Python代码简洁之道:7个内建函数和模块,助你写出优雅代码
发布时间: 2024-06-19 17:26:12 阅读量: 86 订阅数: 32 

无需编写任何代码即可创建应用程序:Deepseek-R1 和 RooCode AI 编码代理.pdf

# 1. Python代码简洁之道的基础**
Python代码简洁之道是编写高效、易读和可维护代码的艺术。它遵循一系列原则和技术,使代码更易于理解、修改和扩展。
简洁之道的一个关键方面是使用Python丰富的内置函数和模块。内置函数提供了一系列现成的功能,可以简化常见任务,如字符串处理、列表操作和字典操作。模块则提供了更高级的功能,如操作系统交互、正则表达式处理和JSON数据处理。
通过巧妙地组合和扩展这些内置函数和模块,我们可以创建简洁而强大的代码。例如,我们可以使用`map()`函数将一个列表中的每个元素传递给一个函数,或者使用`lambda`表达式创建匿名函数,从而简化代码并提高可读性。
# 2. 内建函数的简洁之道
内建函数是 Python 标准库中预定义的函数,它们提供了各种常见操作的简洁实现。通过熟练掌握内建函数,我们可以显著提升代码的可读性和可维护性。
### 2.1 内建函数的分类与应用
内建函数按其功能可分为以下几类:
#### 2.1.1 字符串处理函数
| 函数 | 用途 | 示例 |
|---|---|---|
| `str.upper()` | 将字符串转换为大写 | `'hello'.upper()` -> 'HELLO' |
| `str.lower()` | 将字符串转换为小写 | `'HELLO'.lower()` -> 'hello' |
| `str.split()` | 根据指定分隔符拆分字符串 | `'hello,world'.split(',')` -> ['hello', 'world'] |
| `str.join()` | 使用指定分隔符连接字符串列表 | `['hello', 'world'].join(',')` -> 'hello,world' |
#### 2.1.2 列表处理函数
| 函数 | 用途 | 示例 |
|---|---|---|
| `list.append()` | 在列表末尾添加元素 | `[1, 2, 3].append(4)` -> [1, 2, 3, 4] |
| `list.extend()` | 将另一个列表添加到当前列表中 | `[1, 2, 3].extend([4, 5])` -> [1, 2, 3, 4, 5] |
| `list.sort()` | 对列表进行排序 | `[3, 1, 2].sort()` -> [1, 2, 3] |
| `list.reverse()` | 反转列表 | `[1, 2, 3].reverse()` -> [3, 2, 1] |
#### 2.1.3 字典处理函数
| 函数 | 用途 | 示例 |
|---|---|---|
| `dict.get()` | 获取字典中指定键的值,如果键不存在,则返回默认值 | `{'name': 'John'}.get('age', 0)` -> 0 |
| `dict.keys()` | 返回字典中所有键的列表 | `{'name': 'John', 'age': 30}.keys()` -> ['name', 'age'] |
| `dict.values()` | 返回字典中所有值的列表 | `{'name': 'John', 'age': 30}.values()` -> ['John', 30] |
| `dict.items()` | 返回字典中键值对的元组列表 | `{'name': 'John', 'age': 30}.items()` -> [('name', 'John'), ('age', 30)] |
### 2.2 内建函数的组合与扩展
内建函数不仅可以单独使用,还可以组合使用或与其他 Python 特性结合使用,以实现更复杂的逻辑。
#### 2.2.1 函数嵌套与链式调用
函数嵌套是指将一个函数作为另一个函数的参数传递。链式调用是指连续调用多个函数,每个函数的输出作为下一个函数的输入。
```python
# 嵌套函数
def outer_func(x):
def inner_func(y):
return x + y
return inner_func
# 链式调用
result = (
[1, 2, 3]
.map(lambda x: x * 2)
.filter(lambda x: x % 2 == 0)
.reduce(lambda x, y: x + y)
)
```
#### 2.2.2 lambda 表达式的灵活应用
lambda 表达式是一种匿名函数,可以简化代码并提高可读性。它通常用于创建一次性使用的函数,例如:
```python
# 使用 lambda 表达式过滤列表
filtered_list = list(filter(lambda x: x % 2 == 0, [1, 2, 3, 4, 5]))
```
通过熟练掌握内建函数的组合与扩展,我们可以编写出更加简洁、高效且可读的代码。
# 3. 模块的简洁之道
### 3.1 常用模块的介绍与应用
Python 内置了丰富的标准库模块,为开发者提供了强大的功能和工具。本章将介绍几个常用的模块,并展示如何使用它们来简化代码。
**3.1.1 os 模块:操作系统交互**
os 模块提供了与操作系统交互的功能,包括文件和目录管理、进程控制和环境变量操作。以下代码演示如何使用 os 模块获取当前工作目录:
```python
import os
# 获取当前工作目录
cwd = os.getcwd()
# 打印当前工作目录
print(cwd)
```
**3.1.2 re 模块:正则表达式处理**
re 模块提供了正则表达式处理功能,用于匹配和操作字符串。以下代码演示如何使用 re 模块查找字符串中的所有数字:
```python
import re
# 定义要查找的正则表达式
pattern = r"\d+"
# 在字符串中查找所有匹配项
matches = re.findall(pattern, "This is a string with 123 numbers")
# 打印匹配项
print(matches)
```
**3.1.3 json 模块:JSON 数据处理**
json 模块提供了 JSON 数据处理功能,用于解析、序列化和反序列化 JSON 数据。以下代码演示如何使用 json 模块将字典序列化为 JSON 字符串:
```python
import json
# 定义一个字典
data = {"name": "John", "age": 30}
# 将字典序列化为 JSON 字符串
json_data = json.dumps(data)
# 打印 JSON 字符串
print(json_data)
```
### 3.2 模块的组合与定制
**3.2.1 模块之间的依赖与协作**
模块可以相互依赖,协同工作以完成更复杂的任务。例如,os 模块和 shutil 模块可以组合使用来执行文件和目录操作。以下代码演示如何使用 shutil 模块复制文件:
```python
import os
import shutil
# 定义源文件和目标文件
src_file = "source.txt"
dst_file = "destination.txt"
# 检查源文件是否存在
if os.path.isfile(src_file):
# 复制文件
shutil.copyfile(src_file, dst_file)
print("File copied successfully")
else:
print("Source file not found")
```
**3.2.2 创建自定义模块扩展功能**
除了使用标准库模块,还可以创建自定义模块来扩展 Python 的功能。以下代码演示如何创建一个自定义模块来计算两个数字的和:
```python
# 创建一个名为 my_module.py 的文件
def add(a, b):
"""
计算两个数字的和
Args:
a (int): 第一个数字
b (int): 第二个数字
Returns:
int: 两个数字的和
"""
return a + b
```
然后,可以在其他 Python 脚本中导入并使用自定义模块:
```python
# 导入自定义模块
import my_module
# 调用自定义模块中的函数
result = my_module.add(10, 20)
# 打印结果
print(result)
```
# 4. 代码风格与可读性的简洁之道
### 4.1 代码格式化与规范
#### 4.1.1 缩进、空格和换行符的使用
代码的可读性很大程度上取决于其格式化。适当使用缩进、空格和换行符可以使代码更易于理解和维护。
- **缩进:**使用缩进来表示代码块的层次结构。Python 中通常使用 4 个空格作为缩进。
- **空格:**在操作符、关键字和变量周围使用空格可以提高可读性。
- **换行符:**将代码分解成较小的段落,并使用换行符来分隔不同的逻辑块。
#### 4.1.2 命名约定与注释的编写
清晰的命名约定和注释对于提高代码的可读性至关重要。
- **命名约定:**遵循一致的命名约定,例如使用小写字母和下划线分隔单词。
- **注释:**使用注释来解释代码的目的、算法或任何其他可能需要澄清的信息。
### 4.2 设计模式与代码重用
#### 4.2.1 单例模式:确保对象唯一性
单例模式是一种设计模式,它确保一个类只有一个实例。这对于需要全局访问的对象很有用,例如数据库连接或日志记录器。
```python
class Singleton:
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super().__new__(cls, *args, **kwargs)
return cls._instance
```
#### 4.2.2 工厂模式:创建对象的多样性
工厂模式是一种设计模式,它允许动态创建对象。这对于需要创建不同类型对象的应用程序很有用,例如不同的数据访问对象或不同的解析器。
```python
class Factory:
def create_product(self, product_type):
if product_type == "A":
return ProductA()
elif product_type == "B":
return ProductB()
else:
raise ValueError("Invalid product type")
```
# 5. 简洁之道在实践中的应用**
**5.1 代码简洁化的实际案例**
**5.1.1 文件处理的简洁化**
文件处理是Python中的一个常见操作。传统的文件处理方式通常涉及多个步骤,包括打开文件、读取文件、处理文件内容和关闭文件。使用Python的简洁之道,我们可以大大简化这一过程。
```python
# 传统的文件处理方式
with open('data.txt', 'r') as f:
data = f.read()
# 处理 data
f.close()
# 简洁的文件处理方式
with open('data.txt') as f:
data = [line.strip() for line in f]
```
在简洁的文件处理方式中,我们使用with语句作为上下文管理器,自动处理文件的打开和关闭操作。此外,我们使用列表推导式一次性读取文件的所有行,并去除每行的尾部空格。
**5.1.2 数据分析的简洁化**
数据分析是Python中的另一个常见任务。传统的数据分析方法通常涉及多个步骤,包括数据加载、数据清洗、数据转换和数据可视化。使用Python的简洁之道,我们可以简化这些步骤,使数据分析更加高效。
```python
# 传统的数据分析方法
import pandas as pd
# 加载数据
df = pd.read_csv('data.csv')
# 清洗数据
df = df.dropna()
# 转换数据
df['new_column'] = df['old_column'] + 1
# 可视化数据
df.plot()
# 简洁的数据分析方法
import pandas as pd
# 一次性完成数据加载、清洗、转换和可视化
df = (pd.read_csv('data.csv')
.dropna()
.assign(new_column=df['old_column'] + 1)
.plot())
```
在简洁的数据分析方法中,我们使用Pandas的管道操作符(|)将数据加载、清洗、转换和可视化操作连接在一起,一次性完成所有操作。这大大简化了数据分析过程,提高了代码的可读性和可维护性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了一系列循序渐进的指南,涵盖 Python 编程的各个方面,从基础语法和数据结构到高级主题,如机器学习、数据可视化和云计算。通过简洁的代码示例和深入的解释,本专栏旨在帮助初学者快速掌握 Python 的核心概念,并为经验丰富的程序员提供提高代码质量和效率的技巧。本专栏涵盖了广泛的主题,包括:
* Python 基础:关键语法、数据结构和内建函数
* 数据处理:使用 Pandas 库高效处理数据
* Web 开发:使用 Django 构建动态网站
* 机器学习:构建预测模型和优化模型性能
* 代码优化:加速代码执行和提高性能
* 并发编程:利用多线程和多进程提高代码效率
* 网络编程:构建高效稳定的网络应用
* 数据可视化:使用 Matplotlib 和 Seaborn 创建精美图表
* 自动化测试:使用 Pytest 和 Selenium 实现自动化测试
* 算法和数据结构:理解复杂算法和数据结构
* 面向对象编程:设计可扩展和可维护的代码
* 数据库操作:使用 SQLAlchemy 连接和管理数据库
* 云计算:使用 AWS 和 Azure 构建云端应用
* 大数据处理:使用 Spark 和 Hadoop 处理海量数据
* 自然语言处理:处理文本数据和理解人类语言
* 图像处理:处理图像和让机器看清世界
* 人工智能实战:构建智能聊天机器人和图像识别系统
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Windows系统性能升级】:一步到位的WinSXS清理操作手册
# 摘要
本文针对Windows系统性能升级提供了全面的分析与指导。首先概述了WinSXS技术的定义、作用及在系统中的重要性。其次,深入探讨了WinSXS的结构、组件及其对系统性能的影响,特别是在系统更新过程中WinSXS膨胀的挑战。在此基础上,本文详细介绍了WinSXS清理前的准备、实际清理过程中的方法、步骤及
Lego性能优化策略:提升接口测试速度与稳定性
# 摘要
随着软件系统复杂性的增加,Lego性能优化变得越来越重要。本文旨在探讨性能优化的必要性和基础概念,通过接口测试流程和性能瓶颈分析,识别和解决性能问题。文中提出多种提升接口测试速度和稳定性的策略,包括代码优化、测试环境调整、并发测试策略、测试数据管理、错误处理机制以及持续集成和部署(CI/CD)的实践。此外,本文介绍了性能优化工具和框架的选择与应用,并
UL1310中文版:掌握电源设计流程,实现从概念到成品

# 摘要
本文系统地探讨了电源设计的全过程,涵盖了基础知识、理论计算方法、设计流程、实践技巧、案例分析以及测试与优化等多个方面。文章首先介绍了电源设计的重要性、步骤和关键参数,然后深入讲解了直流变换原理、元件选型以及热设计等理论基础和计算方法。随后,文章详细阐述了电源设计的每一个阶段,包括需求分析、方案选择、详细设计、仿真
Redmine升级失败怎么办?10分钟内安全回滚的完整策略
# 摘要
本文针对Redmine升级失败的问题进行了深入分析,并详细介绍了安全回滚的准备工作、流程和最佳实践。首先,我们探讨了升级失败的潜在原因,并强调了回滚前准备工作的必要性,包括检查备份状态和设定环境。接着,文章详解了回滚流程,包括策略选择、数据库操作和系统配置调整。在回滚完成后,文章指导进行系统检查和优化,并分析失败原因以便预防未来的升级问题。最后,本文提出了基于案例的学习和未来升级策
频谱分析:常见问题解决大全

# 摘要
频谱分析作为一种核心技术,对现代电子通信、信号处理等领域至关重要。本文系统地介绍了频谱分析的基础知识、理论、实践操作以及常见问题和优化策略。首先,文章阐述了频谱分析的基本概念、数学模型以及频谱分析仪的使用和校准问题。接着,重点讨论了频谱分析的关键技术,包括傅里叶变换、窗函数选择和抽样定理。文章第三章提供了一系列频谱分析实践操作指南,包括噪声和谐波信号分析、无线信号频谱分析方法及实验室实践。第四章探讨了频谱分析中的常见问题和解决
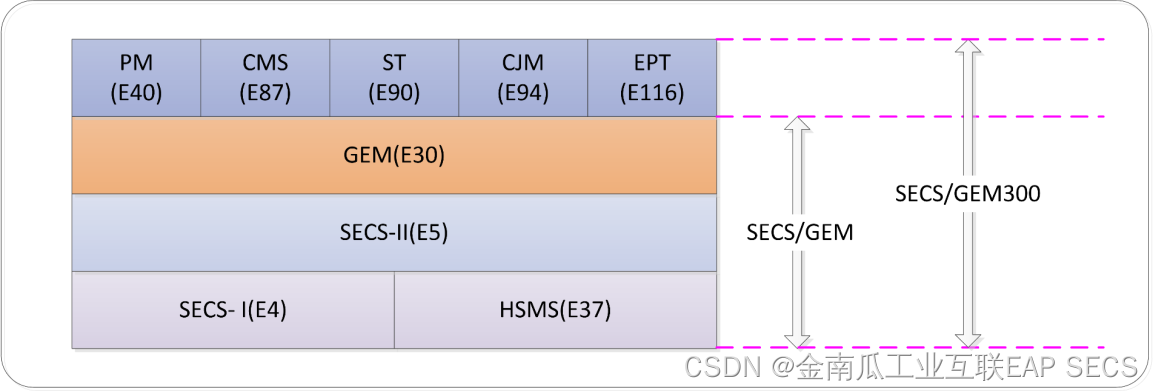
SECS-II在半导体制造中的核心角色:现代工艺的通讯支柱
# 摘要
SECS-II标准作为半导体行业中设备通信的关键协议,对提升制造过程自动化和设备间通信效率起着至关重要的作用。本文首先概述了SECS-II标准及其历史背景,随后深入探讨了其通讯协议的理论基础,包括架构、组成、消息格式以及与GEM标准的关系。文章进一步分析了SECS-II在实践应用中的案例,涵盖设备通信实现、半导体生产应用以及软件开发与部署。同时,本文还讨论了SECS-II在现代半导体制造
深入探讨最小拍控制算法

# 摘要
最小拍控制算法是一种用于实现快速响应和高精度控制的算法,它在控制理论和系统建模中起着核心作用。本文首先概述了最小拍控制算法的基本概念、特点及应用场景,并深入探讨了控制理论的基础,包括系统稳定性的分析以及不同建模方法。接着,本文对最小拍控制算法的理论推导进行了详细阐述,包括其数学描述、稳定性分析以及计算方法。在实践应用方面,本文分析了最小拍控制在离散系统中的实现、
【Java内存优化大揭秘】:Eclipse内存分析工具MAT深度解读

# 摘要
本文深入探讨了Java内存模型及其优化技术,特别是通过Eclipse内存分析工具MAT的应用。文章首先概述了Java内存模型的基础知识,随后详细介绍MAT工具的核心功能、优势、安装和配置步骤。通过实战章节,本文展示了如何使用MAT进行堆转储文件分析、内存泄漏的检测和诊断以及解决方法。深度应用技巧章节深入讲解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )