Best Practices for Elasticsearch Data Modeling: Optimizing Search Performance and Relevance
发布时间: 2024-09-13 20:14:56 阅读量: 17 订阅数: 23 
# Elasticsearch Data Modeling Best Practices: Optimizing Search Performance and Relevance
## 1. Overview of Elasticsearch Data Modeling
Elasticsearch data modeling refers to the method of designing and organizing data to optimize search and analytics performance. It involves defining document structures, choosing data types, establishing relationships, and optimizing index settings.
Data modeling is crucial in Elasticsearch as it affects query speed, relevance, storage efficiency, and scalability. By employing appropriate data modeling techniques, one can maximize Elasticsearch's performance and provide users with efficient search and analysis experiences.
## 2. Data Modeling Principles and Practices
### 2.1 Data Standardization and Normalization
#### 2.1.1 Benefits of Data Standardization
Data standardization involves storing data in multiple tables, with each table containing information about a specific topic or entity. The advantages include:
- **Reducing redundancy:** The same data is not stored in multiple tables, thus saving storage space and reducing maintenance costs.
- **Improving data integrity:** When data is updated, only one table needs to be updated, ensuring consistency.
- **Enhancing query efficiency:** By storing related data in different tables, specific information can be queried more effectively.
#### 2.1.2 Different Forms of Normalization
Normalization is another technique for organizing data into multiple tables aimed at eliminating redundancy and ensuring data integrity. There are three primary forms of normalization:
- **First Normal Form (1NF):** Each row in a table represents a unique entity with no duplicate columns.
- **Second Normal Form (2NF):** Each row in a table depends on the table's primary key and has no partial dependencies.
- **Third Normal Form (3NF):** Each row in a table depends on the table's primary key and has no transitive dependencies.
### 2.2 Selection of Data Types and Indexing Strategies
#### 2.2.1 Characteristics of Different Data Types
Elasticsearch supports multiple data types, each with its unique characteristics and uses:
| Data Type | Characteristics | Usage |
|---|---|---|
| Text | Can store text, numbers, and dates | Used for full-text search and analysis |
| Number | Can store integers, floats, and dates | Used for numerical calculations and sorting |
| Date | Can store dates and times | Used for timestamps and date range queries |
| Boolean | Can store true or false | Used for Boolean filtering and aggregations |
| Object | Can store nested data structures | Used to represent complex objects and relationships |
| Array | Can store a set of values | Used to represent lists and collections |
#### 2.2.2 Optimizing Indexing Strategies
An index is a structure used by Elasticsearch to search and retrieve data quickly. Optimizing indexing strategies can significantly improve query performance:
- **Choose the correct index type:** Elasticsearch supports various index types, including standard, inverted, and geospatial indices. Choosing the correct index type is crucial for optimizing query efficiency.
- **Adjust index parameters:** Index parameters, such as the number of shards, replicas, and refresh intervals, can be tailored according to data volume and query patterns. Optimizing these parameters can enhance index performance and reliability.
**Code Example:**
```json
{
"settings": {
"index": {
"number_of_shards": 5,
"number_of_replicas": 1,
"refresh_interval": "1s"
}
}
}
```
**Logical Analysis:**
This code block defines index settings, including the number of shards, replicas, and the refresh interval. The number of shards controls the distribution of data within the index, replicas provide redundancy and availability, and the refresh interval specifies how often Elasticsearch refreshes the index.
## 3.1 Document Structure Optimization
#### 3.1.1 Pros and Cons of Nested and Nested Objects
Nested is the process of representing a field within a document as an array of other documents. This is very useful for representing hierarchical data, such as prod

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
大样本理论在假设检验中的应用:中心极限定理的力量与实践

# 1. 中心极限定理的理论基础
## 1.1 概率论的开篇
概率论是数学的一个分支,它研究随机事件及其发生的可能性。中心极限定理是概率论中最重要的定理之一,它描述了在一定条件下,大量独立随机变量之和(或平均值)的分布趋向于正态分布的性
【置信区间计算秘籍】:统计分析必备技能指南
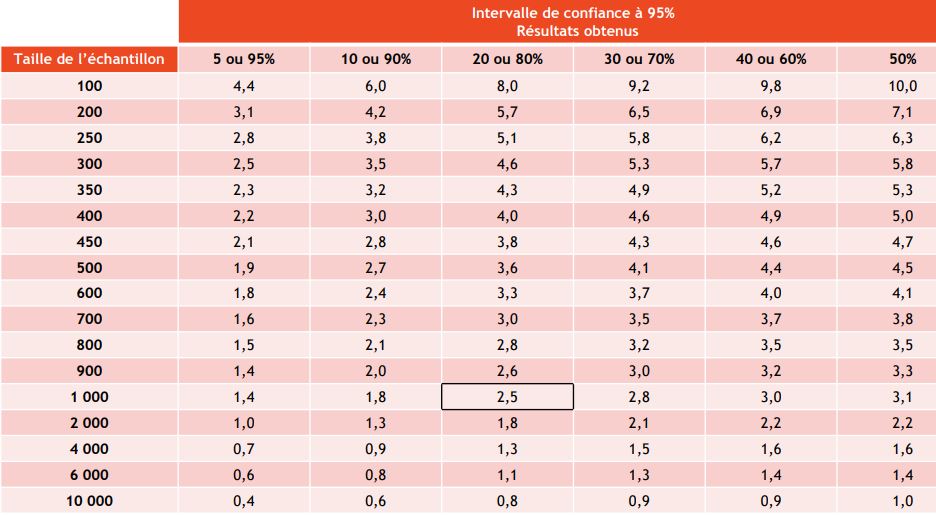
# 1. 置信区间的统计学基础
## 1.1 统计学中的置信概念
在统计学中,"置信区间"是一个重要的概念,用于表达对总体参数(如均值、比例等)的估计。简单来说,如果从同一总体中重复抽样很多次,并为每个样本构建一个区间估计,那么这些区间中有一定比例(如95%)会包含真实的总体参数。这个区间,就被称为置信区间。
## 1.2 置信区间的目的和意义
置信区间的目的是为了给出
正态分布与信号处理:噪声模型的正态分布应用解析

# 1. 正态分布的基础理论
正态分布,又称为高斯分布,是一种在自然界和社会科学中广泛存在的统计分布。其因数学表达形式简洁且具有重要的统计意义而广受关注。本章节我们将从以下几个方面对正态分布的基础理论进行探讨。
## 正态分布的数学定义
正态分布可以用参数均值(μ)和标准差(σ)完全描述,其概率密度函数(PDF)表达式为:
```math
f(x|\mu,\sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} e
【品牌化的可视化效果】:Seaborn样式管理的艺术

# 1. Seaborn概述与数据可视化基础
## 1.1 Seaborn的诞生与重要性
Seaborn是一个基于Python的统计绘图库,它提供了一个高级接口来绘制吸引人的和信息丰富的统计图形。与Matplotlib等绘图库相比,Seaborn在很多方面提供了更为简洁的API,尤其是在绘制具有多个变量的图表时,通过引入额外的主题和调色板功能,大大简化了绘图的过程。Seaborn在数据科学领域得
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
【线性回归时间序列预测】:掌握步骤与技巧,预测未来不是梦
# 1. 线性回归时间序列预测概述
## 1.1 预测方法简介
线性回归作为统计学中的一种基础而强大的工具,被广泛应用于时间序列预测。它通过分析变量之间的关系来预测未来的数据点。时间序列预测是指利用历史时间点上的数据来预测未来某个时间点上的数据。
## 1.2 时间序列预测的重要性
在金融分析、库存管理、经济预测等领域,时间序列预测的准确性对于制定战略和决策具有重要意义。线性回归方法因其简单性和解释性,成为这一领域中一个不可或缺的工具。
## 1.3 线性回归模型的适用场景
尽管线性回归在处理非线性关系时存在局限,但在许多情况下,线性模型可以提供足够的准确度,并且计算效率高。本章将介绍线
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
从Python脚本到交互式图表:Matplotlib的应用案例,让数据生动起来

# 1. Matplotlib的安装与基础配置
在这一章中,我们将首先讨论如何安装Matplotlib,这是一个广泛使用的Python绘图库,它是数据可视化项目中的一个核心工具。我们将介绍适用于各种操作系统的安装方法,并确保读者可以无痛地开始使用Matplotlib
数据清洗的概率分布理解:数据背后的分布特性

# 1. 数据清洗的概述和重要性
数据清洗是数据预处理的一个关键环节,它直接关系到数据分析和挖掘的准确性和有效性。在大数据时代,数据清洗的地位尤为重要,因为数据量巨大且复杂性高,清洗过程的优劣可以显著影响最终结果的质量。
## 1.1 数据清洗的目的
数据清洗
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )