线程按照请求锁的顺序获取锁资源;在非公平模式下,多个线程可以随机竞争锁资源。
通过在构造方法中传入一个布尔值来指定锁的公平性。如果传入true,表示锁是公平的;如果传入false,表示锁是非公平的。默认情况下,AQS使用非公平锁。
公平锁的好处是能够保证每个线程都能有机会获取锁资源,避免线程饥饿现象的发生。但是,公平锁的性能相对较低,因为需要维护一个有序的等待队列。
非公平锁的好处是可以减少锁的竞争,从而提高性能。但是,非公平锁可能导致某些线程一直获取不到锁资源,造成线程饥饿现象。
在实际应用中,我们需要根据具体的场景选择合适的公平性策略。
本章节介绍了AQS的共享模式,包括共享锁的获取与释放过程,AQS的tryAcquireShared和tryReleaseShared方法的实现原理,以及共享锁的公平性和非公平性。通过理解和掌握AQS的共享模式,我们能够更好地利用同步器来提高并发性能。
# 5. AQS的扩展模式
AQS作为java.util.concurrent包中锁和同步器的基础框架,提供了基本的独占和共享模式的同步器实现,但有时候我们需要更加灵活的同步器来满足特定的需求,因此可以通过扩展AQS来实现自定义的同步器。
#### 扩展AQS的方法和策略
要实现自定义的同步器,一般需要遵循以下步骤和策略:
1. **继承AQS类**:首先创建一个新的类,继承AbstractQueuedSynchronizer,这个类将提供AQS的基本结构和原子操作。
2. **重写AQS的方法**:根据具体的需求,重写tryAcquire、tryRelease、tryAcquireShared、tryReleaseShared等方法,这些方法将控制同步器的状态和线程的获取和释放。
3. **管理同步状态**:通过维护同步器的状态变量state,控制线程的获取和释放。在扩展AQS时,需要考虑好state的含义和使用方式。
4. **实现条件队列**:如果需要支持条件等待,可以考虑实现Condition接口,创建条件队列来管理等待的线程。
5. **考虑并发性和可靠性**:在实现自定义同步器时,需要考虑并发情况下的线程安全性和可靠性,确保同步器能够正确地协调多个线程的并发操作。
#### 自定义同步器的实现步骤和注意事项
实现自定义同步器时,可以按照以下步骤进行:
1. 定义同步器的状态变量state:state可以表示获取资源的数量、是否被占用等状态,根据具体需求定义好state的含义。
2. 实现acquire和release方法:根据自定义同步器的性质,实现acquire和release方法来控制线程的获取和释放方式。
3. 考虑并发情况下的线程安全性:确保在多线程并发操作时,自定义同步器能够正确地协调线程的获取和释放,避免出现死锁或竞态条件等问题。
4. 派生子类:如果需要支持条件等待,可以派生子类来实现Condition接口,提供条件队列的管理和相关操作。
5. 测试验证:编写测试用例,验证自定义同步器在多线程并发场景下的正确性和性能。
#### 示例:实现自定义同步器
下面是一个简单的示例,演示了如何通过继承AQS类并重写tryAcquire和tryRelease方法来实现自定义的同步器:
```java
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
public class CustomSync extends AbstractQueuedSynchronizer {
// 尝试获取独占锁,成功返回true,失败返回false
@Override
protected boolean tryAcquire(int arg) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// 尝试释放独占锁
@Override
protected boolean tryRelease(int arg) {
if (getState() == 0) {
throw new IllegalMonitorStateException();
}
setExclusiveOwnerThread(null);
setState(0);
return true;
}
}
```
在这个示例中,我们通过继承AbstractQueuedSynchronizer,并重写tryAcquire和tryRelease方法,实现了一个简单的独占锁的同步器。当state为0时表示锁空闲,可以成功获取锁;当state为1时表示锁被占用,需要释放锁才能让其他线程获取。
通过以上步骤,可以实现一个基本的自定义同步器,满足特定的需求。
在实际应用中,我们可以根据具体的业务场景和需求,实现更加复杂和灵活的自定义同步器,来解决各种并发控制的问题。
以上是自定义同步器的基本实现步骤和注意事项,通过扩展AQS,我们可以实现灵活多样的同步器,满足不同的并发控制需求。
# 6. AQS的扩展模式
在前面的章节中,我们已经了解了AQS的基本结构和原理,以及其在独占模式和共享模式下的使用。在本章中,我们将探讨如何扩展AQS,以及自定义同步器的实现步骤和注意事项。
### 扩展AQS的方法和策略
AQS提供了一些可以供子类重写的protected方法,可以用来实现不同的同步场景。下面是一些常用的方法:
- `tryAcquire(int arg)`:尝试以独占模式获取同步状态。返回值表示是否成功获取同步状态。
- `tryRelease(int arg)`:尝试以独占模式释放同步状态。返回值表示释放后是否需要唤醒后继线程。
- `tryAcquireShared(int arg)`:尝试以共享模式获取同步状态。返回值表示是否成功获取同步状态。
- `tryReleaseShared(int arg)`:尝试以共享模式释放同步状态。返回值表示释放后是否需要唤醒后继线程。
- `isHeldExclusively()`:判断当前线程是否独占持有同步状态。
通过重写这些方法,可以实现自定义的同步器,并根据具体的需求来定义同步的策略。
### 自定义同步器的实现步骤和注意事项
要实现自定义的同步器,需要按照以下步骤进行:
1. 定义一个静态内部类,继承`AbstractQueuedSynchronizer`类,并实现需要重写的方法。例如:
```java
/**
* 自定义同步器
*/
private static class MySync extends AbstractQueuedSynchronizer {
// 省略具体实现...
}
```
2. 在自定义同步器的类中,提供对外暴露的方法。例如:
```java
/**
* 获取锁
*/
public void lock() {
sync.acquire(1);
}
/**
* 释放锁
*/
public void unlock() {
sync.release(1);
}
```
3. 在需要使用同步器的类中,创建一个同步器的实例,并在需要同步的方法中调用该实例的方法。例如:
```java
/**
* 使用自定义同步器的类
*/
public class MyClass {
// 创建自定义同步器实例
private MySync sync = new MySync();
// 需要同步的方法
public void doSomething() {
// 获取锁
sync.acquire(1);
try {
// 业务逻辑...
} finally {
// 释放锁
sync.release(1);
}
}
}
```
在实现自定义同步器时,需要注意以下事项:
- 状态的管理:根据具体场景需要考虑同步状态的维护和更新。
- 状态的获取和释放:通过重写`tryAcquire`、`tryRelease`等方法来实现状态的获取和释放逻辑。
- 锁的获取和释放:通过调用同步器的`acquire`、`release`等方法来实现锁的获取和释放。
### 示例:实现自定义同步器
下面通过一个简单的示例来演示如何实现自定义同步器。我们实现一个简单的计数器类,只允许一个线程进行自增操作,其他线程需等待。
```java
/**
* 自定义同步器示例
*/
public class MySync extends AbstractQueuedSynchronizer {
private volatile int count;
/**
* 尝试获取同步状态(独占模式)
*/
protected boolean tryAcquire(int arg) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
/**
* 尝试释放同步状态(独占模式)
*/
protected boolean tryRelease(int arg) {
if (getState() == 0) {
throw new IllegalMonitorStateException();
}
setExclusiveOwnerThread(null);
setState(0);
return true;
}
/**
* 获取计数值
*/
public int getCount() {
return count;
}
/**
* 自增操作
*/
public void increase() {
// 获取同步状态
acquire(1);
try {
count++;
} finally {
// 释放同步状态
release(1);
}
}
}
```
在上述示例中,我们通过重写`tryAcquire`和`tryRelease`方法,实现了独占模式下的自增操作。其他线程在调用`increase`方法时,会以独占模式获取同步状态,保证只有一个线程可以进行自增操作。
```java
public class Main {
public static void main(String[] args) {
MySync sync = new MySync();
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
executor.execute(() -> {
sync.increase();
System.out.println(Thread.currentThread().getName() + ": " + sync.getCount());
});
}
executor.shutdown();
}
}
```
运行以上代码,我们可以看到线程执行自增操作并输出计数值。由于同步器的限制,每次只有一个线程可以进行自增操作,其他线程需要等待。
### 小结
通过扩展AQS和自定义同步器,我们可以实现更加灵活的同步机制。自定义同步器可以根据具体的场景和需求来设计同步策略,提升性能和可维护性。下一章中,我们将介绍一些使用AQS实现的常见同步工具类,例如`ReentrantLock`和`ReentrantReadWriteLock`,以及它们的原理和应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏是Java并发编程系列,通过对AQS(AbstractQueuedSynchronizer)源码的解析,深入探讨了AQS的背景、原理和各种实现方式。其中包括了AQS的简介和背景介绍,以及具体讲解了ReentrantLock、ReadWriteLock与ReentrantReadWriteLock、StampedLock、AbstractQueuedSynchronizer类、Node与CLH锁队列、底层的state变量与方法、锁的获取与释放、公平锁与非公平锁、Condition队列的使用与实现、Semaphore的实现原理、CountDownLatch的实现原理以及StampedLock的实现原理等。通过这些文章的阅读,读者可以更加深入地理解AQS的工作原理与内部机制,对于Java并发编程有更全面的认识。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【刷机安全教程】:如何安全地刷Kindle Fire HDX7 三代
# 摘要
本文旨在提供关于刷机操作的全面基础知识与实践指南。从准备刷机工作环境的细节,如设备兼容性确认、软件获取和数据备份,到详细的刷机流程,包括Bootloader解锁、刷机包安装及系统引导与设置,本文深入讨论了刷机过程中的关键步骤和潜在风险。此外,本文还探讨了刷机后的安全加固、性能调优和个性化定制,以及故障诊断与恢复方法,为用户确保刷机成功和设备安全性提供了实用的策略和技巧。
# 关键字
刷机;设备兼容性;数据备份;Bootloader解锁;系统引导;故障诊断
参考资源链接:[Kindle Fire HDX7三代救砖教程:含7.1.2刷机包与驱动安装](https://wenku.cs
【RN8209D电源管理技巧】:打造高效低耗的系统方案

# 摘要
本文综合介绍RN8209D电源管理芯片的功能与应用,概述其在不同领域内的配置和优化实践。通过对电源管理基础理论的探讨,本文阐释了电源管理对系统性能的重要性,分析了关键参数和设计中的常见问题,并给出了相应的解决方案。文章还详细介绍了RN8209D的配置方
C#设计模式:解决软件问题的23种利器
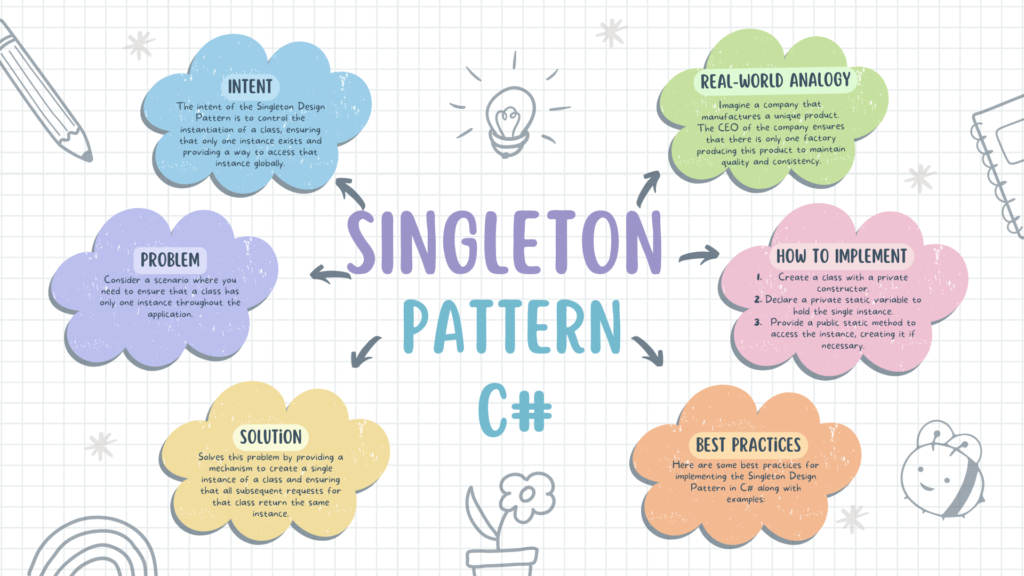
# 摘要
设计模式作为软件工程中的一种重要方法论,对于提高代码的可重用性、可维护性以及降低系统的复杂性具有至关重要的作用。本文首先概述了设计模式的重要性及其在软件开发中的基础地位。随后,通过深入探讨创建型、结构型和行为型三种设计模式,本文分析了每种模式的理论基础、实现技巧及其在实际开发中的应用。文章强调了设计模式在现代软件开发中的实际应用,如代码复用、软件维护和架构设计,并提供了相关模式的选择和运用策略
【性能基准测试】:极智AI与商汤OpenPPL在实时视频分析中的终极较量

# 摘要
实时视频分析技术在智能监控、安全验证和内容分析等多个领域发挥着越来越重要的作用。本文从实时视频分析技术的性能基准测试出发,对比分析了极智AI和商汤OpenPPL的技术原理、性能指标以及实践案例。通过对关键性能指标的对比,详细探讨了两者的性能优势与劣势。文章进一步提出了针对两大技术的性能优化策略,并预测了实时视频分析技术的未来发展趋势及其面临的挑战。研究发现,硬件加速技术和软件算法优化是提升实时视频
【24小时精通安川机器人】:新手必读的快速入门秘籍与实践指南

# 摘要
安川机器人作为自动化领域的重要工具,在工业生产和特定行业应用中发挥着关键作用。本文首先概述了安川机器人的应用领域及其在不同行业的应用实例。随后,探讨了安川机器人的基本操作和编程基础,包括硬件组成、软件环境和移动编程技术。接着,深入介绍了安川机器人的高级编程技术,如数据处理、视觉系统集成和网络通信,这些技术为机器人提供了更复杂的功能和更高的灵活性。
【定时器应用全解析】:单片机定时与计数,技巧大公开!

# 摘要
本文深入探讨了定时器的基础理论及其在单片机中的应用。首先介绍了定时器的基本概念、与计数器的区别,以及单片机定时器的内部结构和工作模式。随后,文章详细阐述了单片机定时器编程的基本技巧,包括初始化设置、中断处理和高级应用。第四章通过实时时钟、电机控制和数据采集等实例分析了定时器的实际应用。最后,文章探讨了定时器调试与优化的方法,并展望了定时器技术的未来发展趋势,特别是高精度定时器和物联网应用的可能性
【VIVADO逻辑分析高级应用】:掌握高级逻辑分析在VIVADO中的技巧
# 摘要
本文旨在全面介绍VIVADO逻辑分析工具的基础知识与高级应用。首先,概述了VIVADO逻辑分析的基本概念,并详细阐述了其高级工具,如Xilinx Analyzer的界面操作及高级功能、时序分析与功耗分析的基本原理和高级技巧。接着,文章通过实践应用章节,探讨了FPGA调试、性能分析以及资源管理的策略和方法。最后,文章进一步探讨了
深度剖析四位全加器:计算机组成原理实验的不二法门

# 摘要
四位全加器作为数字电路设计的基础组件,在计算机组成原理和数字系统中有广泛应用。本文详细阐述了四位全加器的基本概念、逻辑设计方法以及实践应用,并进一步探讨了其在并行加法器设
高通modem搜网注册流程的性能调优:影响因素与改进方案(实用技巧汇总)

# 摘要
本文全面概述了高通modem搜网注册流程,包括其技术原理、性能影响因素以及优化实践。搜网技术原理的深入分析为理解搜网流程提供了基础,而性能影响因素的探讨涵盖了硬件、软件和网络环境的多维度考量。理论模型与实际应用的差异进一步揭示了搜网注册流程的复杂性。文章重点介绍了性能优化的方法、实践案例以及优化效果的验证分析。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )