ResNet18深度学习模型:入门指南,开启你的AI之旅
发布时间: 2024-07-02 03:33:48 阅读量: 469 订阅数: 128 

使用MRI上的3D ResNet-18进行阿尔茨海默氏病检测:该模型使用MRI上的ResNet-18模型检测阿尔茨海默氏病。 我们提出了一种在 3D CNN 中利用迁移学习的方法。-matlab开发

# 1. ResNet18模型简介
ResNet18模型是计算机视觉领域中一种流行的深度学习模型,它以其在图像分类和目标检测任务中的出色性能而闻名。ResNet18模型属于残差网络(ResNet)家族,它是一种卷积神经网络(CNN),具有独特的残差连接结构。残差连接允许模型跳过中间层,直接连接到更深层的层,从而缓解了梯度消失问题并提高了模型的训练效率。
ResNet18模型由18个卷积层组成,其中包括一个卷积核大小为7x7的卷积层和16个卷积核大小为3x3的卷积层。该模型还包含一个全局平均池化层和一个全连接层,用于图像分类任务。在目标检测任务中,ResNet18模型通常用作特征提取器,其输出特征图被输入到目标检测头中。
# 2. ResNet18模型的理论基础
### 2.1 卷积神经网络(CNN)基础
#### 2.1.1 卷积操作
卷积操作是CNN的核心操作,它通过滑动一个称为卷积核(或滤波器)的矩阵来提取图像特征。卷积核的大小通常为3x3或5x5,它在图像上滑动,逐元素与图像像素相乘,然后将结果求和得到一个新的值。这个值称为激活值,它表示图像中该区域的特征。
```python
import numpy as np
# 定义一个3x3的卷积核
kernel = np.array([[1, 2, 1],
[0, 0, 0],
[-1, -2, -1]])
# 定义一个5x5的输入图像
image = np.array([[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
# 执行卷积操作
activation = np.zeros((3, 3)) # 初始化激活值矩阵
for i in range(3):
for j in range(3):
activation[i, j] = np.sum(kernel * image[i:i+3, j:j+3])
print(activation)
```
**代码逻辑分析:**
* 循环遍历图像中的每个3x3区域。
* 将卷积核与该区域的像素逐元素相乘。
* 将乘积求和得到激活值。
#### 2.1.2 池化操作
池化操作是CNN中另一种重要的操作,它用于减少特征图的大小并提高模型的鲁棒性。池化操作通常使用最大池化或平均池化。最大池化选择一个区域内的最大值作为输出,而平均池化则选择平均值。
```python
import numpy as np
# 定义一个2x2的最大池化操作
pool_size = (2, 2)
# 定义一个5x5的输入特征图
feature_map = np.array([[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
# 执行最大池化操作
pooled_feature_map = np.zeros((3, 3)) # 初始化池化后的特征图
for i in range(3):
for j in range(3):
pooled_feature_map[i, j] = np.max(feature_map[i*2:(i+1)*2, j*2:(j+1)*2])
print(pooled_feature_map)
```
**代码逻辑分析:**
* 循环遍历特征图中的每个2x2区域。
* 对于每个区域,选择最大值作为输出。
### 2.2 残差网络(ResNet)原理
#### 2.2.1 ResNet的基本结构
ResNet是一种深度卷积神经网络,它通过引入残差块(Residual Block)解决了深度网络的梯度消失问题。残差块由一个卷积层和一个恒等映射组成。恒等映射将输入直接传递到输出,而卷积层则学习残差(输入和输出之间的差异)。
```
+-----------------+
| Convolutional Layer |
+-----------------+
|
V
+-----------------+
| Identity Mapping |
+-----------------+
|
V
+-----------------+
| Convolutional Layer |
+-----------------+
```
**Mermaid流程图:**
```mermaid
graph LR
subgraph ResNet Block
A[Convolutional Layer] --> B[Identity Mapping]
B --> C[Convolutional Layer]
end
```
#### 2.2.2 ResNet的优势
ResNet具有以下优势:
* **解决梯度消失问题:**残差块允许梯度直接从输出流回输入,缓解了深度网络中的梯度消失问题。
* **提高准确性:**ResNet的深度结构使它能够学习更复杂的特征,从而提高模型的准确性。
* **减少过拟合:**恒等映射提供了额外的正则化,有助于减少过拟合。
# 3. ResNet18模型的实践应用
### 3.1 图像分类任务
#### 3.1.1 数据集的准备
图像分类任务需要使用带标签的图像数据集。常用的图像分类数据集包括 ImageNet、CIFAR-10 和 MNIST。ImageNet 是一个包含超过 1000 万张图像的大型数据集,用于训练和评估图像分类模型。CIFAR-10 和 MNIST 是规模较小的数据集,分别包含 60000 张和 70000 张图像。
在使用图像分类数据集时,需要对数据进行预处理,包括调整图像大小、归一化像素值和数据增强。数据增强技术可以生成更多样化的训练数据,从而提高模型的泛化能力。
#### 3.1.2 模型的训练和评估
ResNet18 模型可以通过 PyTorch、TensorFlow 等深度学习框架进行训练。训练过程包括以下步骤:
1. 定义模型架构:加载预训练的 ResNet18 模型或从头开始定义模型架构。
2. 定义损失函数:图像分类任务通常使用交叉熵损失函数。
3. 定义优化器:优化器用于更新模型权重,常用的优化器包括 SGD、Adam 和 RMSprop。
4. 训练模型:通过迭代数据集,更新模型权重,最小化损失函数。
5. 评估模型:使用验证集或测试集评估模型的性能,计算准确率、召回率和 F1 值等指标。
### 3.2 目标检测任务
#### 3.2.1 训练目标检测模型
目标检测任务需要使用带有边界框标签的图像数据集。常用的目标检测数据集包括 COCO、Pascal VOC 和 ImageNet Detection。COCO 是一个包含超过 20 万张图像的大型数据集,用于训练和评估目标检测模型。Pascal VOC 和 ImageNet Detection 是规模较小的数据集,分别包含 11000 张和 20000 张图像。
在使用目标检测数据集时,需要对数据进行预处理,包括调整图像大小、归一化像素值和生成边界框标签。
训练目标检测模型的过程与图像分类模型类似,但需要使用不同的损失函数和评估指标。常用的目标检测损失函数包括交叉熵损失和边界框回归损失。常用的评估指标包括平均精度(AP)和平均召回率(AR)。
#### 3.2.2 模型的评估和改进
目标检测模型的评估需要使用验证集或测试集。评估指标包括 AP、AR 和每秒帧数(FPS)。FPS 是衡量模型推理速度的指标,对于实时目标检测任务非常重要。
为了提高目标检测模型的性能,可以采用以下方法:
1. 使用更深或更宽的模型架构。
2. 使用更强大的特征提取器,如 ResNet 或 Inception。
3. 使用更有效的目标检测算法,如 Faster R-CNN 或 YOLO。
4. 使用数据增强技术生成更多样化的训练数据。
5. 使用正则化技术防止模型过拟合。
# 4. ResNet18模型的优化和调优
### 4.1 模型超参数的优化
#### 4.1.1 学习率的调整
学习率是优化器在更新模型权重时所采取的步长。适当的学习率对于模型的收敛速度和最终性能至关重要。
**代码块:**
```python
import torch.optim as optim
# 定义学习率
learning_rate = 0.01
# 创建优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
```
**逻辑分析:**
* `optim.SGD`是PyTorch中用于随机梯度下降(SGD)优化器的类。
* `model.parameters()`获取模型中所有可训练参数的迭代器。
* `lr`参数指定学习率。
**参数说明:**
* `model`: 要训练的ResNet18模型。
* `learning_rate`: 学习率。
#### 4.1.2 正则化的应用
正则化技术可以防止模型过拟合,从而提高泛化能力。常用的正则化方法包括L1正则化和L2正则化。
**代码块:**
```python
import torch.nn as nn
# 定义L2正则化系数
weight_decay = 0.001
# 添加L2正则化到损失函数
loss_function = nn.CrossEntropyLoss() + weight_decay * nn.MSELoss(model.parameters())
```
**逻辑分析:**
* `nn.CrossEntropyLoss()`是PyTorch中用于多分类任务的损失函数。
* `nn.MSELoss()`是PyTorch中用于回归任务的损失函数。
* `weight_decay`参数指定L2正则化系数。
**参数说明:**
* `model`: 要训练的ResNet18模型。
* `weight_decay`: L2正则化系数。
### 4.2 模型结构的调优
#### 4.2.1 层数和滤波器的选择
ResNet18模型的层数和滤波器数量会影响其容量和计算复杂度。
**表格:**
| 层数 | 滤波器数量 | 模型容量 | 计算复杂度 |
|---|---|---|---|
| 18 | 64 | 小 | 低 |
| 34 | 128 | 中 | 中 |
| 50 | 256 | 大 | 高 |
**Mermaid流程图:**
```mermaid
graph LR
subgraph ResNet18
A[18层] --> B[64滤波器]
B --> C[小容量]
C --> D[低复杂度]
end
subgraph ResNet34
A[34层] --> B[128滤波器]
B --> C[中容量]
C --> D[中复杂度]
end
subgraph ResNet50
A[50层] --> B[256滤波器]
B --> C[大容量]
C --> D[高复杂度]
end
```
#### 4.2.2 激活函数的替换
激活函数引入非线性到模型中,从而使模型能够学习复杂的关系。常用的激活函数包括ReLU、Sigmoid和Tanh。
**代码块:**
```python
import torch.nn as nn
# 替换ReLU激活函数为Sigmoid
model.relu = nn.Sigmoid()
```
**逻辑分析:**
* `nn.Sigmoid()`是PyTorch中用于Sigmoid激活函数的类。
* 通过将`model.relu`替换为`nn.Sigmoid()`,将ReLU激活函数替换为Sigmoid激活函数。
**参数说明:**
* `model`: 要训练的ResNet18模型。
# 5. ResNet18模型的部署和应用
### 5.1 模型的部署
**5.1.1 云端部署**
云端部署是指将训练好的ResNet18模型部署到云计算平台上,例如AWS、Azure或Google Cloud。云端部署具有以下优势:
- **可扩展性:**云平台可以提供弹性可扩展的计算资源,以满足不断变化的工作负载需求。
- **高可用性:**云平台通常具有冗余和故障转移机制,确保模型的高可用性。
- **低维护:**云平台负责基础设施的维护和更新,减少了模型维护的负担。
**云端部署步骤:**
1. **创建云实例:**在云平台上创建虚拟机或容器实例,作为模型部署的目标环境。
2. **上传模型:**将训练好的ResNet18模型上传到云实例。
3. **配置服务:**配置云服务,例如API网关或函数服务,以将模型公开为可访问的端点。
4. **监控和管理:**使用云平台提供的监控和管理工具,跟踪模型的性能和健康状况。
**5.1.2 边缘设备部署**
边缘设备部署是指将ResNet18模型部署到边缘设备上,例如智能手机、物联网设备或嵌入式系统。边缘设备部署具有以下优势:
- **低延迟:**边缘设备可以减少模型推理的延迟,因为数据不需要传输到云端。
- **隐私:**边缘设备部署可以保护敏感数据,因为它不需要传输到云端。
- **脱机操作:**边缘设备可以在没有互联网连接的情况下操作,确保模型的可用性。
**边缘设备部署步骤:**
1. **优化模型:**对ResNet18模型进行优化,以减少其大小和计算复杂度,使其适合在边缘设备上部署。
2. **编译模型:**将优化后的模型编译为可部署的格式,例如TensorFlow Lite或ONNX。
3. **集成到设备:**将编译后的模型集成到边缘设备的软件或固件中。
4. **测试和部署:**在边缘设备上测试模型的性能,并将其部署到生产环境中。
### 5.2 模型的应用场景
ResNet18模型已广泛应用于各种领域,包括:
**5.2.1 医疗影像分析**
ResNet18模型在医疗影像分析中得到了广泛的应用,例如:
- **疾病诊断:**通过分析X射线、CT扫描和MRI图像,诊断疾病,如癌症、心脏病和骨质疏松症。
- **医学图像分割:**分割医学图像中的不同结构,如器官、组织和病变。
- **医学影像生成:**生成合成医学图像,用于训练和研究目的。
**5.2.2 智能安防**
ResNet18模型在智能安防领域也有着重要的应用,例如:
- **目标检测:**检测和识别图像或视频中的物体,如行人、车辆和可疑物品。
- **人脸识别:**识别和验证图像或视频中的人脸。
- **行为分析:**分析图像或视频中的人员行为,检测异常行为或可疑活动。
# 6. ResNet18模型的未来发展和展望
### 6.1 模型的改进方向
**6.1.1 架构的创新**
随着深度学习技术的不断发展,ResNet18模型的架构也在不断地被改进和创新。例如,引入了注意力机制、跳层连接和可变形卷积等技术,可以有效地提升模型的性能。
**6.1.2 训练技术的提升**
除了架构的创新,训练技术也在不断地提升。例如,引入了对抗训练、知识蒸馏和自监督学习等技术,可以帮助模型更好地学习数据中的特征,提高模型的泛化能力。
### 6.2 模型的应用前景
ResNet18模型由于其优异的性能和广泛的适用性,在未来有着广阔的应用前景。
**6.2.1 自动驾驶**
自动驾驶需要对周围环境进行实时感知和理解,ResNet18模型可以作为图像识别和目标检测的基础模型,为自动驾驶提供视觉感知能力。
**6.2.2 机器翻译**
机器翻译需要对文本进行理解和翻译,ResNet18模型可以作为文本嵌入和语义分析的基础模型,为机器翻译提供语言理解能力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 ResNet18 深度学习模型,从入门指南到高级应用。专栏涵盖了广泛的主题,包括:
* **网络架构:**揭示 ResNet18 的残差连接和捷径连接,了解其如何提升性能。
* **训练技巧:**优化超参数、数据增强和正则化,以提高模型泛化能力。
* **应用:**探索 ResNet18 在图像分类、语义分割、医学影像和目标检测等领域的应用。
* **比较:**将 ResNet18 与其他 CNN 模型进行比较,评估其性能、效率和架构。
* **变体:**介绍 ResNet18 的变体,如 ResNeXt、ResNet-D 和 Wide ResNet。
* **实现:**提供 PyTorch、TensorFlow 和 Keras 中的代码示例,帮助读者快速上手。
* **部署:**讨论云端和嵌入式设备上的部署策略,以将模型推向生产环境。
* **性能优化:**加速训练和推理,以提高模型效率。
* **故障排除:**解决常见问题和错误,避免模型训练和部署中的陷阱。
通过深入了解 ResNet18,读者可以掌握深度学习模型的原理和应用,并为其在各种 AI 领域的实际使用做好准备。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电力电子技术基础:7个核心概念与原理让你快速入门
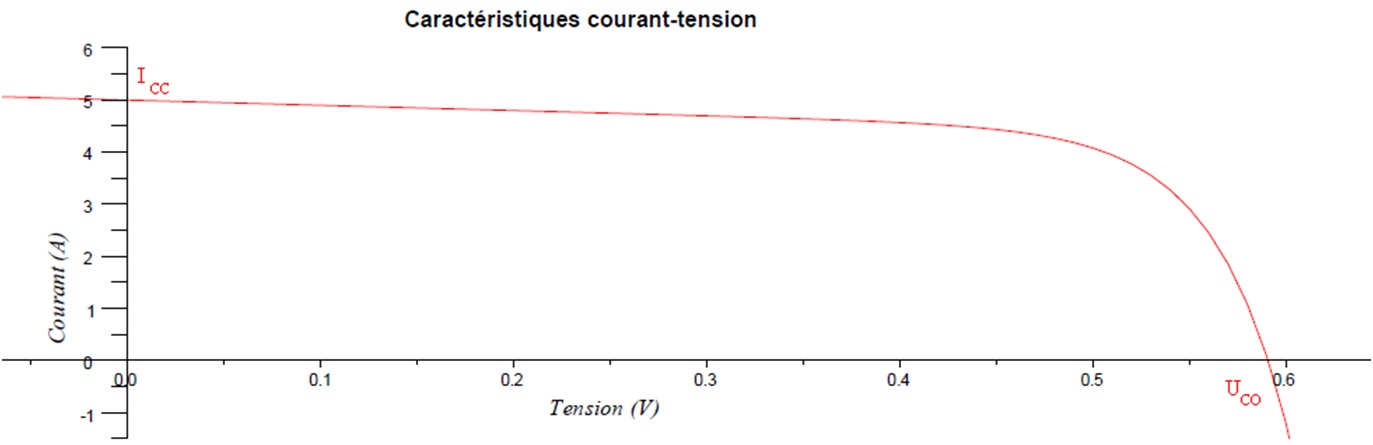
# 摘要
电力电子技术作为电力系统与电子技术相结合的交叉学科,对于现代电力系统的发展起着至关重要的作用。本文首先对电力电子技术进行概述,并深入解析其核心概念,包括电力电子变换器的分类、电力半导体器件的特点、控制策略及调制技术。进一步,本文探讨了电路理论基础、功率电子变换原理以及热管理与散热设计等基础理论与数学模型。文章接
PDF格式全面剖析:内部结构深度解读与高级操作技巧

# 摘要
PDF格式因其跨平台性和保持文档原貌的优势,在数字出版、办公自动化、法律和医疗等多个行业中得到广泛应用。本文首先概述了PDF格式的基本概念及其内部结构,包括文档组成元素、文件头、交叉引用表和PDF语法。随后,文章深入探讨了进行PDF文档高级操作的技巧,如编辑内容、处理表单、交互功能以及文档安全性的增强方法。接着,
【施乐打印机MIB效率提升秘籍】:优化技巧助你实现打印效能飞跃

# 摘要
施乐打印机中的管理信息库(MIB)是提升打印设备性能的关键技术,本文对MIB的基础知识进行了介绍,并理论分析了其效率。通过对MIB的工作原理和与打印机性能关系的探讨,以及效率提升的理论基础研究,如响应时间和吞吐量的计算模型,本文提供了优化打印机MIB的实用技巧,包括硬件升级、软件和固件调
FANUC机器人编程新手指南:掌握编程基础的7个技巧

# 摘要
本文提供了FANUC机器人编程的全面概览,涵盖从基础操作到高级编程技巧,以及工业自动化集成的综合应用。文章首先介绍了FANUC机器人的控制系统、用户界面和基本编程概念。随后,深入探讨了运动控制、I/O操作
【移远EC200D-CN固件升级速通】:按图索骥,轻松搞定固件更新

# 摘要
本文全面概述了移远EC200D-CN固件升级的过程,包括前期的准备工作、实际操作步骤、升级后的优化与维护以及案例研究和技巧分享。文章首先强调了进行硬件与系统兼容性检查、搭建正确的软件环境、备份现有固件与数据的重要性。其次,详细介绍了固件升级工具的使用、升级过程监控以及升级后的验证和测试流程。在固件升级后的章节中,本文探讨了系统性能优化和日常维护的策略,并分享了用户反馈和升级技巧。
【二次开发策略】:拉伸参数在tc itch中的应用,构建高效开发环境的秘诀

# 摘要
本文旨在详细阐述二次开发策略和拉伸参数理论,并探讨tc itch环境搭建和优化。首先,概述了二次开发的策略,强调拉伸参数在其中的重要作用。接着,详细分析了拉伸参数的定义、重要性以及在tc itch环境中的应用原理和设计原则。第三部分专注于tc itch环境搭建,从基本步骤到高效开发环境构建,再到性能调
CANopen同步模式实战:精确运动控制的秘籍
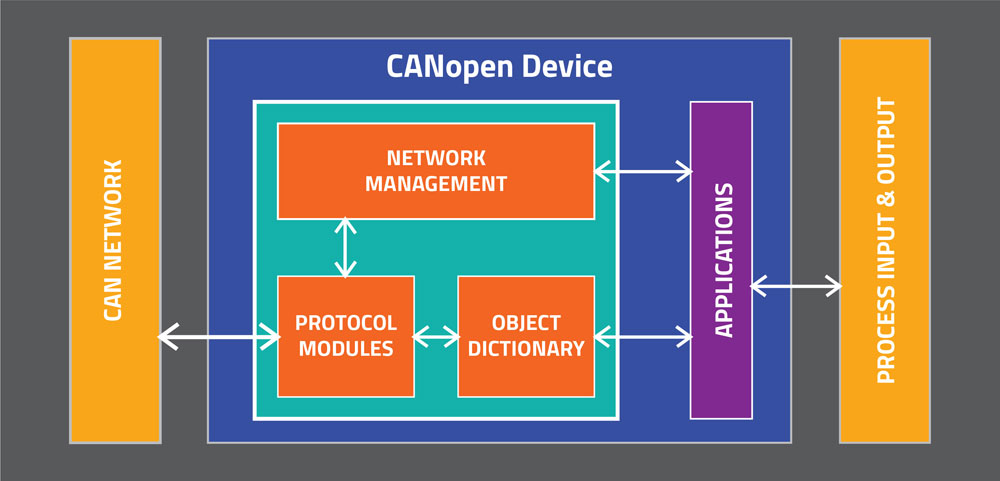
# 摘要
CANopen是一种广泛应用在自动化网络通信中的协议,其中同步模式作为其重要特性,尤其在对时间敏感的应用场景中扮演着关键角色。本文首先介绍了CANopen同步模式的基础知识,然后详细分析了同步机制的关键组成部分,包括同步消息(SYNC)的原理、同步窗口(SYNC Window)的配置以及同步计数器(SYNC Counter)的管理。文章接着
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )