【Python Feeds库入门指南】:新手必学的feeds库基础操作与实战案例
发布时间: 2024-10-13 13:10:42 阅读量: 68 订阅数: 40 
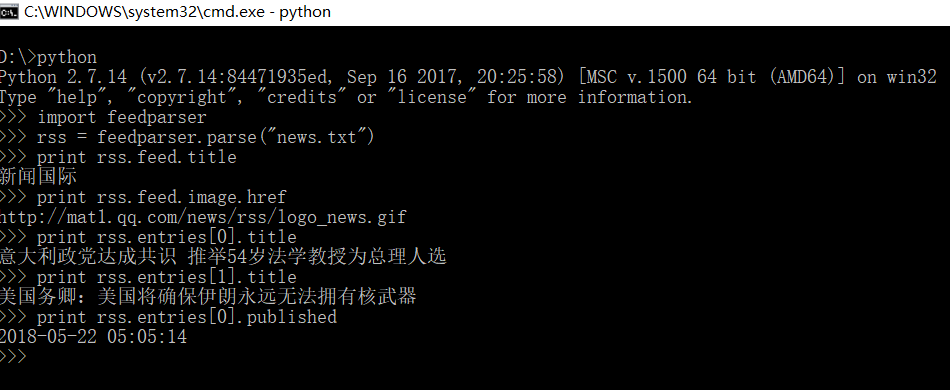
# 1. Python Feeds库概述
Python Feeds库是一个专门用于处理RSS/Atom源的库,它提供了一套简洁的API,使得开发者能够轻松地抓取和解析这些源。随着信息聚合需求的增长,Feeds库在数据抓取、内容聚合和新闻阅读器开发等领域展现了巨大的应用潜力。
## 1.1 Feeds库的起源与发展
Feeds库最初是为了简化RSS/Atom源的处理流程而设计的。它的API设计简洁直观,使得即使是新手开发者也能够快速上手。随着时间的推移,Feeds库不断优化更新,支持了更多的RSS/Atom格式变种,并增加了新的功能以适应不断变化的网络环境。
## 1.2 应用场景
在现代网络环境中,信息更新速度极快,Feeds库可以帮助开发者快速构建实时更新的应用程序。例如,新闻聚合应用、博客订阅系统以及社交媒体数据监控等。这些应用场景不仅展示了Feeds库的功能多样性,也体现了其在信息处理领域的实用价值。
## 1.3 本文内容结构
本文将从基础知识开始,逐步深入到Feeds库的安装、配置、API接口、数据结构、实践应用、实战案例以及高级应用。每个章节都会有详细的解释、代码示例和操作步骤,帮助读者全面理解和掌握Python Feeds库的使用方法。
以上为第一章的内容概述,接下来的章节将会详细介绍Feeds库的基础操作和实际应用。
# 2. Feeds库基础操作
## 2.1 安装与配置Feeds库
### 2.1.1 通过pip安装Feeds库
在开始使用Feeds库之前,我们需要先进行安装和配置。Python的包管理工具pip为我们提供了一个便捷的方式来安装第三方库。以下是通过pip安装Feeds库的步骤:
```bash
pip install feeds
```
这条命令会从Python的包索引(PyPI)中下载并安装Feeds库。安装完成后,我们就可以在Python脚本中导入并使用Feeds库了。
### 2.1.2 Feeds库的基本配置
安装完成Feeds库后,我们可能需要对其进行一些基本配置,以便更好地满足我们的需求。例如,我们可以设置Feeds库的日志级别,以便在调试时获取更多信息。
```python
import logging
logging.basicConfig(level=logging.DEBUG)
```
通过上述代码,我们将日志级别设置为DEBUG,这样在运行Feeds库相关代码时,我们可以在控制台看到更多的调试信息。
### 2.1.3 使用虚拟环境进行配置
对于大型项目,我们通常建议使用虚拟环境来管理项目依赖。虚拟环境可以让我们为每个项目创建独立的Python环境,从而避免不同项目之间的依赖冲突。以下是创建虚拟环境的步骤:
```bash
# 创建虚拟环境
python -m venv feeds_env
# 激活虚拟环境(Windows)
feeds_env\Scripts\activate
# 激活虚拟环境(Unix或MacOS)
source feeds_env/bin/activate
# 安装Feeds库
pip install feeds
```
通过虚拟环境,我们可以在不影响系统中其他Python项目的前提下,独立地安装和管理Feeds库。
## 2.2 Feeds库的API接口概览
### 2.2.1 获取RSS/Atom源的API
Feeds库提供了一个简单的方法来获取RSS/Atom源,我们可以使用`get_feeds`函数来完成这个任务。以下是获取RSS源的基本示例:
```python
from feeds import Feeds
# 获取RSS源
url = '***'
feeds = Feeds(url)
# 获取RSS源中的条目
for feed in feeds.get():
print(feed.title)
```
在这个示例中,我们首先导入了Feeds类,然后创建了一个Feeds对象,并传入了RSS源的URL。通过调用`get`方法,我们可以获取到RSS源中的所有条目,并打印出每个条目的标题。
### 2.2.2 解析RSS/Atom条目的API
获取到RSS/Atom源之后,我们可能需要进一步解析这些条目。Feeds库提供了`get`方法的多个参数来帮助我们过滤和解析条目。以下是解析RSS/Atom条目的基本示例:
```python
from feeds import Feeds
# 获取RSS源
url = '***'
feeds = Feeds(url)
# 解析RSS源中的条目
for feed in feeds.get(feed_count=5, order_by='published'):
print(feed.title, feed.link)
```
在这个示例中,我们设置了`feed_count=5`来限制获取的条目数量,并通过`order_by='published'`参数来按照发布日期进行排序。
## 2.3 Feeds库的数据结构
### 2.3.1 Feeds对象
Feeds对象代表了一个RSS/Atom源,它包含了源中的所有条目。我们可以通过Feeds对象来获取和解析RSS/Atom源。
### 2.3.2 Entry对象
每个条目都是一个Entry对象,它包含了条目的详细信息,如标题、链接、发布日期等。我们可以通过遍历Feeds对象来访问每个条目,并获取条目的详细信息。
```python
from feeds import Feeds
# 获取RSS源
url = '***'
feeds = Feeds(url)
# 遍历条目
for entry in feeds.get():
print(entry.title, entry.link, entry.published)
```
在这个示例中,我们遍历了Feeds对象中的所有条目,并打印出了每个条目的标题、链接和发布日期。
## 2.4 Feeds库的数据结构深入理解
### 2.4.1 Feeds对象的属性和方法
Feeds对象不仅包含了条目列表,还提供了一些属性和方法来帮助我们更好地理解和操作RSS/Atom源。
#### *.*.*.* Feeds对象的属性
- `feed.title`:获取RSS/Atom源的标题。
- `feed.link`:获取RSS/Atom源的链接。
- `feed.description`:获取RSS/Atom源的描述。
#### *.*.*.* Feeds对象的方法
- `feed.get()`:获取RSS/Atom源中的条目列表。
- `feed.add_entry(entry)`:向RSS/Atom源中添加一个新的条目。
### 2.4.2 Entry对象的属性和方法
每个条目都是一个Entry对象,它包含了条目的详细信息,如标题、链接、发布日期等。
#### *.*.*.* Entry对象的属性
- `entry.title`:获取条目的标题。
- `entry.link`:获取条目的链接。
- `entry.published`:获取条目的发布日期。
#### *.*.*.* Entry对象的方法
- `entry.to_dict()`:将条目转换为字典格式。
通过上述内容,我们已经对Feeds库的基础操作有了初步的了解。接下来,我们将深入探讨如何在实际项目中应用Feeds库,实现数据抓取与处理、错误处理与性能优化等功能。
# 3. Feeds库的实践应用
在本章节中,我们将深入探讨Python Feeds库的实践应用,从基本的数据抓取与处理开始,逐步介绍进阶的数据处理技巧,以及错误处理与性能优化的方法。
## 3.1 基本的数据抓取与处理
### 3.1.1 抓取RSS/Atom数据流
在开始抓取RSS/Atom数据流之前,我们需要明确数据源的URL。例如,我们可以使用Python的`requests`库来获取数据:
```python
import requests
from feeds import Feeds
# 定义RSS/Atom源的URL
url = '***'
# 使用requests获取数据
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 使用Feeds库解析数据
feed = Feeds.parse(response.content)
print(feed)
else:
print("Error fetching data: Status code", response.status_code)
```
在这个代码块中,我们首先导入`requests`和`feeds`库,然后定义了RSS/Atom源的URL。使用`requests.get`方法获取数据,并检查HTTP请求的状态码是否为200,表示请求成功。如果成功,我们使用`Feeds.parse`方法解析获取到的数据。
### 3.1.2 解析并展示条目信息
在成功获取数据后,我们需要解析并展示RSS/Atom条目的信息。以下是如何操作的示例:
```python
# 假设我们已经有了feed对象
for entry in feed.entries:
print("Title:", entry.title)
print("Published:", entry.published)
print("Link:", entry.link)
print("Summary:", entry.summary)
print("-----")
```
在这个代码段中,我们遍历`feed.entries`列表,每个`entry`代表一个RSS/Atom条目。我们打印出条目的标题、发布时间、链接和摘要信息。
### 3.1.3 数据过滤与排序
在实际应用中,我们可能需要对获取的数据进行过滤和排序。例如,我们可以根据发布时间对条目进行排序,并过滤出最近一天内的条目:
```python
from datetime import datetime, timedelta
# 将字符串转换为datetime对象
one_day_ago = datetime.now() - timedelta(days=1)
# 过滤并排序条目
filtered_entries = sorted(
[entry for entry in feed.entries if entry.published > one_day_ago],
key=lambda x: x.published,
reverse=True
)
for entry in filtered_entries:
print("Filtered Title:", entry.title)
print("Filtered Published:", entry.published)
print("-----")
```
在这个代码段中,我们首先创建了一个`one_day_ago`变量,表示从当前时间向前推一天的时间点。然后,我们使用列表推导式过滤出最近一天内的条目,并按照发布时间进行排序。
### 3.1.4 数据存储与输出格式化
在获取和处理数据后,我们可能需要将数据存储到文件或数据库中,或者以特定的格式输出。以下是一个将条目信息输出到CSV文件的示例:
```python
import csv
import os
# 检查CSV文件是否存在,不存在则创建
csv_file = 'entries.csv'
if not os.path.exists(csv_file):
with open(csv_file, 'w', newline='') as ***
***
***['Title', 'Published', 'Link', 'Summary'])
# 将条目信息写入CSV文件
with open(csv_file, 'a', newline='') as ***
***
***
***[
entry.title,
entry.published,
entry.link,
entry.summary
])
```
在这个代码段中,我们首先检查CSV文件是否存在,如果不存在则创建一个新文件,并写入列标题。然后,我们将过滤后的条目信息逐行写入CSV文件中。
### 3.1.5 错误处理机制
在抓取和处理数据的过程中,我们可能会遇到各种错误,例如网络请求失败、数据格式不正确等。以下是使用try-except结构来处理错误的示例:
```python
try:
# 尝试获取数据
response = requests.get(url)
response.raise_for_status() # 检查HTTP请求是否成功
feed = Feeds.parse(response.content)
except requests.exceptions.HTTPError as errh:
print("Http Error:", errh)
except requests.exceptions.ConnectionError as errc:
print("Error Connecting:", errc)
except requests.exceptions.Timeout as errt:
print("Timeout Error:", errt)
except requests.exceptions.RequestException as err:
print("OOps: Something Else", err)
except Feeds.ParseError as pe:
print("Parse error:", pe)
```
在这个代码段中,我们使用try-except结构来捕获可能发生的异常。`requests.exceptions.HTTPError`、`ConnectionError`、`Timeout`和`RequestException`分别捕获不同类型的网络请求错误。`Feeds.ParseError`捕获解析错误。
### 3.1.6 优化抓取性能的方法
为了提高抓取性能,我们可以采取以下措施:
1. **并发请求**:使用多线程或多进程来并发抓取多个RSS/Atom源。
2. **缓存机制**:对已经抓取过的数据进行缓存,避免重复抓取。
3. **限制请求频率**:设置合理的请求间隔,避免对服务器造成过大压力。
以下是一个使用`concurrent.futures`库实现多线程抓取的示例:
```python
import concurrent.futures
def fetch_feed(url):
try:
response = requests.get(url)
response.raise_for_status()
feed = Feeds.parse(response.content)
return feed
except Exception as e:
print(f"Error fetching {url}: {e}")
return None
# 定义RSS/Atom源的URL列表
urls = ['***', '***']
# 使用线程池并发抓取
with concurrent.futures.ThreadPoolExecutor() as executor:
future_to_url = {executor.submit(fetch_feed, url): url for url in urls}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
feed = future.result()
if feed:
for entry in feed.entries:
print("Title:", entry.title)
except Exception as exc:
print(f"{url} generated an exception: {exc}")
```
在这个代码段中,我们定义了一个`fetch_feed`函数,用于抓取单个RSS/Atom源。然后,我们使用`concurrent.futures.ThreadPoolExecutor`创建一个线程池,并提交多个抓取任务。当任务完成时,我们打印出条目信息。
## 3.2 错误处理与性能优化
### 3.2.1 错误处理机制
错误处理是软件开发中不可或缺的一部分。在使用Feeds库进行数据抓取时,我们可能遇到各种类型的错误,例如网络请求失败、数据解析错误等。错误处理机制可以确保程序的健壮性和稳定性。
### 3.2.2 优化抓取性能的方法
性能优化是提高数据抓取效率的关键。以下是几种常见的优化方法:
#### *.*.*.* 并发抓取
使用多线程或多进程可以显著提高抓取效率。Python的`concurrent.futures`模块提供了一个简单易用的接口来实现并发执行。
#### *.*.*.* 缓存机制
缓存机制可以减少对数据源的重复请求,从而节省时间和带宽。Python的`functools.lru_cache`装饰器可以用来实现简单的缓存功能。
#### *.*.*.* 设置合理的请求间隔
为了避免对数据源服务器造成过大压力,我们应该设置合理的请求间隔。Python的`time.sleep`函数可以帮助我们在请求之间暂停一段时间。
### 3.2.3 示例:并发抓取与缓存
以下是一个结合并发抓取和缓存机制的示例:
```python
import concurrent.futures
from functools import lru_cache
import requests
from feeds import Feeds
# 使用lru_cache装饰器实现缓存机制
@lru_cache(maxsize=128)
def fetch_feed_cached(url):
return fetch_feed(url)
# 定义fetch_feed函数,使用requests获取数据
def fetch_feed(url):
try:
response = requests.get(url)
response.raise_for_status()
feed = Feeds.parse(response.content)
return feed
except Exception as e:
print(f"Error fetching {url}: {e}")
return None
# 定义RSS/Atom源的URL列表
urls = ['***', '***']
# 使用线程池并发抓取
with concurrent.futures.ThreadPoolExecutor() as executor:
future_to_url = {executor.submit(fetch_feed_cached, url): url for url in urls}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
feed = future.result()
if feed:
for entry in feed.entries:
print("Title:", entry.title)
except Exception as exc:
print(f"{url} generated an exception: {exc}")
```
在这个代码段中,我们定义了一个`fetch_feed_cached`函数,它使用`lru_cache`装饰器来缓存抓取结果。然后,我们使用`concurrent.futures.ThreadPoolExecutor`创建一个线程池,并提交多个抓取任务。每个任务都会先检查缓存中是否有数据,如果没有,则进行实际的抓取操作。
### 3.2.4 总结
本章节介绍了Python Feeds库的实践应用,包括基本的数据抓取与处理、进阶的数据处理技巧、错误处理与性能优化的方法。通过实际的代码示例,我们展示了如何使用Feeds库进行高效的数据抓取和处理。这些技巧和方法不仅可以应用于RSS/Atom数据流,也可以用于其他类型的数据抓取任务。
# 4. Feeds库实战案例
在本章节中,我们将通过具体的实战案例来深入探讨Feeds库的应用,包括新闻聚合、博客订阅系统以及社交媒体数据监控等方面。通过这些案例,我们将展示Feeds库在实际工作中的强大功能和灵活性,以及如何将这些功能应用到日常的项目开发中。
## 4.1 新闻聚合应用
### 4.1.1 构建新闻阅读器
在新闻聚合应用中,Feeds库可以用来构建一个简易的新闻阅读器。新闻阅读器的核心功能是抓取多个新闻源的RSS/Atom数据,然后解析并展示给用户。以下是构建新闻阅读器的基本步骤:
1. **确定新闻源**:首先,我们需要确定要抓取的新闻源。这可能是一些主流新闻网站的RSS/Atom源。
2. **抓取RSS/Atom数据**:使用Feeds库提供的API抓取RSS/Atom数据流。
3. **解析条目信息**:解析RSS/Atom条目,提取出新闻标题、链接、摘要等信息。
4. **展示给用户**:将解析后的新闻条目以某种形式展示给用户,例如在网页上显示或发送到邮件订阅列表。
下面是一个简单的Python脚本示例,展示了如何使用Feeds库抓取和解析RSS数据流,并打印出新闻标题和链接:
```python
from feeds import Feeds
# 初始化Feeds对象
feed = Feeds()
# 设置要抓取的新闻源RSS URL
feed.add('***')
# 抓取RSS数据流
entries = feed.get('rss')
# 遍历并打印新闻条目
for entry in entries:
print(f"Title: {entry.title}")
print(f"Link: {entry.link}")
```
### 4.1.2 实现自定义的内容过滤
在构建新闻阅读器的过程中,我们可能希望根据用户的兴趣或偏好来过滤新闻内容。Feeds库允许我们通过自定义过滤器来实现这一点。以下是实现自定义内容过滤的步骤:
1. **定义过滤条件**:根据用户设定的过滤条件来定义一个过滤函数。
2. **应用过滤函数**:在解析RSS/Atom条目时应用过滤函数,筛选出符合用户兴趣的新闻条目。
3. **展示过滤后的结果**:将过滤后的新闻条目展示给用户。
```python
from feeds import Feeds
# 自定义过滤函数
def custom_filter(entry):
# 只选择标题中包含"technology"的新闻条目
return 'technology' in entry.title.lower()
# 初始化Feeds对象
feed = Feeds()
# 设置要抓取的新闻源RSS URL
feed.add('***')
# 抓取RSS数据流
entries = feed.get('rss')
# 应用自定义过滤函数
filtered_entries = filter(custom_filter, entries)
# 遍历并打印过滤后的新闻条目
for entry in filtered_entries:
print(f"Filtered Title: {entry.title}")
print(f"Filtered Link: {entry.link}")
```
## 4.2 博客订阅系统
### 4.2.1 创建个人博客订阅服务
在这一部分,我们将探讨如何使用Feeds库来创建一个个人博客订阅服务。这个服务可以让用户订阅一个或多个博客的RSS/Atom源,并通过电子邮件或其他方式接收最新文章的通知。
### 4.2.2 推送订阅更新通知
为了完成博客订阅服务,我们需要实现一个功能,当博客有新文章发布时,自动发送更新通知给订阅用户。以下是实现这一功能的基本步骤:
1. **收集订阅信息**:创建一个用户订阅信息的数据库或存储系统。
2. **定期检查更新**:设置一个定时任务,定期检查RSS/Atom源是否有更新。
3. **发送通知**:一旦发现新文章,通过电子邮件或其他方式发送更新通知给订阅用户。
```python
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
# 假设我们有一个发送电子邮件的函数
def send_email(subject, body, recipient):
msg = MIMEMultipart()
msg['From'] = 'your_***'
msg['To'] = recipient
msg['Subject'] = subject
msg.attach(MIMEText(body, 'plain'))
with smtplib.SMTP('***', 587) as server:
server.starttls()
server.login('your_***', 'your_password')
server.sendmail('your_***', recipient, msg.as_string())
# 初始化Feeds对象
feed = Feeds()
# 设置要抓取的博客RSS URL
feed.add('***')
# 抓取RSS数据流
entries = feed.get('rss')
# 检查新条目
new_entries = feed.filter_new(entries)
# 遍历新条目并发送通知
for entry in new_entries:
subject = f"New post: {entry.title}"
body = f"New post on {feed.url}:\nTitle: {entry.title}\nLink: {entry.link}"
send_email(subject, body, '***')
```
## 4.3 社交媒体数据监控
### 4.3.1 监控社交媒体话题
在这一部分,我们将探讨如何使用Feeds库来监控社交媒体上的特定话题。例如,我们可以监控Twitter话题标签的RSS源,来跟踪相关讨论的最新动态。
### 4.3.2 数据分析与可视化展示
监控社交媒体话题后,我们可能需要对收集的数据进行分析,并通过可视化的方式展示出来。例如,我们可以统计某个话题的提及频率,并用图表展示出来。以下是实现数据分析与可视化的基本步骤:
1. **抓取RSS数据流**:使用Feeds库抓取社交媒体话题的RSS/Atom源。
2. **解析条目信息**:提取出关键信息,如作者、内容、发布时间等。
3. **数据存储**:将解析后的数据存储到数据库或文件中。
4. **数据分析**:对存储的数据进行分析,如统计提及频率、情感分析等。
5. **可视化展示**:使用图表或仪表盘展示分析结果。
```python
import matplotlib.pyplot as plt
from collections import Counter
# 初始化Feeds对象
feed = Feeds()
# 设置要抓取的Twitter话题RSS URL
feed.add('***')
# 抓取RSS数据流
entries = feed.get('rss')
# 提取并存储话题提及次数
mentions = [entry.title.split("#")[1].split(" ")[0] for entry in entries]
mentions_count = Counter(mentions)
# 数据分析:统计提及频率
most_common = mentions_count.most_common(10)
# 可视化展示:绘制提及频率的条形图
plt.bar(*zip(*most_common))
plt.title('Top 10 Most Mentioned Terms')
plt.xlabel('Terms')
plt.ylabel('Mentions')
plt.show()
```
以上代码示例展示了如何使用Feeds库进行社交媒体数据的抓取、分析和可视化展示。通过这些步骤,我们可以对社交媒体上的热门话题进行实时监控,并以直观的方式展示数据趋势。
# 5. Feeds库的高级应用
## 5.1 集成第三方API服务
### 5.1.1 使用Feeds库结合其他API
在本章节中,我们将探讨如何将Feeds库与其他第三方API服务结合,以实现更为复杂和强大的数据处理任务。这种集成不仅能够增强数据源的多样性,还能够提供更为丰富的数据交互方式。
首先,我们可以通过Python的`requests`模块来调用其他API服务。结合Feeds库,我们可以从RSS/Atom源中获取基础数据,然后使用第三方API来进一步丰富这些数据。例如,我们可以使用一个天气API来为每条新闻条目添加天气信息,或者使用一个翻译API来将新闻标题翻译成不同的语言。
以下是一个简单的示例代码,展示了如何结合Feeds库和一个天气API来为每条新闻条目添加天气信息:
```python
import requests
from feeds import Feed
def get_weather(api_key, city):
url = f"***{api_key}&q={city}"
response = requests.get(url)
weather_data = response.json()
return weather_data
def process_feed(feed_url, api_key):
feed = Feed.fetch(feed_url)
for entry in feed.entries:
city = entry.title.split("-")[0].strip() # 假设标题格式为 "City-News Title"
weather_info = get_weather(api_key, city)
entry.extra['weather'] = weather_info['current']['temp_c'] # 添加温度信息
# 这里可以添加更多的天气信息,如湿度、风速等
process_feed('***', 'YOUR_API_KEY')
```
在这个示例中,我们定义了一个`get_weather`函数来调用天气API,并获取指定城市的天气信息。然后在`process_feed`函数中,我们为每条RSS条目添加了温度信息。这个例子展示了如何将Feeds库与第三方API服务结合起来,为数据添加更多的上下文信息。
### 5.1.2 实现复杂的数据集成任务
通过结合Feeds库和第三方API,我们可以实现复杂的数据集成任务,将来自不同源的数据有机地整合在一起。这样的集成不仅限于获取数据,还包括数据清洗、转换和匹配等多个环节。
例如,我们可以将RSS/Atom源中的新闻条目与社交媒体API获取的数据进行匹配,找出哪些新闻条目在社交媒体上被广泛讨论。我们还可以将新闻条目与维基百科API结合,自动提取条目中提及的人物、地点或组织的相关维基百科页面,为用户提供更丰富的背景信息。
这里是一个简单的示例,展示了如何结合Feeds库和社交媒体API来追踪新闻条目在社交媒体上的讨论情况:
```python
import tweepy
from feeds import Feed
def search_tweets(api, term):
query = f"{term} lang:en -is:retweet"
tweets = api.search_tweets(query=query, count=10, tweet_mode='extended')
return tweets
def process_feed(feed_url, twitter_api):
feed = Feed.fetch(feed_url)
for entry in feed.entries:
tweets = search_tweets(twitter_api, entry.title)
entry.extra['tweets'] = [tweet.full_text for tweet in tweets]
process_feed('***', twitter_api)
```
在这个示例中,我们定义了一个`search_tweets`函数来使用Twitter API搜索与新闻标题相关的推文。然后在`process_feed`函数中,我们将搜索到的推文添加到每条新闻条目的额外信息中。这个例子展示了如何将Feeds库与社交媒体API结合起来,为用户提供更全面的新闻视角。
### 5.1.3 第三方API服务的集成策略
在进行第三方API服务的集成时,我们需要注意以下几点:
- **API限制和配额**:大多数第三方API都有限制和配额。我们需要合理设计API调用策略,避免超出配额限制。
- **错误处理**:API调用可能会失败,我们需要在代码中添加错误处理机制,确保程序的健壮性。
- **数据一致性**:我们需要确保集成后的数据是一致的,避免出现数据冲突或不一致的问题。
### 5.1.4 数据集成的高级技巧
在实现复杂的数据集成任务时,我们可以使用以下高级技巧:
- **缓存机制**:对于频繁调用的API,我们可以使用缓存机制来提高性能和减少API调用次数。
- **异步处理**:对于耗时的API调用,我们可以使用异步处理机制来提高效率。
- **数据流处理**:我们可以使用流处理技术来实时处理数据,例如使用Kafka或Flume等工具。
## 5.2 构建动态数据源
### 5.2.1 动态生成RSS/Atom源
在本章节中,我们将探讨如何动态生成RSS/Atom源。动态生成数据源是一个强大的功能,它可以让我们根据用户需求或者实时数据动态地创建和更新RSS/Atom源。
动态生成RSS/Atom源通常涉及到以下几个步骤:
1. **定义数据源模板**:我们需要定义一个RSS/Atom源的模板,这个模板描述了RSS/Atom源的结构,包括频道信息和条目信息。
2. **填充数据**:我们需要编写代码来填充模板中的数据。这些数据可以来自数据库、API调用或者其他数据源。
3. **生成RSS/Atom格式**:我们需要将填充好的模板转换成RSS/Atom格式,并提供给用户订阅。
以下是一个简单的示例代码,展示了如何动态生成RSS/Atom源:
```python
from flask import Flask, Response
import feeds
import json
app = Flask(__name__)
@app.route('/rss')
def rss():
# 假设我们从数据库或者API获取到新闻列表
news_list = get_news_from_source()
feed = feeds.Feed(
title='Example News Feed',
link='***',
description='Latest news from Example',
language='en'
)
for news in news_list:
feed.add(
title=news['title'],
link=news['link'],
description=news['description'],
author=news['author'],
published=news['published'],
)
return Response(feed.rss_string(), mimetype='application/rss+xml')
def get_news_from_source():
# 这里应该是获取数据的逻辑
# 例如从数据库或者API获取新闻列表
return [
{
'title': 'News 1',
'link': '***',
'description': 'Description of news 1',
'author': 'Author 1',
'published': '2021-01-01T00:00:00Z',
},
{
'title': 'News 2',
'link': '***',
'description': 'Description of news 2',
'author': 'Author 2',
'published': '2021-01-02T00:00:00Z',
},
]
if __name__ == '__main__':
app.run(debug=True)
```
在这个示例中,我们使用Flask框架来创建一个简单的web应用,这个应用提供了一个RSS源。我们定义了一个`rss`路由来生成RSS源,这个路由从一个假设的数据源`get_news_from_source`函数中获取新闻列表,并动态生成RSS内容。
### 5.2.2 定时更新和推送机制
为了保持RSS/Atom源的时效性,我们需要定时更新和推送机制。这可以通过定时任务来实现,例如使用cron作业或者Python的`schedule`库。
以下是一个简单的示例代码,展示了如何使用Python的`schedule`库来定时更新RSS源:
```python
import schedule
import time
from your_rss_generator import update_rss_feed
def job():
update_rss_feed()
# 每天的00:00执行更新RSS源的任务
schedule.every().day.at("00:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
```
在这个示例中,我们定义了一个`job`函数来执行更新RSS源的任务。然后我们使用`schedule`库的`every().day.at("00:00").do(job)`来设置每天00:00执行这个任务。最后,我们进入一个无限循环,不断检查并执行待处理的定时任务。
### 5.2.3 动态数据源的应用场景
动态生成RSS/Atom源有广泛的应用场景,例如:
- **个性化新闻订阅**:用户可以根据自己的兴趣定制新闻源。
- **实时数据通知**:将实时数据转换成RSS/Atom源,用户可以订阅并实时获取更新。
- **内容聚合**:将来自不同源的内容聚合到一个RSS/Atom源中。
## 5.3 扩展Feeds库功能
### 5.3.1 编写自定义解析器插件
在本章节中,我们将探讨如何编写自定义解析器插件来扩展Feeds库的功能。Feeds库本身提供了丰富的API接口,但有时候我们需要处理一些特殊的RSS/Atom格式或者实现一些特定的功能,这时候我们可以编写自定义的解析器插件。
编写自定义解析器插件通常涉及到以下几个步骤:
1. **定义解析器类**:我们需要定义一个继承自Feeds库中的解析器基类的解析器类。
2. **实现解析逻辑**:在解析器类中实现具体的解析逻辑。
3. **注册解析器**:将自定义解析器注册到Feeds库中,使其能够被使用。
以下是一个简单的示例代码,展示了如何编写一个自定义解析器插件:
```python
from feeds import FeedParserPlugin
class MyCustomParser(FeedParserPlugin):
def feedparser(self, feed, entry):
# 这里实现自定义的解析逻辑
# 例如解析一个特殊的RSS格式
pass
# 注册自定义解析器
Feed.register_parser(MyCustomParser)
```
在这个示例中,我们定义了一个`MyCustomParser`类,它继承自`FeedParserPlugin`。我们在`feedparser`方法中实现了自定义的解析逻辑。然后我们使用`Feed.register_parser`方法将自定义解析器注册到Feeds库中。
### 5.3.2 分发自定义Feeds库包
为了方便使用和维护自定义解析器插件,我们可以将其打包并分发给其他用户。这可以通过Python的`setuptools`库来实现。
以下是一个简单的`setup.py`文件示例,展示了如何分发自定义的Feeds库包:
```python
from setuptools import setup
setup(
name='custom_feeds',
version='0.1',
description='Custom Feeds Library Plugin',
packages=['custom_feeds'],
install_requires=['feeds'],
classifiers=[
'Development Status :: 3 - Alpha',
'Intended Audience :: Developers',
'Programming Language :: Python',
'License :: OSI Approved :: MIT License',
],
)
```
在这个示例中,我们定义了一个`setup.py`文件,其中包含了包的基本信息,如名称、版本、描述、依赖等。然后我们使用`setuptools.setup`函数来设置这些信息。
### 5.3.3 第三方库的贡献和维护
在扩展Feeds库功能时,我们需要注意以下几点:
- **代码质量**:确保自定义解析器插件的代码质量,编写测试用例来验证功能。
- **文档和示例**:提供详细的文档和示例,方便其他用户理解和使用。
- **社区贡献**:考虑将自定义解析器贡献给Feeds库的官方库,使其成为社区的一部分。
通过编写自定义解析器插件和分发自定义Feeds库包,我们可以扩展Feeds库的功能,满足更广泛的应用需求。同时,我们也为Feeds库的社区贡献了自己的力量,共同推动这个库的发展。
# 6. Feeds库的未来与挑战
在本章节中,我们将深入探讨Feeds库的未来发展趋势以及当前面临的挑战,并探索可能的解决方案。随着技术的不断进步,Feeds库也必须适应新兴技术的融合,并且在社区和开源贡献方面持续发展。同时,我们还将讨论如何应对数据源多样性和复杂性带来的挑战,以及如何满足高性能数据处理的需求。
## 6.1 Feeds库的未来发展趋势
### 6.1.1 新兴技术的融合
随着技术的不断发展,Feeds库将会融合新兴技术,例如人工智能、机器学习以及大数据分析等。这些技术的融合将使得Feeds库能够提供更加智能化的数据处理和分析功能。例如,通过机器学习算法,我们可以对RSS/Atom条目进行分类和标签化,从而提高信息检索的效率和准确性。
```python
# 示例代码:使用机器学习模型对条目进行分类
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
# 假设我们有一组条目的标题和内容
entries = [
{'title': 'Python 3.8 Released', 'content': 'Python 3.8 has been released with new features like assignment expressions.'),
{'title': 'Machine Learning Tutorial', 'content': 'A comprehensive guide to machine learning with practical examples.'}
]
# 将条目转换为文本数据
texts = [entry['title'] + " " + entry['content'] for entry in entries]
# 创建一个简单的文本分类模型
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
# 训练模型
# 注意:这里使用的是示例数据,实际应用中需要更多数据来训练模型
model.fit(texts, [0, 1])
```
### 6.1.2 社区和开源贡献
Feeds库的未来将不仅仅依赖于核心开发团队的努力,还需要社区和开源贡献者的积极参与。通过社区的力量,可以加速Feeds库的功能迭代和问题修复。开源贡献者可以通过提交代码、报告bug、撰写文档或提供教程等方式为Feeds库的发展做出贡献。
## 6.2 面临的挑战与解决方案
### 6.2.1 数据源的多样性和复杂性
随着互联网内容的爆炸式增长,Feeds库面临的数据源变得越来越多样和复杂。这不仅包括各种格式的RSS/Atom源,还包括结构化和非结构化的数据。为了应对这一挑战,Feeds库需要不断增强其解析器的灵活性和鲁棒性。
```python
# 示例代码:增强解析器以处理不同格式的RSS/Atom源
from feeds import FeedParser
# 假设我们有一个复杂的RSS源
complex_rss_source = '...'
# 创建解析器实例
parser = FeedParser(complex_rss_source)
# 尝试解析RSS源
try:
feed = parser.parse()
except Exception as e:
print(f"Error parsing feed: {e}")
# 输出解析后的数据
print(feed.entries)
```
### 6.2.2 高性能数据处理的需求
在处理大量数据时,Feeds库的性能成为一个关键因素。为了满足高性能数据处理的需求,可能需要引入异步处理、缓存机制和分布式处理等技术。通过这些技术,可以显著提高Feeds库处理大规模数据的能力。
```python
# 示例代码:使用异步IO来提高性能
import asyncio
from feeds import FeedParser
async def parse_feed(url):
parser = FeedParser(url)
feed = await parser.parse_async()
return feed
# 异步解析多个RSS源
urls = ['feed1.rss', 'feed2.rss', 'feed3.rss']
feeds = await asyncio.gather(*(parse_feed(url) for url in urls))
# 输出解析后的数据
for feed in feeds:
print(feed.entries)
```
通过以上示例代码,我们可以看到Feeds库在未来的趋势和面临的挑战。新兴技术的融合和社区的开源贡献将推动Feeds库不断进步,而数据源的多样性和复杂性以及高性能数据处理的需求则是未来发展的主要挑战。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Python库文件学习之feeds专栏深入解析了feeds库的高级功能,包括RSS/Atom源解析、与网络爬虫的结合、数据库集成、异常处理、自定义解析器、性能优化、安全考量、扩展模块探索、数据分析应用、自动化测试应用、内存管理、多线程和异步处理等。通过实战指南、技巧分享和专家建议,本专栏旨在帮助读者精通feeds库,构建高效的Python爬虫,实现自动化数据抓取、数据同步、数据分析和自动化测试等任务,提升Python开发能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Catia高级曲面建模案例:曲率分析优化设计的秘诀(实用型、专业性、紧迫型)
# 摘要
本文全面介绍了Catia高级曲面建模技术,涵盖了理论基础、分析工具应用、实践案例和未来发展方向。首先,概述了Catia曲面建模的基本概念与数学
STM32固件升级:一步到位的解决方案,理论到实践指南

# 摘要
STM32固件升级是嵌入式系统维护和功能更新的重要手段。本文从基础概念开始,深入探讨固件升级的理论基础、技术要求和安全性考量,并详细介绍了实践操作中的方案选择、升级步骤及问题处理技巧。进一步地,本文探讨了提升固件升级效率的方法、工具使用以及版本管理,并通过案例研究提供了实际应用的深入分析。最后,文章展望了
ACARS追踪实战手册

# 摘要
ACARS系统作为航空电子通信的关键技术,被广泛应用于航空业进行飞行数据和信息的传递。本文首先对ACARS系统的基本概念和工作原理进行了介绍,然后深入探讨了ACARS追踪的理论基础,包括通信协议分析、数据包解码技术和频率及接收设备的配置。在实践操作部分,本文指导读者如何设立ACARS接收站,追踪信号,并进行数据分
【电机工程案例分析】:如何通过磁链计算解决实际问题

# 摘要
磁链作为电机工程中的核心概念,与电机设计、性能评估及故障诊断密切相关。本文首先介绍了磁场与磁力线的基本概念以及磁链的定义和计算公式,并阐述了磁链与电流、磁通量之间的关系。接着,文章详细分析了电机设计中磁链分析的重要性,包括电机模型的建立和磁链分布的计算分析,以及磁链在评估电机效率、转矩和热效应方面的作用。在故障诊断方面,讨论了磁链测量方法及其在诊断常见电机
轮胎充气仿真中的接触问题与ABAQUS解决方案

# 摘要
轮胎充气仿真技术是研究轮胎性能与设计的重要工具。第一章介绍了轮胎充气仿真基础与应用,强调了其在轮胎设计中的作用。第二章探讨了接触问题理论在轮胎仿真中的应用和重要性,阐述了接触问题的理论基础、轮胎充气仿真中的接触特性及挑战。第三章专注于ABAQUS软件在轮胎充气仿真中的应用,介绍了该软件的特点、在轮胎仿真中的优势及接触模拟的设置。第四章通过
PWSCF新手必备指南:10分钟内掌握安装与配置

# 摘要
PWSCF是一款广泛应用于材料科学和物理学领域的计算软件,本文首先对PWSCF进行了简介与基础介绍,然后详细解析了其安装步骤、基本配置以及运行方法。文中不仅提供了系统的安装前准备、标准安装流程和环境变量配置指南,还深入探讨了PWSCF的配置文件解析、计算任务提交和输出结果分析。此外
【NTP服务器从零到英雄】:构建CentOS 7高可用时钟同步架构
# 摘要
本论文首先介绍了NTP服务器的基础概念和CentOS 7系统的安装与配置流程,包括最小化安装步骤、网络配置以及基础服务设置。接着,详细阐述了NTP服务的部署与管理方法,以及如何通过监控与维护确保服务稳定运行。此外,论文还着重讲解了构建高可用NTP集群的技术细节,包括理论基础、配置实践以及测试与优化策略。最后,探讨了NTP服务器的高级配置选项、与其他服务的集成方法,并
【2023版】微软文件共享协议全面指南:从入门到高级技巧
# 摘要
本文全面介绍了微软文件共享协议,从基础协议知识到深入应用,再到安全管理与故障排除,最后展望了未来的技术趋势和新兴协议。文章首先概述了文件共享协议的核心概念及其配置要点,随后深入探讨了SMB协议和DFS的高级配置技巧、文件共享权限设置的最佳实践。在应用部分,本文通过案例分析展示了文件共享协议在不同行业中的实际应用
【团队协作中的SketchUp】

# 摘要
本文探讨了SketchUp软件在团队协作环境中的应用及其意义,详细介绍了基础操作及与团队协作工具的集成。通过深入分析项目管理框架和协作流程的搭建与优化,本文提供了实践案例来展现SketchUp在设计公司和大型项目中的实际应用。最后,本文对SketchUp的未来发展趋势进行了展望,讨论了团队协作的新趋势及其带来的挑战
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )