MATLAB Normal Distribution in Machine Learning: Unveiling the Role of Normal Distribution in Machine Learning
发布时间: 2024-09-14 15:34:26 阅读量: 22 订阅数: 29 

WebFace260M A Benchmark Unveiling the Power of Million-Scale.pdf
# MATLAB Normal Distribution in Machine Learning: Unveiling the Role of the Normal Distribution in Machine Learning
## 1. Theoretical Foundations of the Normal Distribution**
The normal distribution, also known as the Gaussian distribution, is a continuous probability distribution that takes the shape of a bell curve. It is extensively used in statistics and machine learning because it can describe numerous natural phenomena and datasets.
The mathematical expression of the normal distribution is:
```
f(x) = (1 / (σ√(2π))) * e^(-(x - μ)² / (2σ²))
```
Where:
* μ is the mean of the normal distribution, representing the central position of the data.
* σ is the standard deviation of the normal distribution, indicating the dispersion of the data.
## 2. Applications of the Normal Distribution in Machine Learning
### 2.1 Application of the Normal Distribution in Classification
#### 2.1.1 Naive Bayes Classifier
The naive Bayes classifier is a probabilistic classifier based on Bayes' theorem. It assumes that the features are mutually independent; in other words, the value of one feature does not affect the value of other features.
**Code Block:**
```python
import numpy as np
import pandas as pd
from sklearn.naive_bayes import GaussianNB
# Import data
data = pd.read_csv('data.csv')
# Separate features and labels
X = data.drop('label', axis=1)
y = data['label']
# Train the naive Bayes classifier
model = GaussianNB()
model.fit(X, y)
# Predict new data
new_data = pd.DataFrame({'feature1': [1, 2, 3], 'feature2': [4, 5, 6]})
predictions = model.predict(new_data)
```
**Logical Analysis:**
* `GaussianNB()`: Create a naive Bayes classifier.
* `fit(X, y)`: Train the classifier, where X is the features and y is the labels.
* `predict(new_data)`: Use the trained classifier to predict new data.
#### 2.1.2 Support Vector Machines
Support vector machines are a classification algorithm that map data points to a high-dimensional space and find a hyperplane to separate the data points into different categories.
**Code Block:**
```python
import numpy as np
import pandas as pd
from sklearn.svm import SVC
# Import data
data = pd.read_csv('data.csv')
# Separate features and labels
X = data.drop('label', axis=1)
y = data['label']
# Train the support vector machine classifier
model = SVC()
model.fit(X, y)
# Predict new data
new_data = pd.DataFrame({'feature1': [1, 2, 3], 'feature2': [4, 5, 6]})
predictions = model.predict(new_data)
```
**Logical Analysis:**
* `SVC()`: Create a support vector machine classifier.
* `fit(X, y)`: Train the classifier, where X is the features and y is the labels.
* `predict(new_data)`: Use the trained classifier to predict new data.
### 2.2 Application of the Normal Distribution in Regression
#### 2.2.1 Linear Regression
Linear regression is a regression algorithm used for predicting continuous target variables. It assumes a linear relationship between the target variable and the feature variables.
**Code Block:**
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# Import data
data = pd.read_csv('data.csv')
# Separate features and labels
X = data.drop('label', axis=1)
y = data['label']
# Train the linear regression model
model = LinearRegression()
model.fit(X, y)
# Predict new data
new_data = pd.DataFrame({'feature1': [1, 2, 3], 'feature2': [4, 5, 6]})
predictions = model.predict(new_data)
```
**Logical Analysis:**
* `LinearRegression()`: Create a linear regression model.
* `fit(X, y)`: Train the model, where X is the features and y is the labels.
* `predict(new_data)`: Use the trained model to predict new data.
#### 2.2.2 Logistic Regression
Logistic regression is a regression algorithm used for binary classification problems. It maps input data to a probability value, representing the probability of belonging to a certain class.
**Code Block:**
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
# Import data
data = pd.read_csv('data.csv')
# Separate features and labels
X = data.drop('label', axis=1)
y = data['label']
# Train the logistic regression model
model = LogisticRegression()
model.fit(X, y)
# Predict new data
new_data = pd.DataFrame({'feature1': [1, 2, 3], 'feature2': [4, 5, 6]})
predictions = model.predict(new_data)
```
**Logical Analysis:**
* `LogisticRegression()`: Create a logistic regression model.
* `fit(X, y)`: Train the model, where X is the features and y is the labels.
* `predict(new_data)`: Use the trained model to predict new data.
# 3.1 Applications of the Normal Distribution in Data Analysis
The normal distribution plays a crucial role in data analysis, providing a solid foundation for data exploration

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【社交网络数据分析】:Muma包与R语言网络分析的完美结合

# 摘要
随着社交网络的迅猛发展,数据分析已成为理解和挖掘社交网络中信息的重要手段。本文从社交网络数据分析的基本概念出发,系统地介绍
CPCL打印脚本编写艺术:掌握格式、模板与高级特性的10个秘诀

# 摘要
CPCL(Common Programming Control Language)打印脚本是专门用于打印机配置和打印任务的标记语言。本文首先概述了CPCL打印脚本的基本概念和应用场景,随后深入解析了其语法结构、标签、属性及基本命令操作。文章还探讨了CPCL脚本在逻辑流程控制方面的能力,包括条件控制和循环语句。接着,针对打印模板设计与管理,本文提出了模块化设计原则和版本控制的重要性。此外,本文详细介绍
【ES7210-TDM级联深入剖析】:掌握技术原理与工作流程,轻松设置与故障排除

# 摘要
本文旨在系统介绍TDM级联技术,并以ES7210设备为例,详细分析其在TDM级联中的应用。文章首先概述了TDM级联技术的基本概念和ES7210设备的相关信息,进而深入探讨了TDM级联的原理、配置、工作流程以及高级管理技巧。通过深入配置与管理章节,本文提供了多项高级配置技巧和安全策略,确保级联链路的稳定性和安全性。最后,文章结合实际案例,总结了故障排除和性能优化的实用
【Origin函数公式】:5个公式让数据导入变得简单高效

# 摘要
Origin是一款广泛使用的科学绘图和数据分析软件,其函数公式功能对处理实验数据和进行统计分析至关重要。本文首先介绍了Origin函数公式的概念及其在数据分析中的重要性,然后详细阐述了基础函数公式的使用方法,包括数据导入和操作基础。接着,本文深入探讨了Origin函数公式的高级技巧,如数据处理、逻辑运算和条件判断,以及如何处理复杂数据集。此外,文中还介绍了Origi
【I_O子系统秘密】:工作原理大公开,优化技巧助你飞速提升系统效率

# 摘要
I/O子系统作为计算机系统中负责数据输入输出的核心组成部分,对整体性能有显著影响。本文首先解析了I/O子系统的概念及其理论基础,详细阐述了I/O的基本功能、调度算法原理和缓存机制。接着,文章转向I/O子系统的性能优化实践,讨论了磁盘和网络I/O性能调优技巧以及I/O资源限制与QoS管理。此外,本文还提供了I/O子系统常见问题的诊断方法和优化案例分析,最后探讨了新型存储技术、软件定
【数据清洗与预处理】:同花顺公式中的关键技巧,提高数据质量
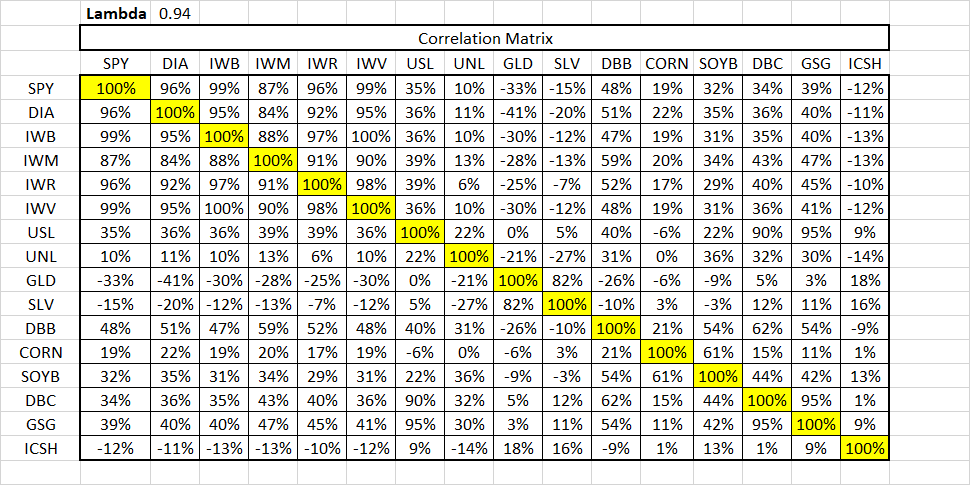
# 摘要
随着数据科学与金融分析领域的深度融合,数据清洗与预处理成为了确保数据质量和分析结果准确性的基础工作。本文全面探讨了数据清洗与预处理的重要性、同花顺公式在数据处理中的理论和实践应用,包括数据问题诊断、数据清洗与预处理技术的应用案例以及高级处理技巧。通过对数据标准化、归一化、特征工程、高级清洗与预处理技术的分析,本文展示了同花顺公式如何提高数据处理效率
AP6521固件升级自动化秘籍:提升维护效率的5大策略
# 摘要
本文概述了AP6521固件升级的自动化实践策略,旨在通过自动化提升效率并确保固件升级过程的稳定性和安全性。首先探讨了自动化与效率提升的理论基础及其在固件升级中的作用,随后详细阐述了自动化环境的准备、固件升级脚本的编写、监控与日志系统的集成,以及安全性与备份的必要措施。实践策略还包括了持续集成与部署的实施方法。最后,
薪酬与技术创新:探索要素等级点数公式在技术进步中的作用

# 摘要
本文深入探讨了薪酬与技术创新之间的理论关系,并围绕要素等级点数公式展开了全面的分析。首先,文章介绍了该公式的起源、发展以及核心要素,分析了技术与人力资本、市场与组织因素对技术创新的影响,并讨论了其在不同行业中激励技术创新的机制。接着,通过实践案例,本文探讨了要素等级点数公式在激励人才流动和职业发展中的应用,并总结了成功实践的关键因素与所面临的挑战。进一步地,实证研究部分验证了公式的有效性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )