掌握链表的核心原理,开启数据结构之旅
发布时间: 2024-05-02 03:41:07 阅读量: 77 订阅数: 52 

数据结构中链表的应用
# 1. 链表的基本概念和结构**
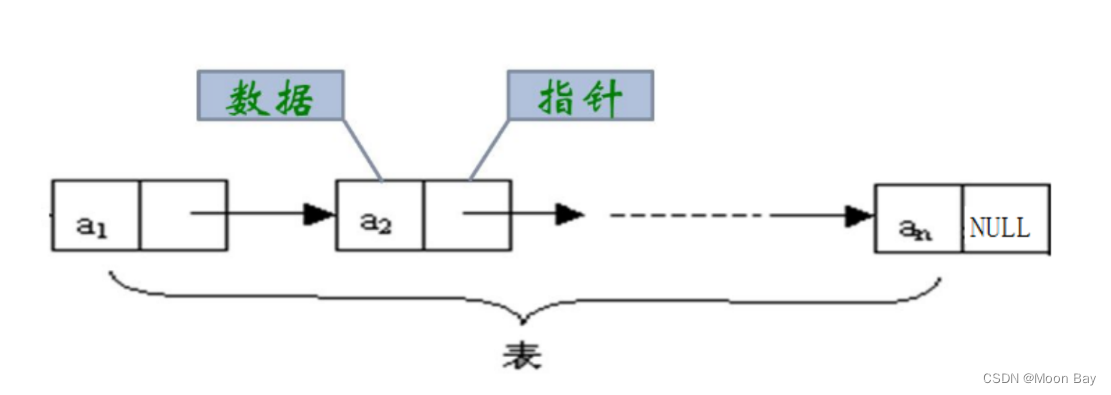
链表是一种线性数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的指针。与数组不同,链表中的节点可以在内存中分散存储,从而提供了插入和删除元素的灵活性。
链表的基本结构如下:
```mermaid
graph LR
A[Node 1] --> B[Node 2] --> C[Node 3]
```
每个节点包含一个数据字段(例如 `data`) 和一个指向下一个节点的指针(例如 `next`)。头节点指向链表的第一个节点,尾节点指向链表的最后一个节点。
# 2.1 链表的存储结构和特性
### 链表的存储结构
链表是一种线性数据结构,其元素之间通过指针连接。每个元素(称为节点)包含两个部分:数据域和指针域。数据域存储实际数据,而指针域存储指向下一个节点的指针。
```cpp
struct Node {
int data;
Node* next;
};
```
### 链表的特性
* **非连续存储:**链表中的节点存储在内存的不同位置,因此不是连续的。
* **动态分配:**链表中的节点在需要时动态分配,不需要时释放。
* **插入和删除方便:**在链表中插入或删除节点不需要移动其他节点,只需更新指针即可。
* **顺序访问困难:**由于链表中的节点不是连续存储的,因此顺序访问链表中的元素需要遍历整个链表。
### 链表与数组的比较
| 特性 | 链表 | 数组 |
|---|---|---|
| 存储结构 | 非连续 | 连续 |
| 内存分配 | 动态分配 | 静态分配 |
| 插入和删除 | 方便 | 困难 |
| 顺序访问 | 困难 | 方便 |
## 2.2 链表的节点操作
### 2.2.1 节点的插入和删除
**插入节点:**
* 在链表的开头插入节点:将新节点的指针指向链表头,然后将链表头更新为新节点。
* 在链表的中间插入节点:找到要插入节点之前的位置,然后将新节点的指针指向该位置的下一个节点,并将该位置的下一个节点更新为新节点。
* 在链表的末尾插入节点:找到链表的尾节点,然后将新节点的指针指向尾节点,并将尾节点更新为新节点。
**删除节点:**
* 删除链表的第一个节点:将链表头更新为链表头的下一个节点。
* 删除链表的中间节点:找到要删除节点的前一个节点,然后将前一个节点的指针指向要删除节点的下一个节点。
* 删除链表的最后一个节点:找到链表的尾节点的前一个节点,然后将尾节点的前一个节点的指针指向空。
### 2.2.2 节点的查找和遍历
**查找节点:**
从链表头开始,逐个比较节点的数据域,直到找到要查找的节点。
```cpp
Node* findNode(Node* head, int data) {
while (head != NULL) {
if (head->data == data) {
return head;
}
head = head->next;
}
return NULL;
}
```
**遍历链表:**
从链表头开始,逐个访问节点,直到链表尾。
```cpp
void traverseList(Node* head) {
while (head != NULL) {
printf("%d ", head->data);
head = head->next;
}
}
```
# 3. 链表的实践应用
### 3.1 单链表的实现
#### 3.1.1 单链表的节点结构
单链表的节点通常包含两个部分:数据域和指针域。数据域存储实际数据,而指针域指向下一个节点。
```python
class Node:
def __init__(self, data):
self.data = data
self.next = None
```
#### 3.1.2 单链表的基本操作
单链表的基本操作包括:
- **插入节点:**在指定位置插入一个新节点。
- **删除节点:**删除指定位置的节点。
- **查找节点:**根据数据值查找节点。
- **遍历链表:**从头到尾遍历链表中的所有节点。
### 3.2 双链表的实现
#### 3.2.1 双链表的节点结构
双链表的节点与单链表类似,但它有两个指针域:一个指向下一个节点,另一个指向前一个节点。
```python
class Node:
def __init__(self, data):
self.data = data
self.next = None
self.prev = None
```
#### 3.2.2 双链表的基本操作
双链表的基本操作与单链表类似,但它还包括一些额外的操作,例如:
- **插入节点:**在指定位置插入一个新节点。
- **删除节点:**删除指定位置的节点。
- **查找节点:**根据数据值查找节点。
- **遍历链表:**从头到尾或从尾到头遍历链表中的所有节点。
### 代码示例
以下代码示例演示了单链表和双链表的基本操作:
```python
# 单链表示例
head = Node(1)
head.next = Node(2)
head.next.next = Node(3)
# 插入节点
new_node = Node(4)
new_node.next = head.next
head.next = new_node
# 删除节点
head.next = head.next.next
# 遍历链表
current_node = head
while current_node is not None:
print(current_node.data)
current_node = current_node.next
# 双链表示例
head = No
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏简介
本专栏全面深入地探讨了链表数据结构,涵盖了从基本概念和应用场景到高级算法和优化策略的各个方面。专栏内容包括:链表的创建、遍历、插入、删除、反转、环检测、快慢指针法、LRU缓存淘汰算法、有序链表合并、倒数第K个节点查找、链表相交判断、环检测、递归思想、随机访问链表、查询效率优化、排序算法、大整数运算、约瑟夫问题、链表与树结构比较、通用链表设计、内存管理、算法优化实践、数据库系统应用、图形算法应用、操作系统内核设计应用等。通过深入浅出的讲解和丰富的示例,本专栏旨在帮助读者全面掌握链表的核心原理,并将其应用于实际问题解决中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C#网络编程揭秘】:TCP_IP与UDP通信机制全解析
# 摘要
本文全面探讨了C#网络编程的基础知识,深入解析了TCP/IP架构下的TCP和UDP协议,以及高级网络通信技术。首先介绍了C#中网络编程的基础,包括TCP协议的工作原理、编程模型和异常处理。其次,对UDP协议的应用与实践进行了讨论,包括其特点、编程模型和安全性分析。然后,详细阐述了异步与同步通信模型、线程管理,以及TLS/SSL和NAT穿透技术在C#中的应用。最后,通过实战项目展示了网络编程的综合应用,并讨论了性能优化、故障排除和安全性考量。本文旨在为网络编程人员提供详尽的指导和实用的技术支持,以应对在实际开发中可能遇到的各种挑战。
# 关键字
C#网络编程;TCP/IP架构;TCP
深入金融数学:揭秘随机过程在金融市场中的关键作用

# 摘要
随机过程理论是分析金融市场复杂动态的基础工具,它在期权定价、风险管理以及资产配置等方面发挥着重要作用。本文首先介绍了随机过程的定义、分类以及数学模型,并探讨了模拟这些过程的常用方法。接着,文章深入分析了随机过程在金融市场中的具体应用,包括Black-Scholes模型、随机波动率模型、Value at Risk (VaR)和随机控制理论在资产配置中的应
CoDeSys 2.3中文教程高级篇:自动化项目中面向对象编程的5大应用案例
# 摘要
本文全面探讨了面向对象编程(OOP)的基础理论及其在CoDeSys 2.3平台的应用实践。首先介绍面向对象编程的基本概念与理论框架,随后深入阐释了OOP的三大特征:封装、继承和多态,以及设计原则,如开闭原则和依赖倒置原则。接着,本文通过CoDeSys 2.3平台的实战应用案例,展示了面向对象编程在工业自动化项目中
【PHP性能提升】:专家解读JSON字符串中的反斜杠处理,提升数据清洗效率
# 摘要
本文深入探讨了在PHP环境中处理JSON字符串的重要性和面临的挑战,涵盖了JSON基础知识、反斜杠处理、数据清洗效率提升及进阶优化等关键领域。通过分析JSON数据结构和格式规范,本文揭示了PHP中json_encode()和json_decode()函数使用的效率和性能考量。同时,本文着重讨论了反斜杠在JSON字符串中的角色,以及如何高效处理以避免常见的数据清洗性能
成为行业认可的ISO 20653专家:全面培训课程详解

# 摘要
ISO 20653标准作为铁路行业的关键安全规范,详细规定了安全管理和风险评估流程、技术要求以及专家认证路径。本文对ISO 20653标准进行了全面概述,深入分析了标准的关键要素,包括其历史背景、框架结构、安全管理系统要求以及铁路车辆安全技术要求。同时,本文探讨了如何在企业中实施ISO 20653标准,并分析了在此过程中可能遇到的挑战和解决方案。此外,文章还强调了持续专业发展的重要性
Arm Compiler 5.06 Update 7实战指南:专家带你玩转LIN32平台性能调优

# 摘要
本文详细介绍了Arm Compiler 5.06 Update 7的特点及其在不同平台上的性能优化实践。文章首先概述了Arm架构与编译原理,并针对新版本编译器的新特性进行了深入分析。接着,介绍了如何搭建编译环境,并通过编译实践演示了基础用法。此外,文章还
【62056-21协议深度解析】:构建智能电表通信系统的秘诀
# 摘要
本文对62056-21通信协议进行了全面概述,分析了其理论基础,包括帧结构、数据封装、传输机制、错误检测与纠正技术。在智能电表通信系统的实现部分,探讨了系统硬件构成、软件协议栈设计以及系统集成与测试的重要性。此外,本文深入研究了62056-21协议在实践应用中的案例分析、系统优化策略和安全性增强措
5G NR同步技术新进展:探索5G时代同步机制的创新与挑战

# 摘要
本文全面概述了5G NR(新无线电)同步技术的关键要素及其理论基础,探讨了物理层同步信号设计原理、同步过程中的关键技术,并实践探索了同步算法与
【天龙八部动画系统】:骨骼动画与精灵动画实现指南(动画大师分享)
# 摘要
本文系统地探讨了骨骼动画与精灵动画的基本概念、技术剖析、制作技巧以及融合应用。文章从理论基础出发,详细阐述了骨骼动画的定义、原理、软件实现和优化策略,同时对精灵动画的分类、工作流程、制作技巧和高级应用进行了全面分析。此外,本文还探讨了骨骼动画与精灵动画的融合点、构建跨平台动画系统的策略,并通过案例分
【Linux二进制文件执行权限问题快速诊断与解决】:一分钟搞定执行障碍
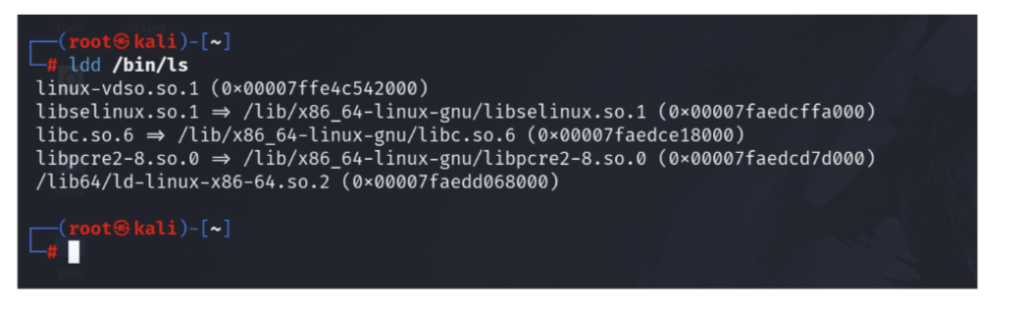
# 摘要
本文针对Linux环境下二进制文件执行权限进行了全面的分析,概述了权限的基本概念、构成和意义,并探讨了执行权限的必要性及其常见问题。通过介绍常用的权限检查工具和方法,如使用`ls`和`stat`命令,文章提供了快速诊断执行障碍的步骤和技巧,包括文件所有者和权限设置的确认以及脚本自动化检查。此外,本文还深入讨论了特殊权限位、文件系统特性、非标准权限问题以及安全审计的重要性。通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )