Python自动化测试:使用Pytest和Selenium实现自动化测试,让你的代码无懈可击
发布时间: 2024-06-19 17:41:53 阅读量: 82 订阅数: 30 

# 1. Python自动化测试概述**
Python自动化测试是一种利用Python语言和工具来模拟用户操作,自动执行软件测试任务的技术。它可以提高测试效率、准确性和覆盖率,从而帮助开发团队快速、可靠地交付高质量的软件产品。
自动化测试框架,如Pytest和Selenium,提供了丰富的功能和特性,简化了测试脚本的编写、执行和维护。这些框架支持各种断言、夹具和参数化选项,使测试用例更加灵活和可重用。
# 2. Pytest自动化测试框架
### 2.1 Pytest的基本原理和安装
Pytest是一个基于Python的自动化测试框架,以其简洁、灵活和可扩展性而闻名。它遵循测试驱动的开发(TDD)原则,鼓励在编写生产代码之前编写测试用例。
**安装Pytest**
要安装Pytest,请使用以下命令:
```
pip install pytest
```
**基本原理**
Pytest使用以下基本原理:
- **断言:**用于验证测试结果是否符合预期。
- **夹具:**用于在测试用例之间共享代码和资源。
- **参数化:**允许使用不同的数据值运行同一测试用例。
### 2.2 断言、夹具和参数化
**断言**
Pytest提供了丰富的断言库,用于验证测试结果。以下是一些常见的断言:
```python
assert x == y # 检查x是否等于y
assert x is not None # 检查x是否不为None
assert "foo" in s # 检查字符串s中是否包含"foo"
```
**夹具**
夹具允许在测试用例之间共享代码和资源。它们使用`@pytest.fixture`装饰器定义。
```python
@pytest.fixture
def setup():
# 在每个测试用例运行前执行的代码
yield # 运行测试用例
# 在每个测试用例运行后执行的代码
```
**参数化**
参数化允许使用不同的数据值运行同一测试用例。它使用`@pytest.mark.parametrize`装饰器定义。
```python
@pytest.mark.parametrize("x", [1, 2, 3])
def test_add(x):
# 使用不同的x值运行测试用例
```
### 2.3 测试报告和调试
**测试报告**
Pytest生成详细的测试报告,其中包括:
- 测试用例的执行状态
- 断言失败的详细信息
- 测试持续时间
**调试**
Pytest提供了以下调试工具:
- **pdb:**允许在测试用例失败时进入交互式调试器。
- **pytest-xdist:**用于并行执行测试用例。
- **pytest-cov:**用于生成代码覆盖率报告。
# 3. Selenium自动化测试工具
### 3.1 Selenium WebDriver简介和安装
**Selenium WebDriver** 是一个用于自动化Web应用程序测试的开源框架。它允许测试人员使用编程语言(如Python)与浏览器交互,就像真实用户一样。Selenium WebDriver支持多种浏览器,包括Chrome、Firefox、Safari和Edge。
**安装Selenium WebDriver**
在Python中安装Selenium WebDriver,可以使用pip命令:
```python
pip install selenium
```
### 3.2 定位元素、操作元素和验证结果
**定位元素**
Selenium WebDriver提供了多种定位元素的方法,包括:
- **id:**通过元素的id属性定位
- **name:**通过元素的name属性定位
- **xpath:**通过元素的XPath表达式定位
- **css selector:**通过元素的CSS选择器定位
**操作元素**
定位元素后,可以使用Selenium WebDriver的方法对其进行操作,例如:
- **click:**点击元素
- **send_keys:**向元素输入文本
- **submit:**提交表单
- **get_attribute:**获取元素的属性值
**验证结果**
为了验证测试结果,Selenium WebDriver提供了断言方法,例如:
- **assert_equal:**断言两个值相等
- **assert_true:**断言值为True
- **assert_false:**断言值为False
### 3.3 浏览器驱动和远程执行
**浏览器驱动**
Selenium WebDriver使用浏览器驱动与浏览器进行交互。浏览器驱动是特定于浏览器的可执行文件,允许WebDriver控制浏览器。例如,ChromeDriver用于控制Chrome浏览器。
**远程执行**
Selenium WebDriver还可以用于远程执行测试。这意味着测试可以在一台计算机上编写,但在另一台计算机上的浏览器中执行。这对于在不同的操作系统和浏览器组合上运行测试非常有用。
**代码示例:**
```python
from selenium import webdriver
# 创建一个Chrome浏览器驱动
driver = webdriver.Chrome()
# 访问Google主页
driver.get("https://www.google.com")
# 定位搜索框并输入查询
search_box = driver.find_element_by_name("q")
search_box.send_keys("Selenium WebDriver")
# 提交搜索表单
search_box.submit()
# 验证搜索结果页面的标题
assert "Selenium WebDriver" in driver.title
# 关闭浏览器
driver.close()
```
**逻辑分析:**
这段代码使用Selenium WebDriver创建了一个Chrome浏览器驱动,并使用该驱动访问Google主页。然后,它定位搜索框并输入查询,提交搜索表单,最后验证搜索结果页面的标题。
**参数说明:**
- `webdriver.Chrome():`创建Chrome浏览器驱动
- `driver.get("https://www.google.com"):`访问Google主页
- `driver.find_element_by_name("q"):`通过name属性定位搜索框
- `search_box.send_keys("Selenium WebDriver"):`向搜索框输入查询
- `search_box.submit():`提交搜索表单
- `assert "Selenium WebDriver" in driver.title:`验证搜索结果页面的标题
- `driver.close():`关闭浏览器
# 4. Python自动化测试实践**
**4.1 Web应用程序自动化测试**
**4.1.1 登录、注册和导航测试**
**登录测试**
```python
import pytest
from selenium import webdriver
@pytest.fixture
def setup(browser):
driver = webdriver.Chrome() if browser == "chrome" else webdriver.Firefox()
driver.get("https://example.com")
yield driver
driver.quit()
def test_login(setup):
driver = setup
driver.find_element_by_id("username").send_keys("admin")
driver.find_element_by_id("password").send_keys("password")
driver.find_element_by_id("login_button").click()
assert "Welcome, admin" in driver.page_source
```
**逻辑分析:**
此代码块演示了使用Selenium WebDriver进行登录测试。它使用Pytest作为测试框架,并使用Chrome或Firefox浏览器。代码首先通过`setup`夹具启动浏览器并导航到目标网站。然后,它使用`find_element_by_id`定位用户名和密码输入字段,并输入凭据。最后,它单击登录按钮并验证登录是否成功,方法是检查页面源中是否存在欢迎消息。
**注册测试**
```python
def test_register(setup):
driver = setup
driver.find_element_by_id("register_link").click()
driver.find_element_by_id("username").send_keys("new_user")
driver.find_element_by_id("email").send_keys("new_user@example.com")
driver.find_element_by_id("password").send_keys("password")
driver.find_element_by_id("register_button").click()
assert "Registration successful" in driver.page_source
```
**逻辑分析:**
此代码块演示了使用Selenium WebDriver进行注册测试。它导航到注册页面,输入新用户详细信息,然后单击注册按钮。最后,它验证注册是否成功,方法是检查页面源中是否存在成功消息。
**导航测试**
```python
def test_navigation(setup):
driver = setup
driver.find_element_by_id("home_link").click()
assert "Home" in driver.page_source
driver.find_element_by_id("about_link").click()
assert "About" in driver.page_source
```
**逻辑分析:**
此代码块演示了使用Selenium WebDriver进行导航测试。它通过单击链接导航到主页和关于页面,并验证每个页面是否已正确加载,方法是检查页面源中是否存在预期文本。
**4.1.2 表单提交和数据验证测试**
**表单提交测试**
```python
def test_form_submission(setup):
driver = setup
driver.find_element_by_id("contact_form").submit()
assert "Thank you for your message" in driver.page_source
```
**逻辑分析:**
此代码块演示了使用Selenium WebDriver进行表单提交测试。它提交一个联系表格,并验证是否显示了成功消息。
**数据验证测试**
```python
def test_data_validation(setup):
driver = setup
driver.find_element_by_id("username").send_keys("invalid_username")
driver.find_element_by_id("login_button").click()
assert "Invalid username" in driver.page_source
```
**逻辑分析:**
此代码块演示了使用Selenium WebDriver进行数据验证测试。它输入无效的用户名,并验证是否显示了错误消息。
# 5.1 数据驱动测试和BDD
### 5.1.1 数据驱动测试原理和实现
数据驱动测试是一种自动化测试技术,它使用外部数据源(如 CSV 文件或 Excel 表格)来提供测试用例所需的数据。这种方法的好处在于它可以减少测试用例维护的工作量,并提高测试覆盖率。
**实现数据驱动测试的步骤:**
1. **创建数据源:**创建一个包含测试用例数据的外部文件,例如 CSV 文件或 Excel 表格。
2. **编写测试脚本:**使用 Python 的 `csv` 或 `openpyxl` 库读取数据源中的数据。
3. **参数化测试用例:**使用 `pytest.mark.parametrize` 装饰器将数据源中的数据作为参数传递给测试用例。
4. **运行测试:**运行测试脚本,pytest 将自动执行每个测试用例,并使用数据源中的数据进行参数化。
**示例代码:**
```python
import csv
import pytest
@pytest.mark.parametrize("username, password", csv.reader(open("login_data.csv")))
def test_login(username, password):
# 登录操作
# 断言登录结果
```
### 5.1.2 BDD测试框架和实践
行为驱动开发(BDD)是一种软件开发方法,它通过使用自然语言来描述测试用例,从而提高测试的可读性和可维护性。BDD 测试框架(如 Cucumber 和 Behave)提供了工具和语法,使开发人员能够编写基于 Gherkin 语法的测试用例。
**Gherkin 语法:**
* **特性(Feature):**描述测试用例的整体目的。
* **场景(Scenario):**描述一个特定测试用例。
* **给定(Given):**描述测试用例的初始状态。
* **当(When):**描述对系统执行的操作。
* **那么(Then):**描述预期结果。
**示例 Gherkin 测试用例:**
```gherkin
特性: 用户登录
场景: 用户使用正确的用户名和密码登录
给定 用户已在登录页面
当 用户输入正确的用户名和密码并点击登录按钮
那么 用户应该成功登录
```
**BDD 测试框架的使用:**
1. **安装 BDD 测试框架:**使用 pip 安装 Cucumber 或 Behave 等 BDD 测试框架。
2. **编写 Gherkin 测试用例:**使用 Gherkin 语法编写测试用例。
3. **编写步骤定义:**编写 Python 代码来实现 Gherkin 测试用例中的步骤。
4. **运行测试:**运行 BDD 测试框架,它将自动执行 Gherkin 测试用例并验证预期结果。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了一系列循序渐进的指南,涵盖 Python 编程的各个方面,从基础语法和数据结构到高级主题,如机器学习、数据可视化和云计算。通过简洁的代码示例和深入的解释,本专栏旨在帮助初学者快速掌握 Python 的核心概念,并为经验丰富的程序员提供提高代码质量和效率的技巧。本专栏涵盖了广泛的主题,包括:
* Python 基础:关键语法、数据结构和内建函数
* 数据处理:使用 Pandas 库高效处理数据
* Web 开发:使用 Django 构建动态网站
* 机器学习:构建预测模型和优化模型性能
* 代码优化:加速代码执行和提高性能
* 并发编程:利用多线程和多进程提高代码效率
* 网络编程:构建高效稳定的网络应用
* 数据可视化:使用 Matplotlib 和 Seaborn 创建精美图表
* 自动化测试:使用 Pytest 和 Selenium 实现自动化测试
* 算法和数据结构:理解复杂算法和数据结构
* 面向对象编程:设计可扩展和可维护的代码
* 数据库操作:使用 SQLAlchemy 连接和管理数据库
* 云计算:使用 AWS 和 Azure 构建云端应用
* 大数据处理:使用 Spark 和 Hadoop 处理海量数据
* 自然语言处理:处理文本数据和理解人类语言
* 图像处理:处理图像和让机器看清世界
* 人工智能实战:构建智能聊天机器人和图像识别系统
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Vue Select选择框数据监听秘籍:掌握数据流与$emit通信机制

# 摘要
本文深入探讨了Vue框架中Select组件的数据绑定和通信机制。从Vue Select组件与数据绑定的基础开始,文章逐步深入到Vue的数据响应机制,详细解析了响应式数据的初始化、依赖追踪,以及父子组件间的数据传递。第三章着重于Vue Select选择框的动态数据绑定,涵盖了高级用法、计算属性的优化,以及数据变化监听策略。第四章则专注于实现Vue Se
【操作秘籍】:施耐德APC GALAXY5000 UPS开关机与故障处理手册
# 摘要
本文对施耐德APC GALAXY5000 UPS进行全面介绍,涵盖了设备的概述、基本操作、故障诊断与处理、深入应用与高级管理,以及案例分析与用户经验分享。文章详细说明了UPS的开机、关机、常规检查、维护步骤及监控报警处理流程,同时提供了故障诊断基础、常见故障排除技巧和预防措施。此外,探讨了高级开关机功能、与其他系统的集成以及高级故障处理技术。最后,通过实际案例和用户经验交流,强调了该UPS在不同应用环境中的实用性和性能优化。
# 关键字
UPS;施耐德APC;基本操作;故障诊断;系统集成;案例分析
参考资源链接:[施耐德APC GALAXY5000 / 5500 UPS开关机步骤
wget自动化管理:编写脚本实现Linux软件包的批量下载与安装
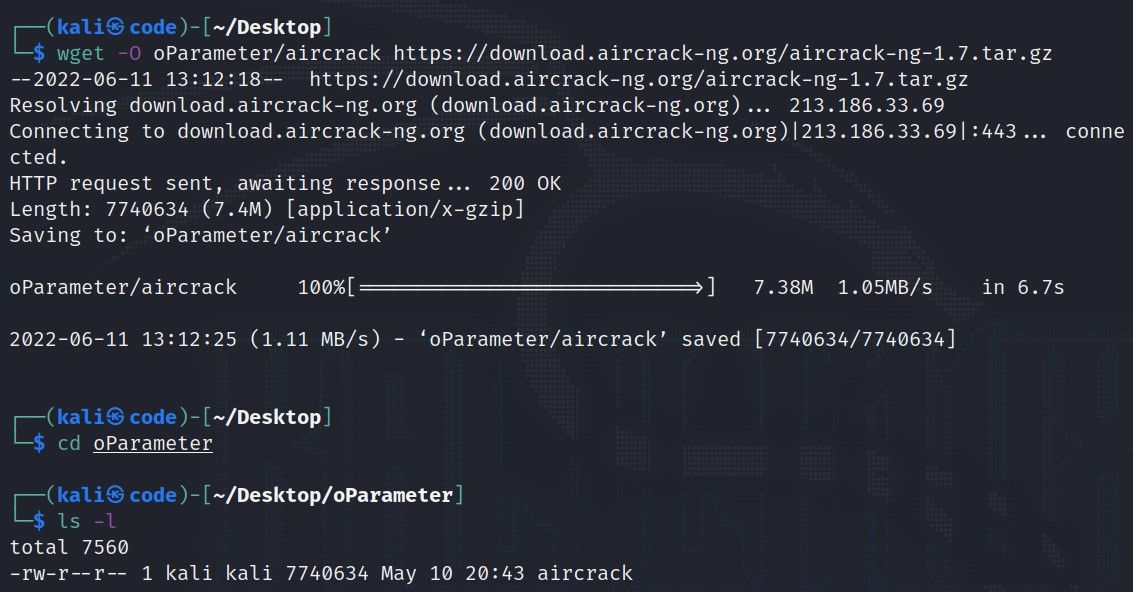
# 摘要
本文对wget工具的自动化管理进行了系统性论述,涵盖了wget的基本使用、工作原理、高级功能以及自动化脚本的编写、安装、优化和安全策略。首先介绍了wget的命令结构、选项参数和工作原理,包括支持的协议及重试机制。接着深入探讨了如何编写高效的自动化下载脚本,包括脚本结构设计、软件包信息解析、批量下载管理和错误
Java中数据结构的应用实例:深度解析与性能优化
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
SPiiPlus ACSPL+变量管理实战:提升效率的最佳实践案例分析

# 摘要
SPiiPlus ACSPL+是一种先进的控制系统编程语言,广泛应用于自动化和运动控制领域。本文首先概述了SPiiPlus ACSPL+的基本概念与变量管理基础,随后深入分析了变量类型与数据结构,并探讨了实现高效变量管理的策略。文章还通过实战技巧,讲解了变量监控、调试、性能优化和案例分析,同时涉及了高级应用,如动态内存管理、多线程变量同步以及面向对象的变
DVE基础入门:中文版用户手册的全面概览与实战技巧

# 摘要
本文旨在为初学者提供DVE(文档可视化编辑器)的入门指导和深入了解其高级功能。首先,概述了DVE的基础知识,包括用户界面布局和基本编辑操作,如文档的创建、保存、文本处理和格式排版。接着,本文探讨了DVE的高级功能,如图像处理、高级文本编辑技巧和特殊功能的使用。此外,还介绍了DVE的跨平台使用和协作功能,包括多用户协作编辑、跨平台兼容性以及与其他工具的整合。最后,通过
【Origin图表专业解析】:权威指南,坐标轴与图例隐藏_显示的实战技巧

# 摘要
本文系统地介绍了Origin软件中图表的创建、定制、交互功能以及性能优化,并通过多个案例分析展示了其在不同领域中的应用。首先,文章对Origin图表的基本概念、坐标轴和图例的显示与隐藏技巧进行了详细介绍,接着探讨了图表高级定制与性能优化的方法。文章第四章结合实战案例,深入分析了O
EPLAN Fluid团队协作利器:使用EPLAN Fluid提高设计与协作效率
# 摘要
EPLAN Fluid是一款专门针对流体工程设计的软件,它能够提供全面的设计解决方案,涵盖从基础概念到复杂项目的整个设计工作流程。本文从EPLAN Fluid的概述与基础讲起,详细阐述了设计工作流程中的配置优化、绘图工具使用、实时协作以及高级应用技巧,如自定义元件管理和自动化设计。第三章探讨了项目协作机制,包括数据管理、权限控制、跨部门沟通和工作流自定义。通过案例分析,文章深入讨论
【数据迁移无压力】:SGP.22_v2.0(RSP)中文版的平滑过渡策略

# 摘要
本文深入探讨了数据迁移的基础知识及其在实施SGP.22_v2.0(RSP)迁移时的关键实践。首先,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )