Unveiling 10 Key Performance Optimization Tips for MATLAB to Read Excel Data: Speed Increase by 10 Times
发布时间: 2024-09-15 15:21:43 阅读量: 30 订阅数: 31 

Unveiling-the-ActiLife-Algorithm--Converting-Raw-Acceleration-Data-to-Activity-Count:2015年无线健康大会论文
# Unveiling 10 Tips for Optimizing MATLAB's Performance in Reading Excel Data: A 10-Fold Speed-Up
## 1. Basic MATLAB Excel Data Reading
MATLAB provides various methods to read data from Excel files, including the use of `readtable`, `xlsread`, and `importdata` functions. The `readtable` function is the most versatile, capable of reading Excel tables, ranges, and named ranges. The `xlsread` function is specifically designed for reading Excel worksheets, while the `importdata` function can import data from various sources, including Excel files.
When selecting a reading method, consider the following factors:
- **Data Size:** For large datasets, using the `readtable` function might be more efficient as it supports parallel reading.
- **Data Type:** The `readtable` function can automatically detect data types, whereas the `xlsread` function requires manual specification of data types.
- **Data Format:** The `readtable` function can read Excel tables, ranges, and named ranges, while the `xlsread` function can only read Excel worksheets.
## 2. Data Reading Optimization Techniques
### 2.1 Data Type Conversion Optimization
**2.1.1 Avoid Using String Data Type**
The string data type occupies a large amount of memory in MATLAB and processes at a slower speed. When reading Excel data, if the data is inherently numeric, avoid converting it into a string type.
```
% Read Excel data as string type
data_str = readtable('data.xlsx');
% Read Excel data as numeric type
data_num = readtable('data.xlsx', 'ReadVariableNames', false);
```
**2.1.2 Use Appropriate Numeric Data Types**
MATLAB offers various numeric data types, such as int8, int16, int32, int64, single, double, etc. When reading Excel data, an appropriate numeric data type should be selected based on the range and precision of the data.
```
% Read Excel data as int32 type
data_int32 = readtable('data.xlsx', 'ReadVariableNames', false, 'DataType', 'int32');
% Read Excel data as double type
data_double = readtable('data.xlsx', 'ReadVariableNames', false, 'DataType', 'double');
```
### 2.2 File Reading and Writing Optimization
**2.2.1 Use Read and Write Caching**
Read and write caching can reduce the number of file read/write operations, improving the speed of reading and writing.
```
% Use read and write caching to read Excel data
data = readtable('data.xlsx', 'ReadVariableNames', false, 'UseReadCache', true);
% Use read and write caching to write Excel data
writetable(data, 'data_out.xlsx', 'WriteVariableNames', false, 'UseWriteCache', true);
```
**2.2.2 Avoid Frequently Opening and Closing Files**
Frequently opening and closing files consume a significant amount of time. When reading or writing large amounts of Excel data, it is best to avoid frequently opening and closing files as much as possible.
```
% Open Excel file
fid = fopen('data.xlsx');
% Read Excel data
data = textscan(fid, '%s %f %f %f', 'Delimiter', ',');
% Close Excel file
fclose(fid);
```
### 2.3 Data Preprocessing Optimization
**2.3.1 Filter Out Unnecessary Data**
When reading Excel data, unnecessary data can be filtered out to reduce processing time.
```
% Filter out the first 10 rows of Excel data
data = readtable('data.xlsx', 'ReadVariableNames', false, 'HeaderLines', 10);
% Filter out the last 5 columns of Excel data
data = readtable('data.xlsx', 'ReadVariableNames', false, 'ReadRange', 'A1:E');
```
**2.3.2 Preprocess the Data**
After reading Excel data, preprocessing the data, such as removing duplicates and converting data formats, can improve efficiency in subsequent processing.
```
% Remove duplicates from Excel data
data = unique(data);
% Convert date format in Excel data
data.date = datetime(data.date, 'InputFormat', 'dd/mm/yyyy');
```
# 3. Data Processing Optimization Techniques
Data processing is a common task in MATLAB, and optimizing the data processing process can significantly improve performance. This chapter will introduce several techniques for optimizing data processing, including vectorized operations, avoiding loops, using sparse matrices, and utilizing structures and tables.
### 3.1 Data Operation Optimization
#### 3.1.1 Use Vectorized Operations
Vectorized operations are a powerful technique in MATLAB that allows element-wise operations on arrays or matrices. Vectorized operations are more efficient than using loops because they utilize MATLAB's built-in functions to perform operations, thus avoiding the overhead of loops.
For example, the following code uses a loop to calculate the square of each element in an array:
```
A = [1, 2, 3, 4, 5];
B = zeros(size(A));
for i = 1:length(A)
B(i) = A(i)^2;
end
```
The following code uses a vectorized operation to perform the same operation:
```
A = [1, 2, 3, 4, 5];
B = A.^2;
```
Vectorized operations are much faster than loops because they utilize MATLAB's built-in function `.^` to calculate the square element-wise.
#### 3.1.2 Avoid Using Loops
Loops are necessary in MATLAB but should be avoided as much as possible because they decrease performance. The overhead of loops includes:
* Checking the loop condition for each iteration
* Allocating memory for each iteration
* Storing loop variables
Whenever possible, vectorized operations or other built-in functions should be used to replace loops. For example, the following code uses a loop to find the maximum value in an array:
```
A = [1, 2, 3, 4, 5];
max_value = -Inf;
for i = 1:length(A)
if A(i) > max_value
max_value = A(i);
end
end
```
The following code uses the built-in function `max` to perform the same operation:
```
A = [1, 2, 3, 4, 5];
max_value = max(A);
```
The built-in function `max` is much faster than a loop because it utilizes MATLAB's optimized algorithms to find the maximum value.
### 3.2 Data Storage Optimization
#### 3.2.1 Use Sparse Matrices
Sparse matrices are matrices that contain a small number of non-zero elements. MATLAB allows creating sparse matrices using the `sparse` function. Sparse matrices are very useful when storing and processing large datasets because they only store non-zero elements, thus saving memory and computation time.
For example, the following code creates a sparse matrix with only the diagonal elements being non-zero:
```
n = 1000;
A = sparse(1:n, 1:n, ones(1, n));
```
#### 3.2.2 Use Structures and Tables
Structures and tables are two data structures in MATLAB used to organize and store data. A structure is a composite data type consisting of fields with names. A table is a two-dimensional data structure consisting of rows and columns.
Structures and tables are very useful when storing and processing complex data because they allow organizing the data into meaningful groups. For example, the following code creates a structure to store information about students' names, ages, and grades:
```
students = struct('name', {'John', 'Mary', 'Bob'}, ...
'age', {20, 21, 22}, ...
'grades', {{85, 90, 95}, {90, 95, 100}, {75, 80, 85}});
```
The following code creates a table to store the same information:
```
students = table('RowNames', {'John', 'Mary', 'Bob'}, ...
'VariableNames', {'age', 'grades'}, ...
'Data', {20, {85, 90, 95}; 21, {90, 95, 100}; 22, {75, 80, 85}});
```
Both structures and tables provide efficient methods for accessing and manipulating data.
# 4. Parallelization Optimization Techniques
Parallelization is a technique that increases computing speed by simultaneously using multiple processing units. In MATLAB, parallelization can be achieved through the Parallel Computing Toolbox or distributed computing.
### 4.1 Parallel Reading of Data
#### 4.1.1 Use the Parallel Computing Toolbox
The Parallel Computing Toolbox provides functions for parallel data reading, such as `parfor` and `spmd`. `parfor` is used for parallel execution of loops, while `spmd` is used for parallel execution of multiple independent tasks.
```
% Use parfor to parallel read data
data = cell(1, num_files);
parfor i = 1:num_files
data{i} = xlsread(filenames{i});
end
```
#### 4.1.2 Partition Data for Parallel Reading
Another method for parallel reading of data is to divide the data into multiple parts and use multiple threads or processes to read these parts simultaneously.
```
% Partition data for parallel reading
num_parts = 4;
data_parts = cell(1, num_parts);
for i = 1:num_parts
start_idx = (i-1) * floor(num_rows / num_parts) + 1;
end_idx = min(i * floor(num_rows / num_parts), num_rows);
data_parts{i} = xlsread(filename, start_idx:end_idx);
end
```
### 4.2 Parallel Processing of Data
#### 4.2.1 Use a Parallel Pool
A parallel pool is a mechanism for managing parallel computing workers. It allows users to create and manage a set of workers that can execute tasks in different threads or processes.
```
% Create a parallel pool
pool = parpool;
% Process data in parallel within the parallel pool
parfor i = 1:num_tasks
% Execute task
results{i} = process_data(data{i});
end
% Close the parallel pool
delete(pool);
```
#### 4.2.2 Use Distributed Computing
Distributed computing is a technique for parallel execution of tasks across multiple computers or nodes. MATLAB supports distributed computing using distributed computing servers such as Slurm or PBS.
```
% Process data in parallel on a distributed computing server
job = createJob('MyJob');
createTask(job, @process_data, 0, {data{1}});
createTask(job, @process_data, 0, {data{2}});
submit(job);
waitForState(job, 'finished');
results = getAllOutputArguments(job);
```
# 5. Tools and Library Optimization Techniques
### 5.1 Use Third-Party Libraries
Third-party libraries provide a wide range of functionalities and optimizations that can simplify and accelerate Excel data processing tasks in MATLAB. Here are some commonly used third-party libraries:
#### 5.1.1 pandas Library
pandas is a Python library for data manipulation and analysis that offers a rich set of features, including:
- Flexible data structures such as dataframes and series
- Efficient data manipulation functions like filtering, grouping, and aggregation
- Data visualization and plotting tools
**Code Block: Using pandas to Read Excel Data**
```
import pandas as pd
# Read Excel file
df = pd.read_excel('data.xlsx')
# Print dataframe
print(df)
```
**Logical Analysis:**
This code block uses the `read_excel` function of the pandas library to read an Excel file. The function returns a dataframe containing the data from the Excel file.
**Argument Explanation:**
- `'data.xlsx'`: Path to the Excel file to be read
- `df`: Returns a pandas dataframe containing the Excel file data
#### 5.1.2 openpyxl Library
openpyxl is a Python library for reading and writing Excel files that provides low-level access to the structure and content of Excel files. The main features of openpyxl include:
- Reading and writing Excel files
- Accessing worksheets, cells, and styles
- Creating and modifying charts
**Code Block: Using openpyxl to Write Excel Data**
```
import openpyxl
# Create a workbook
wb = openpyxl.Workbook()
# Get the active worksheet
sheet = wb.active
# Write data
sheet['A1'] = 'Name'
sheet['A2'] = 'Zhang San'
# Save the workbook
wb.save('data.xlsx')
```
**Logical Analysis:**
This code block uses the openpyxl library to create an Excel workbook and write data into it. The library provides low-level access to the Excel file structure, allowing users to directly manipulate worksheets, cells, and styles.
**Argument Explanation:**
- `openpyxl.Workbook()`: Create a new Excel workbook
- `wb.active`: Get the active worksheet
- `sheet['A1'] = 'Name'`: Write the text "Name" into cell A1
- `sheet['A2'] = 'Zhang San'`: Write the text "Zhang San" into cell A2
- `wb.save('data.xlsx')`: Save the workbook to the file "data.xlsx"
### 5.2 Use MATLAB Built-In Tools
MATLAB also offers a series of built-in tools for reading, writing, and processing Excel data, which provide efficient and user-friendly functionalities.
#### 5.2.1 readtable Function
The `readtable` function is used to read data from Excel files, offering various options to control the data reading behavior.
**Code Block: Using the readtable Function to Read Excel Data**
```
% Read Excel file
data = readtable('data.xlsx');
% Print data
disp(data);
```
**Logical Analysis:**
This code block uses the `readtable` function to read data from the Excel file "data.xlsx". The function returns a table containing the data from the Excel file.
**Argument Explanation:**
- `'data.xlsx'`: Path to the Excel file to be read
- `data`: Returns a MATLAB table containing the Excel file data
#### 5.2.2 xlsread Function
The `xlsread` function is used to read data from Excel files, supporting the reading of numeric, text, and date data.
**Code Block: Using the xlsread Function to Read Excel Data**
```
% Read Excel file
data = xlsread('data.xlsx');
% Print data
disp(data);
```
**Logical Analysis:**
This code block uses the `xlsread` function to read data from the Excel file "data.xlsx". The function returns a matrix containing the data from the Excel file.
**Argument Explanation:**
- `'data.xlsx'`: Path to the Excel file to be read
- `data`: Returns a MATLAB matrix containing the Excel file data
# 6. Performance Evaluation and Tuning
### 6.1 Performance Benchmarking
#### 6.1.1 Using tic and toc Functions
The tic and toc functions are used to measure the execution time of code. The tic function starts the timer, and the toc function stops the timer and returns the elapsed time (in seconds).
```matlab
% Start timer
tic
% Execute code
% Stop timer and get elapsed time
elapsedTime = toc;
disp(['Elapsed time: ' num2str(elapsedTime) ' seconds']);
```
#### 6.1.2 Using the profile Function
The profile function is used to analyze the performance of code and generate reports to identify performance bottlenecks.
```matlab
% Start analyzer
profile on
% Execute code
% Stop analyzer and generate report
profile off
% View report
profile viewer
```
### 6.2 Performance Tuning
#### 6.2.1 Analyze Performance Bottlenecks
Use performance benchmarking tools to identify the parts of the code with the longest execution time. These parts are often the sources of performance bottlenecks.
#### 6.2.2 Implement Optimization Strategies
Based on the performance bottlenecks, the following optimization strategies can be implemented:
- **Vectorized Operations:** Use vectorized operations instead of loops to improve code efficiency.
- **Avoid Using Loops:** Loops reduce code efficiency; wherever possible, use vectorized operations or other more effective alternatives.
- **Use Parallelization:** For large datasets, parallelization can significantly improve performance.
- **Use Third-Party Libraries:** Utilize high-performance libraries specifically designed for data processing and optimization, such as pandas and openpyxl.
- **Adjust Algorithms:** Choose more efficient algorithms for specific tasks.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VisionPro故障诊断手册:网络问题的系统诊断与调试

# 摘要
网络问题诊断与调试是确保网络高效、稳定运行的关键环节。本文从网络基础理论与故障模型出发,详细阐述了网络通信协议、网络故障的类型及原因,并介绍网络故障诊断的理论框架和管理工具。随后,本文深入探讨了网络故障诊断的实践技巧,包括诊断工具与命令、故障定位方法以及
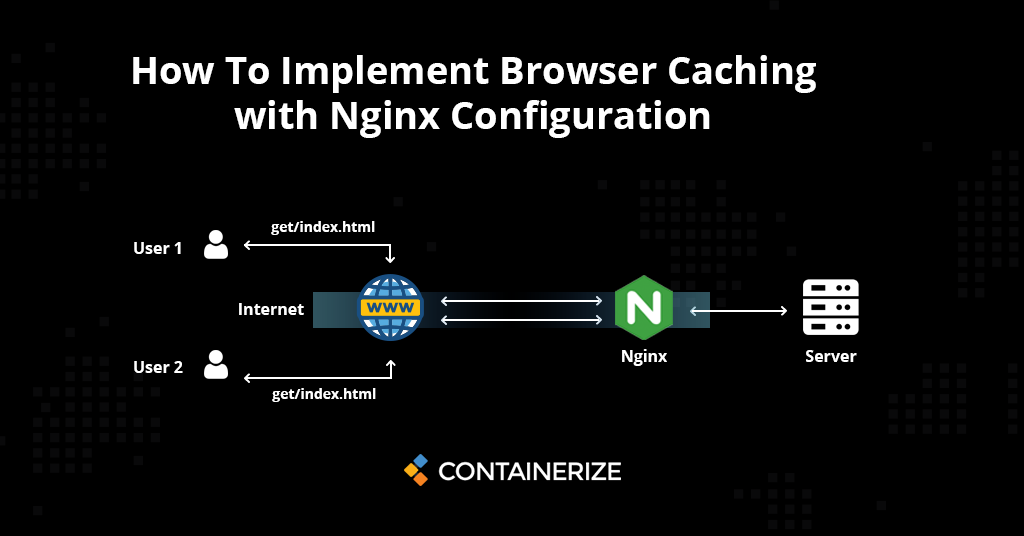
【Nginx负载均衡终极指南】:打造属于你的高效访问入口
.webp)
# 摘要
Nginx作为一款高性能的HTTP和反向代理服务器,已成为实现负载均衡的首选工具之一。本文首先介绍了Nginx负载均衡的概念及其理论基础,阐述了负载均衡的定义、作用以及常见算法,进而探讨了Nginx的架构和关键组件。文章深入到配置实践,解析了Nginx配置文件的关键指令,并通过具体配置案例展示了如何在不同场景下设置Nginx以实现高效的负载分配。
云计算助力餐饮业:系统部署与管理的最佳实践
# 摘要
云计算作为一种先进的信息技术,在餐饮业中的应用正日益普及。本文详细探讨了云计算与餐饮业务的结合方式,包括不同类型和部署模型的云服务,并分析了其在成本效益、扩展性、资源分配和高可用性等方面的优势。文中还提供餐饮业务系统云部署的实践案例,包括云服务选择、迁移策略以及安全合规性方面的考量。进一步地,文章深入讨论了餐饮业务云管理与优化的方法,并通过案例研究展示了云计算在餐饮业中的成功应用。最后,本文对云计算在餐饮业中
【Nginx安全与性能】:根目录迁移,如何在保障安全的同时优化性能
# 摘要
本文对Nginx根目录迁移过程、安全性加固策略、性能优化技巧及实践指南进行了全面的探讨。首先概述了根目录迁移的必要性与准备步骤,随后深入分析了如何加固Nginx的安全性,包括访问控制、证书加密、
RJ-CMS主题模板定制:个性化内容展示的终极指南

# 摘要
本文详细介绍了RJ-CMS主题模板定制的各个方面,涵盖基础架构、语言教程、最佳实践、理论与实践、高级技巧以及未来发展趋势。通过解析RJ-CMS模板的文件结构和继承机制,介绍基本语法和标签使用,本文旨在提供一套系统的方法论,以指导用户进行高效和安全的主题定制。同时,本文也探讨了如何优化定制化模板的性能,并分析了模板定制过程中的高级技术应用和安全性问题。最后,本文展望了RJ-CMS模板定制的
【板坯连铸热传导进阶】:专家教你如何精确预测和控制温度场

# 摘要
本文系统地探讨了板坯连铸过程中热传导的基础理论及其优化方法。首先,介绍了热传导的基本理论和建立热传导模型的方法,包括导热微分方程及其边界和初始条件的设定。接着,详细阐述了热传导模型的数值解法,并分析了影响模型准确性的多种因素,如材料热物性、几何尺寸和环境条件。本文还讨论了温度场预测的计算方法,包括有限差分法、有限元法和边界元法,并对温度场控制技术进行了深入分析。最后,文章探讨了温度场优化策略、
【性能优化大揭秘】:3个方法显著提升Android自定义View公交轨迹图响应速度

# 摘要
本文旨在探讨Android自定义View在实现公交轨迹图时的性能优化。首先介绍了自定义View的基础知识及其在公交轨迹图中应用的基本要求。随后,文章深入分析了性能瓶颈,包括常见性能问题如界面卡顿、内存泄漏,以及绘制过程中的性能考量。接着,提出了提升响应速度的三大方法论,包括减少视图层次、视图更新优化以及异步处理和多线程技术应用。第四章通过实践应用展示了性能优化的实战过程和
Python环境管理:一次性解决Scripts文件夹不出现的根本原因

# 摘要
本文系统地探讨了Python环境的管理,从Python安装与配置的基础知识,到Scripts文件夹生成和管理的机制,再到解决环境问题的实践案例。文章首先介绍了Python环境管理的基本概念,详细阐述了安装Python解释器、配置环境变量以及使用虚拟环境的重要性。随
通讯录备份系统高可用性设计:MySQL集群与负载均衡实战技巧

# 摘要
本文探讨了通讯录备份系统的高可用性架构设计及其实际应用。首先对MySQL集群基础进行了详细的分析,包括集群的原理、搭建与配置以及数据同步与管理。随后,文章深入探讨了负载均衡技术的原理与实践,及其与MySQL集群的整合方法。在此基础上,详细阐述了通讯录备份系统的高可用性架构设计,包括架构的需求与目标、双活或多活数据库架构的构建,以及监
【20分钟精通MPU-9250】:九轴传感器全攻略,从入门到精通(必备手册)

# 摘要
本文对MPU-9250传感器进行了全面的概述,涵盖了其市场定位、理论基础、硬件连接、实践应用、高级应用技巧以及故障排除与调试等方面。首先,介绍了MPU-9250作为一种九轴传感器的工作原理及其在数据融合中的应用。随后,详细阐述了传感器的硬件连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )