MATLAB时间序列预测:卡尔曼滤波器与小波变换的信号处理艺术
发布时间: 2024-08-30 17:44:04 阅读量: 58 订阅数: 54 

卡尔曼滤波器:卡尔曼滤波器的一个例子-matlab开发
# 1. 时间序列预测基础
在数据分析领域,时间序列预测是一项至关重要的技能,它涉及到根据过去和现在的数据来预测未来事件发生的可能性。本章将介绍时间序列预测的核心概念,为读者构建坚实的理论基础。
## 1.1 时间序列的基本概念
时间序列是由按时间顺序排列的观测值组成的序列。在IT和金融等众多领域中,时间序列数据是最常见的数据形式之一。时间序列分析的核心目的是理解数据的历史行为并预测未来的趋势。
## 1.2 时间序列预测的方法论
时间序列预测方法可以分为定性和定量两大类。定性方法侧重于专家的经验和判断,而定量方法则侧重于统计和数学模型,如自回归模型(AR)、移动平均模型(MA)和自回归移动平均模型(ARMA)等。
## 1.3 时间序列预测的实际应用
本章节还会探讨时间序列预测在不同场景中的应用,例如股票市场趋势分析、网络流量预测、天气变化预测等。通过案例演示,使读者能够理解时间序列预测的实际操作流程和优化策略。
# 2. 卡尔曼滤波器理论与应用
### 2.1 卡尔曼滤波器基础
#### 2.1.1 卡尔曼滤波器的数学原理
卡尔曼滤波器(Kalman Filter)是线性动态系统中最优的状态估计算法之一。它利用了系统的数学模型,并结合了实际测量数据,以最小化误差的均方值来估计系统的状态。这一过程通常涉及两个主要步骤:预测和更新。
在预测阶段,使用系统动态模型和上一时刻的估计来预测当前时刻的状态。假设系统状态的动态可以通过以下线性方程描述:
\[ x_{k} = A_k x_{k-1} + B_k u_{k} + w_{k-1} \]
其中,\(x_k\) 是当前时刻的系统状态,\(A_k\) 是系统动态矩阵,\(B_k\) 是控制输入矩阵,\(u_k\) 是控制输入,\(w_{k-1}\) 是过程噪声。
预测误差的协方差矩阵 \(P_k\) 通过以下方程更新:
\[ P_k = A_k P_{k-1} A_k^T + Q_k \]
其中,\(P_{k-1}\) 是前一时刻的协方差矩阵,\(Q_k\) 是过程噪声的协方差矩阵。
在更新阶段,将预测的状态与实际测量数据结合,通过下面的方程进行状态更新:
\[ x_k^+ = x_k + K_k (z_k - H_k x_k) \]
\[ P_k^+ = (I - K_k H_k) P_k \]
在这里,\(z_k\) 是测量值,\(H_k\) 是测量矩阵,\(K_k\) 是卡尔曼增益,\(I\) 是单位矩阵。
卡尔曼滤波器的核心在于计算卡尔曼增益 \(K_k\),它依赖于预测误差协方差矩阵 \(P_k\) 和测量误差协方差矩阵 \(R_k\):
\[ K_k = P_k H_k^T (H_k P_k H_k^T + R_k)^{-1} \]
#### 2.1.2 卡尔曼滤波器的状态空间模型
状态空间模型是卡尔曼滤波器的核心,它由两部分组成:状态方程和观测方程。状态方程描述了系统状态随时间的演变:
\[ x_{k} = A_k x_{k-1} + B_k u_{k} + w_{k} \]
观测方程则描述了如何从系统状态中获取观测数据:
\[ z_{k} = H_k x_{k} + v_{k} \]
这里,\(v_k\) 是观测噪声。状态空间模型的关键是系统的动态矩阵 \(A_k\)、控制输入矩阵 \(B_k\)、测量矩阵 \(H_k\),以及过程噪声 \(w_k\) 和观测噪声 \(v_k\) 的统计特性。
### 2.2 卡尔曼滤波器在MATLAB中的实现
#### 2.2.1 MATLAB内置卡尔曼滤波函数
MATLAB提供了一系列内置函数来实现卡尔曼滤波。其中最常用的是`kalman`函数,它用于设计卡尔曼滤波器。使用这个函数,我们可以定义状态空间模型的参数,包括动态矩阵、控制输入矩阵、测量矩阵、过程噪声和测量噪声的协方差矩阵。
```matlab
% 设定状态空间模型的参数
A = [...]; % 动态矩阵
B = [...]; % 控制输入矩阵
C = eye(size(A)); % 输出矩阵(在观测方程中)
D = [...]; % 输入矩阵(在观测方程中)
Q = [...]; % 过程噪声的协方差矩阵
R = [...]; % 观测噪声的协方差矩阵
H = [...]; % 测量矩阵
% 创建卡尔曼滤波器对象
KF = kalman(ss(A,[B D],C,[0 Q],[0 R]),x0);
% 其中 x0 是初始状态估计
```
#### 2.2.2 自定义卡尔曼滤波器的代码实现
尽管MATLAB提供了内置函数,但我们仍可能需要自定义卡尔曼滤波器。这可以通过编写函数来手动计算预测、更新和增益计算步骤来实现。以下是自定义实现的一个简化示例:
```matlab
% 初始化状态和协方差矩阵
x_est = [...]; % 状态估计向量
P_est = [...]; % 协方差矩阵
% 自定义卡尔曼滤波器更新函数
function [x_new, P_new] = kalman_filter_update(x_est, P_est, z, A, B, u, H, Q, R)
% 预测
x_pred = A * x_est + B * u;
P_pred = A * P_est * A' + Q;
% 更新
K = P_pred * H' * inv(H * P_pred * H' + R);
x_new = x_pred + K * (z - H * x_pred);
P_new = (eye(size(H, 1)) - K * H) * P_pred;
end
```
### 2.3 卡尔曼滤波器的实战应用案例
#### 2.3.1 金融时间序列数据预测
在金融领域,卡尔曼滤波器可以用来预测股票价格、汇率等金融时间序列数据。通过建立一个包含价格走势和波动率的状态空间模型,可以利用卡尔曼滤波器进行动态估计。
```matlab
% 假设股票价格数据存储在 'stock_prices' 变量中
% 构建自回归模型作为动态矩阵 A 和控制输入矩阵 B
A = [...];
B = [...];
% 观测矩阵 H 可以是一个简单的线性变换,例如 H = [1 0]
H = [...];
% 使用自定义的卡尔曼滤波函数或内置函数进行预测
[filtered_stock_price, ~] = kalma
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 MATLAB 时间序列预测算法专栏!本专栏为您提供一系列全面的指南和实战教程,帮助您掌握时间序列分析和预测的各个方面。从数据预处理到深度学习模型构建,再到异常检测和模型验证,我们将深入探讨 MATLAB 中最先进的技术。通过专家技巧、案例分析和视觉辅助,您将获得预测时间序列、识别异常并做出明智决策所需的知识和技能。本专栏涵盖了各种方法,包括 LSTM 网络、集成学习、移动平均模型、指数平滑、卡尔曼滤波器、小波变换、GARCH 模型和动态系统状态估计。无论您是初学者还是经验丰富的从业者,本专栏都将为您提供所需的见解和实用工具,以提升您的时间序列预测能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Adblock Plus高级应用:如何利用过滤器提升网页加载速度

# 摘要
本文全面介绍了Adblock Plus作为一款流行的广告拦截工具,从其基本功能到高级过滤策略,以及社区支持和未来的发展方向进行了详细探讨。首先,文章概述了Adb
【QCA Wi-Fi源代码优化指南】:性能与稳定性提升的黄金法则

# 摘要
本文对QCA Wi-Fi源代码优化进行了全面的概述,旨在提升Wi-Fi性能和稳定性。通过对QCA Wi-Fi源代码的结构、核心算法和数据结构进行深入分析,明确了性能优化的关键点。文章详细探讨了代码层面的优化策略,包括编码最佳实践、性能瓶颈的分析与优化、以及稳定性改进措施。系统层面
网络数据包解码与分析实操:WinPcap技术实战指南
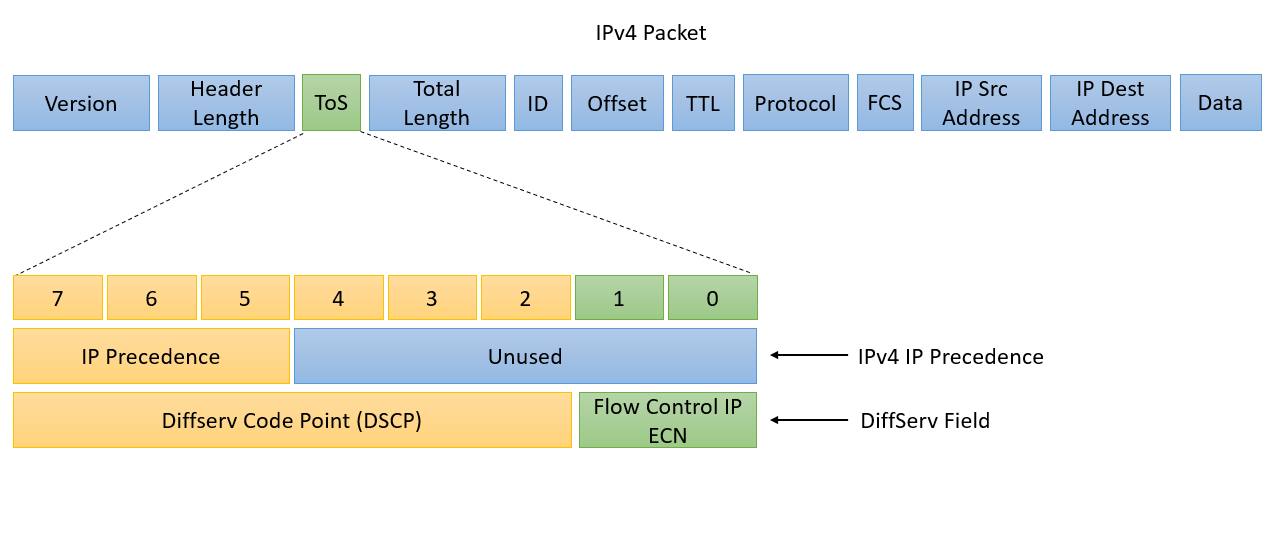
# 摘要
随着网络技术的不断进步,网络数据包的解码与分析成为网络监控、性能优化和安全保障的重要环节。本文从网络数据包解码与分析的基础知识讲起,详细介绍了WinPcap技术的核心组件和开发环境搭建方法,深入解析了数据包的结构和解码技术原理,并通过实际案例展示了数据包解码的实践过程。此外,本文探讨了网络数据分析与处理的多种技术,包括数据包过滤、流量分析,以及在网络安全中的应用,如入侵检测系统和网络
【EMMC5.0全面解析】:深度挖掘技术内幕及高效应用策略

# 摘要
EMMC5.0技术作为嵌入式存储设备的标准化接口,提供了高速、高效的数据传输性能以及高级安全和电源管理功能。本文详细介绍了EMMC5.0的技术基础,包括其物理结构、接口协议、性能特点以及电源管理策略。高级特性如安全机制、高速缓存技术和命令队列技术的分析,以及兼容性和测试方法的探讨,为读者提供了全面的EMMC5.0技术概览。最后,文章探讨了EMMC5.0在嵌入式系统中的应用以及未来的发展趋势和高效应用策略,强调了软硬
【高级故障排除技术】:深入分析DeltaV OPC复杂问题

# 摘要
本文旨在为DeltaV系统的OPC故障排除提供全面的指导和实践技巧。首先概述了故障排除的重要性,随后探讨了理论基础,包括DeltaV系统架构和OPC技术的角色、故障的分类与原因,以及故障诊断和排查的基本流程。在实践技巧章节中,详细讨论了实时数据通信、安全性和认证
手把手教学PN532模块使用:NFC技术入门指南
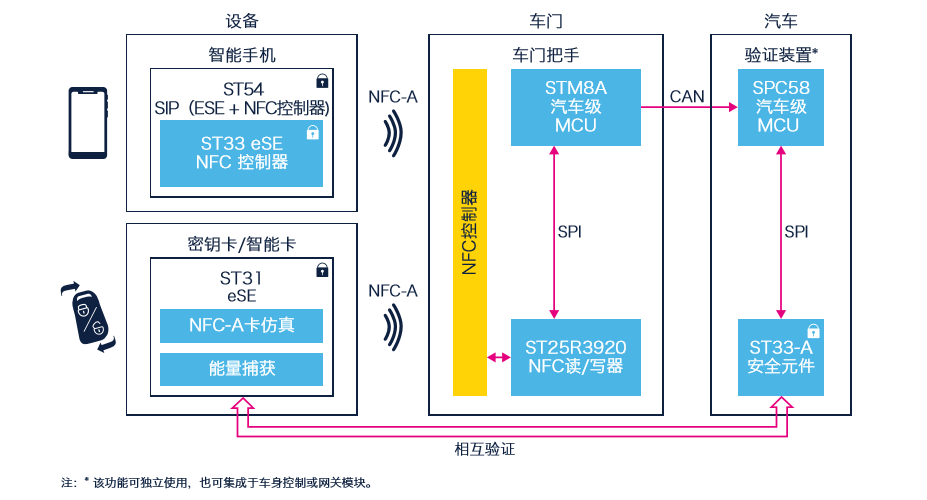
# 摘要
NFC(Near Field Communication,近场通信)技术是一项允许电子设备在短距离内进行无线通信的技术。本文首先介绍了NFC技术的起源、发展、工作原理及应用领域,并阐述了NFC与RFID(Radio-Frequency Identification,无线射频识别)技术的关系。随后,本文重点介绍了PN532模块的硬件特性、配置及读写基础,并探讨了
PNOZ继电器维护与测试:标准流程和最佳实践

# 摘要
PNOZ继电器作为工业控制系统中不可或缺的组件,其可靠性对生产安全至关重要。本文系统介绍了PNOZ继电器的基础知识、维护流程、测试方法和故障处理策略,并提供了特定应用案例分析。同时,针对未来发展趋势,本文探讨了新兴技术在PNOZ继电器中的应用前景,以及行业标准的更新和最佳实践的推广。通过对维护流程和故障处理的深入探讨,本文旨在为工程师提供实用的继电器维护与故障处
【探索JWT扩展属性】:高级JWT用法实战解析

# 摘要
本文旨在介绍JSON Web Token(JWT)的基础知识、结构组成、标准属性及其在业务中的应用。首先,我们概述了JWT的概念及其在身份验证和信息交换中的作用。接着,文章详细解析了JWT的内部结构,包括头部(Header)、载荷(Payload)和签名(Signature),并解释了标准属性如发行者(iss)、主题(sub)、受众(aud
Altium性能优化:编写高性能设计脚本的6大技巧

# 摘要
本文系统地探讨了基于Altium设计脚本的性能优化方法与实践技巧。首先介绍了Altium设计脚本的基础知识和性能优化的重要性,强调了缩短设计周期和提高系统资源利用效率的必要性。随后,详细解析了Altium设计脚本的运行机制及性能分析工具的应用。文章第三章到第四章重点讲述了编写高性能设计脚本的实践技巧,包括代码优化原则、脚
Qt布局管理技巧

# 摘要
本文深入探讨了Qt框架中的布局管理技术,从基础概念到深入应用,再到实践技巧和性能优化,系统地阐述了布局管理器的种类、特点及其适用场景。文章详细介绍了布局嵌套、合并技术,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )