Trie树:高效字典匹配算法与实战场景
发布时间: 2024-04-02 16:27:36 阅读量: 74 订阅数: 22 
# 1. 介绍Trie树
Trie树,又称字典树或前缀树,是一种专门用于处理字符串匹配的数据结构。在实际编程中,Trie树常被用于搜索引擎、拼写检查、路由表等领域,并且在处理大量字符串时性能优势明显。本章将介绍Trie树的定义、基本特点以及在实际应用场景中的作用。接下来将详细阐述Trie树结构、节点表示方法以及常见的应用场景,为后续章节的内容打下基础。
# 2. Trie树的构建与插入操作
Trie树是一种高效的数据结构,常用于实现字典匹配和前缀搜索等功能。在本章中,将详细介绍Trie树的构建方法以及插入操作的实现及优化策略。
### 2.1 Trie树的构建算法
Trie树的构建算法主要包括初始化Trie树根节点和逐层插入单词的过程。下面是Java实现的伪代码示例:
```java
class TrieNode {
Map<Character, TrieNode> children;
boolean isEndOfWord;
public TrieNode() {
children = new HashMap<>();
isEndOfWord = false;
}
}
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
TrieNode node = root;
for (char ch : word.toCharArray()) {
node.children.putIfAbsent(ch, new TrieNode());
node = node.children.get(ch);
}
node.isEndOfWord = true;
}
}
// 构建Trie树
Trie trie = new Trie();
trie.insert("apple");
trie.insert("banana");
```
### 2.2 插入操作的实现与优化策略
在进行插入操作时,可以结合路径压缩和公共前缀合并等技巧来优化Trie树的构建过程,减少内存消耗并提升性能。以下是Python实现的插入操作代码示例:
```python
class TrieNode:
def __init__(self):
self.children = {}
self.is_end_of_word = False
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word):
node = self.root
for ch in word:
if ch not in node.children:
node.children[ch] = TrieNode()
node = node.children[ch]
node.is_end_of_word = True
# 构建Trie树
trie = Trie()
trie.insert("apple")
trie.insert("banana")
```
### 2.3 时间复杂度分析与性能评估
对于Trie树的构建和插入操作,时间复杂度取决于单词的长度和Trie树的高度,通常为O(m),其中m为单词的长度。通过合理设计Trie树的节点结构和插入算法,可以在保证空间效率的前提下,实现高效的单词插入操作。
在实际应用中,可以通过压缩Trie树、节点合并和剪枝等方式来进一步优化Trie树的性能,提升字典匹配和前缀搜索的效率。
# 3. Trie树的查找与前缀匹配
Trie树作为一种高效的搜索数据结构,在查找和前缀匹配方面具有独特的优势。本章将深入探讨Trie树的查找算法和如何实现基于Trie树的高效前缀匹配功能。
#### 3.1 查找操作的实现方法
Trie树的查找操作与插入

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 C++ 中二叉树的遍历算法,涵盖了初识二叉树、创建与遍历、前序、中序、后序、层次、Morris、迭代与递归等多种遍历方式,深入探讨了算法原理、应用场景和性能分析。此外,专栏还拓展到了树形结构的应用实例、常用树形数据结构、平衡二叉树、红黑树、AVL 树、B 树、B+ 树、哈夫曼树、树状数组和线段树等高级树形结构,为读者提供了深入理解和应用树形结构的全面指南。通过阅读本专栏,读者将掌握二叉树遍历的精髓,并了解树形结构在实际开发中的广泛应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深度剖析Renren Security:功能模块背后的架构秘密

# 摘要
Renren Security是一个全面的安全框架,旨在为Web应用提供强大的安全保护。本文全面介绍了Renren Security的核心架构、设计理念、关键模块、集成方式、实战应用以及高级特性。重点分析了认证授权机制、过滤器链设计、安全拦截器的运作原理和集成方法。通过对真实案例的深入剖析,本文展示了Renren Security在实际应用中的效能,并探讨了性能优化和安全监
电力系统稳定性分析:PSCAD仿真中的IEEE 30节点案例解析
# 摘要
本文详细探讨了电力系统稳定性及其在仿真环境中的应用,特别是利用PSCAD仿真工具对IEEE 30节点系统进行建模和分析。文章首先界定了电力系统稳定性的重要性并概述了仿真技术,然后深入分析了IEEE 30节点系统的结构、参数及稳定性要求。在介绍了PSCAD的功能和操作后,本文通过案例展示了如何在PSCAD中设置和运行IEEE 30节点模型,进行稳定性分析,并基于理论对仿真结果进行了详细分析
Infovision iPark高可用性部署:专家传授服务不间断策略
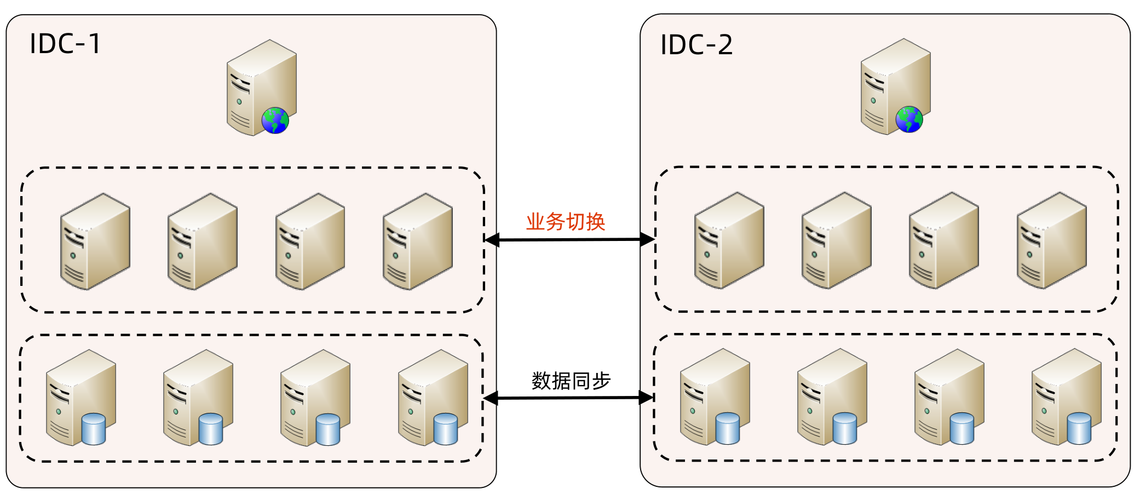
# 摘要
Infovision iPark作为一款智能停车系统解决方案,以其高可用性的设计,能够有效应对不同行业特别是金融、医疗及政府公共服务行业的业务连续性需求。本文首先介绍了Infovision iPark的基础架构和高可用性理论基础,包括高可用性的定义、核心价值及设计原则。其次,详细阐述了Infovision iPark在实际部署中的高可用性实践,包括环境配
USCAR38供应链管理:平衡质量与交付的7个技巧

# 摘要
供应链管理作为确保产品从原材料到终端用户高效流动的复杂过程,其核心在于平衡质量与交付速度。USCAR38的供应链管理概述了供应链管理的理论基础和实践技巧,同时着重于质量与交付之间的平衡挑战。本文深入探讨了供应链流程的优化、风险应对策略以及信息技术和自动化技术的应用。通过案例研究,文章分析了在实践中平衡质量与交付的成功与失败经验,并对供应链管理的未来发展趋
组合数学与算法设计:卢开澄第四版60页的精髓解析
# 摘要
本文系统地探讨了组合数学与算法设计的基本原理和方法。首先概述了算法设计的核心概念,随后对算法分析的基础进行了详细讨论,包括时间复杂度和空间复杂度的度量,以及渐进符号的使用。第三章深入介绍了组合数学中的基本计数原理和高级技术,如生成函数和容斥原理。第四章转向图论基础,探讨了图的基本性质、遍历算法和最短路径问题的解决方法。第五章重点讲解了动态规划和贪心算法,以及它们在
【Tomcat性能优化实战】:打造高效稳定的Java应用服务器

# 摘要
本文旨在深入分析并实践Tomcat性能优化方法。首先,文章概述了Tomcat的性能优化概览,随后详细解析了Tomcat的工作原理及性能
【BIOS画面定制101】:AMI BIOS初学者的完全指南
# 摘要
本文介绍了AMI BIOS的基础知识、设置、高级优化、界面定制以及故障排除与问题解决等关键方面。首先,概述了BIOS的功能和设置基础,接着深入探讨了性能调整、安全性配置、系统恢复和故障排除等高级设置。文章还讲述了BIOS画面定制的基本原理和实践技巧,包括界面布局调整和BIOS皮肤的更换、设计及优化。最后,详细介绍了BIOS更新、回滚、错误解决和长期维护
易康eCognition自动化流程设计:面向对象分类的优化路径

# 摘要
本文综述了易康eCognition在自动化流程设计方面的应用,并详细探讨了面向对象分类的理论基础、实践方法、案例研究、挑战与机遇以及未来发展趋势。文中从地物分类的概念出发,分析了面向对象分类的原理和精度评估方法。随后,通过实践章节展示如何在不同领域中应用易康eCognition进行流程设计和高级分类技术的实现。案例研究部分提供了城市用地、森林资
【变频器通讯高级诊断策略】:MD800系列故障快速定位与解决之道

# 摘要
本文系统阐述了变频器通讯的原理与功能,深入分析了MD800系列变频器的技术架构,包括其硬件组成、软件架构以及通讯高级功能。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )