【Feeds库与网络爬虫的结合】:构建自动化数据抓取工具
发布时间: 2024-10-13 13:23:03 阅读量: 29 订阅数: 28 

Python爬虫库框架学习及Python高度匿名代理IP

# 1. 网络爬虫和Feeds库的基本概念
## 1.1 网络爬虫概述
网络爬虫(Web Crawler),又称网络蜘蛛(Spider),是一种自动化浏览互联网并收集特定信息的程序。它模仿人类的浏览行为,通过访问网页链接,提取页面内容,并进一步分析以获取数据。网络爬虫是搜索引擎、数据分析和内容聚合等领域的核心技术之一。
### 1.1.1 网络爬虫的工作原理
网络爬虫的基本工作流程包括以下几个步骤:
1. **URL管理器**:负责管理待访问的URL队列。
2. **网页下载器**:访问URL,下载网页内容。
3. **网页解析器**:分析网页内容,提取有用信息和新的URL。
4. **数据存储器**:存储提取的数据和已访问的URL。
## 1.2 Feeds库概述
Feeds库是Python中用于简化网络爬虫开发的库,提供了高效的网页下载和解析功能,支持多线程和异步处理,是网络爬虫开发者的利器。
### 1.2.1 Feeds库的基本功能
Feeds库的主要功能包括:
- **HTTP请求**:支持HTTP和HTTPS协议,可以处理重定向、Cookies和Session。
- **网页解析**:内置多种解析器,如HTMLParser、XML等。
- **数据提取**:提供XPath和CSS选择器等多种方式提取数据。
- **多线程和异步**:支持多线程和异步HTTP请求,提高爬取效率。
通过Feeds库,开发者可以更加便捷地构建网络爬虫,实现高效的数据抓取和解析。接下来的章节将详细介绍Feeds库的安装、配置、基本语法和高级特性。
# 2. Feeds库在网络爬虫中的应用
## 2.1 Feeds库的基本使用
### 2.1.1 Feeds库的安装和配置
在本章节中,我们将介绍Feeds库的基本使用,包括安装和配置。Feeds库是一个强大的Python库,用于数据抓取和处理。在开始使用之前,我们需要确保已经安装了Python环境,并且通过pip安装了Feeds库。
```bash
pip install feeds
```
安装完成后,我们可以在Python脚本中导入Feeds库,并进行基本配置。Feeds库的配置通常涉及设置用户代理(User-Agent)、代理(Proxy)等参数,以便在爬取网站时模拟浏览器行为,避免被服务器封禁。
```python
import feeds
feed配置 = {
'user_agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'proxy': '***',
}
feeds.set_config(feed配置)
```
### 2.1.2 Feeds库的基本语法和命令
Feeds库提供了丰富的API来处理和抓取数据。以下是一些基本的语法和命令,用于获取和解析RSS/Atom feeds。
#### 获取Feeds
```python
feed = feeds.parse feed_url
```
`feed_url`是我们要抓取的RSS/Atom feeds的URL地址。`parse`函数会解析该URL的内容,并返回一个Feeds对象。
#### 获取Feeds中的条目
```python
entries = feed.entries
```
`entries`是一个列表,包含了Feeds中的所有条目(entry)。每个条目代表一个独立的信息单元,如新闻、博客文章等。
#### 获取条目的标题和链接
```python
for entry in entries:
title = entry.title
link = entry.link
print(title, link)
```
通过遍历`entries`列表,我们可以访问每个条目的标题和链接,并进行进一步的处理。
#### 使用CSS选择器提取数据
```python
from cssutils import parseString
html = '<div><a class="title">Example Title</a></div>'
DOMString = parseString(html)
selector = 'div a.title'
entry = next(feed.entries)
html = entry.content['type']
DOMString = parseString(html)
entries = DOMString.cssSelectors(selector)
for entry in entries:
print(entry.text)
```
通过`cssutils`库,我们可以解析HTML内容,并使用CSS选择器来提取特定的数据。
#### 使用XPath提取数据
```python
from lxml import html
html = '<div><a href="/path/to/article">Example Title</a></div>'
DOM = html.fromstring(html)
entries = DOM.xpath('//a[@class="title"]')
for entry in entries:
print(entry.text, entry.attrib['href'])
```
通过`lxml`库,我们可以解析HTML内容,并使用XPath来提取特定的数据。
在本章节中,我们介绍了Feeds库的基本使用,包括安装和配置以及一些基本的语法和命令。通过这些基础知识,我们可以开始使用Feeds库来进行简单的数据抓取和处理。在下一节中,我们将深入探讨Feeds库在不同类型数据抓取中的应用,包括网页数据和API数据的抓取。
# 3. 网络爬虫的设计和实现
## 3.1 网络爬虫的设计原则
### 3.1.1 爬虫的架构设计
在设计一个网络爬虫时,首先要考虑的是其架构设计。一个良好的架构设计是爬虫高效、稳定运行的基础。通常,网络爬虫的架构可以分为以下几个部分:
1. **调度器(Scheduler)**:负责管理和调度所有待爬取的URL,以及跟踪待处理的URL队列。
2. **下载器(Downloader)**:负责发送HTTP请求,获取网页内容,并将数据返回给爬虫。
3. **解析器(Parser)**:分析网页内容,提取新的URL和所需的数据。
4. **数据存储(Storage)**:将提取的数据存储起来,可以是数据库、文件系统或其他存储系统。
在设计爬虫架构时,需要考虑的因素包括:
- **可扩展性**:架构是否能够支持爬虫的扩展,比如增加更多的爬取任务,或是提高爬取速度。
- **容错性**:当爬虫遇到错误或异常时,架构是否能够有效地处理,避免整个爬虫崩溃。
- **模块化**:各个组件是否独立,当需要升级或更换某个组件时,是否能够不影响其他部分。
### 3.1.2 爬虫的性能优化
性能优化是爬虫设计中不可忽视的一环,它直接关系到爬虫的效率和成本。以下是一些常见的性能优化策略:
1. **并发控制**:合理设置爬虫的并发数,避免对目标服务器造成过大压力。
2. **请求间隔**:设置合理的下载间隔,模拟正常用户的行为,减少被封禁的风险。
3. **代理IP池**:使用代理IP池可以有效避免IP被封禁,提高爬虫的稳定性和成功率。
4. **动态调度策略**:根据网页内容的更新频率动态调整爬取频率,提高效率。
## 3.2 网络爬虫的实现技术
### 3.2.1 HTTP请求和响应处理
HTTP请求和响应是网络爬虫的基础,正确处理HTTP请求和响应是实现有效爬取的关键。在Python中,可以使用`requests`库来发送HTTP请求,并处理响应。
```python
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Python库文件学习之feeds专栏深入解析了feeds库的高级功能,包括RSS/Atom源解析、与网络爬虫的结合、数据库集成、异常处理、自定义解析器、性能优化、安全考量、扩展模块探索、数据分析应用、自动化测试应用、内存管理、多线程和异步处理等。通过实战指南、技巧分享和专家建议,本专栏旨在帮助读者精通feeds库,构建高效的Python爬虫,实现自动化数据抓取、数据同步、数据分析和自动化测试等任务,提升Python开发能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
E5071C高级应用技巧大揭秘:深入探索仪器潜能(专家级操作)
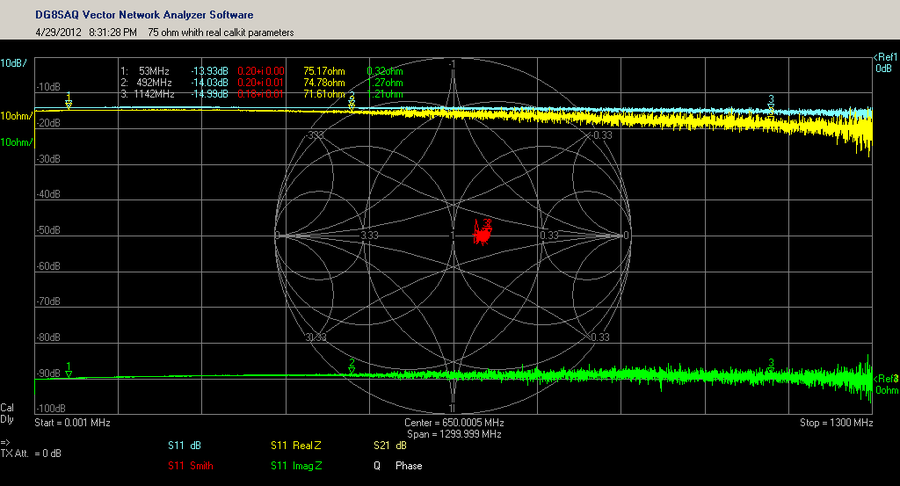
# 摘要
本文详细介绍了E5071C矢量网络分析仪的使用概要、校准和测量基础、高级测量功能、在自动化测试中的应用,以及性能优化与维护。章节内容涵盖校准流程、精确测量技巧、脉冲测量与故障诊断、自动化测试系统构建、软件集成编程接口以及仪器性能优化和日常维护。案例研究与最佳实践部分分析了E5071C在实际应用中的表现,并分享了专家级的操作技巧和应用趋势,为用户提供了一套完整的学习和操作指南。
# 关键字
【模糊控制规则的自适应调整】:方法论与故障排除

# 摘要
本文综述了模糊控制规则的基本原理,并深入探讨了自适应模糊控制的理论框架,涵盖了模糊逻辑与控制系统的关系、自适应调整的数学模型以及性能评估方法。通过分析自适应模糊控
DirectExcel开发进阶:如何开发并集成高效插件

# 摘要
DirectExcel作为一种先进的Excel操作框架,为开发者提供了高效操作Excel的解决方案。本文首先介绍DirectExcel开发的基础知识,深入探讨了DirectExcel高效插件的理论基础,包括插件的核心概念、开发环境设置和架构设计。接着,文章通过实际案例详细解析了DirectExcel插件开发实践中的功能实现、调试
【深入RCD吸收】:优化反激电源性能的电路设计技巧
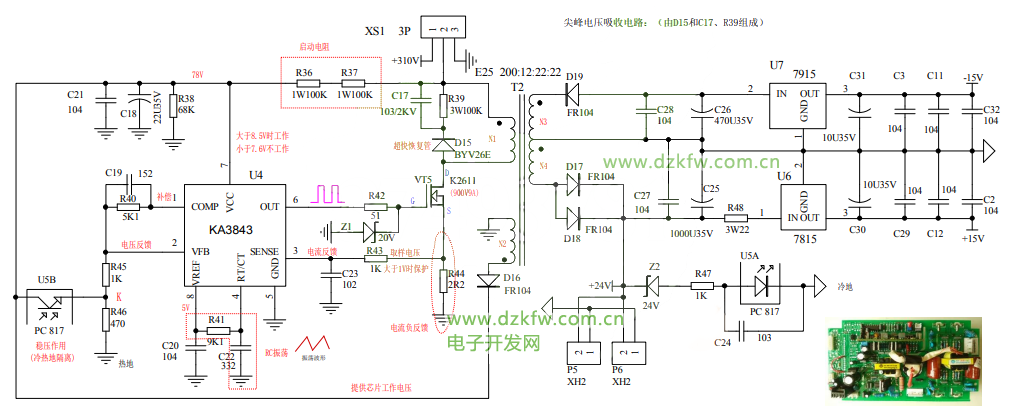
# 摘要
本文详细探讨了反激电源中RCD吸收电路的理论基础和设计方法。首先介绍了反激电源的基本原理和RCD吸收概述,随后深入分析了RCD吸收的工作模式、工作机制以及关键参数。在设计方面,本文提供了基于理论计算的设计过程和实践考量,并通过设计案例分析对性能进行测试与优化。进一步地,探讨了RCD吸收电路的性能优化策略,包括高效设计技巧、高频应用挑战和与磁性元件的协同设计。此外,本文还涉及了RCD
【进阶宝典】:宝元LNC软件高级功能深度解析与实践应用!

# 摘要
本文全面介绍了宝元LNC软件的综合特性,强调其高级功能,如用户界面的自定义与交互增强、高级数据处理能力、系统集成的灵活性和安全性以及性能优化策略。通过具体案例,分析了软件在不同行业中的应用实践和工作流程优化。同时,探讨了软件的开发环境、编程技巧以及用户体验改进,并对软件的未来发展趋势和长期战略规划进行了展望。本研究旨在为宝元LNC软件的用户和开发者提供深入的理解和指导,以支持其在不
51单片机数字时钟故障排除:系统维护与性能优化
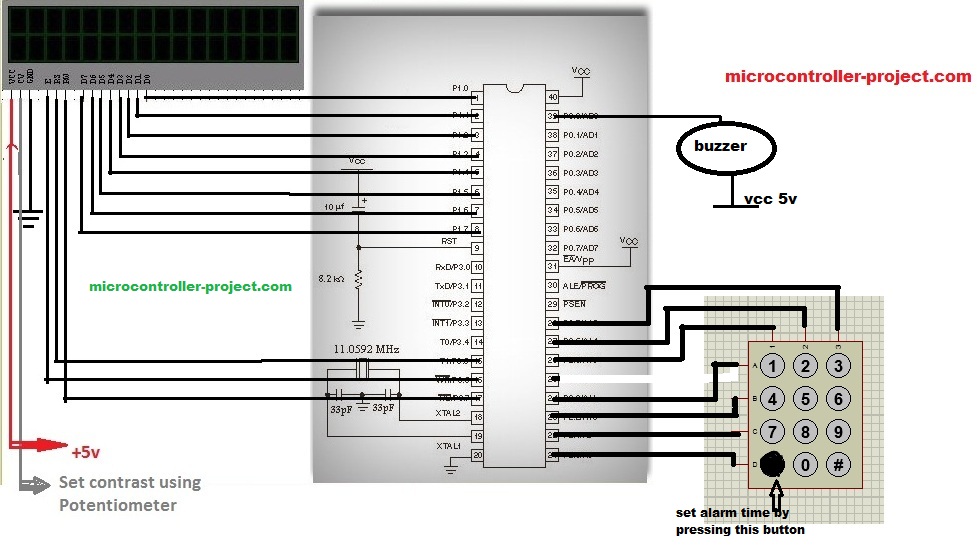
# 摘要
本文全面介绍了51单片机数字时钟系统的设计、故障诊断、维护与修复、性能优化、测试评估以及未来趋势。首先概述了数字时钟系统的工作原理和结构,然后详细分析了故障诊断的理论基础,包括常见故障类型、成因及其诊断工具和技术。接下来,文章探讨了维护和修复的实践方法,包括快速检测、故障定位、组件更换和系统重置,以及典型故障修复案例。在性能优化部分,本文提出了硬件性能提升和软
ISAPI与IIS协同工作:深入探究5大核心策略!
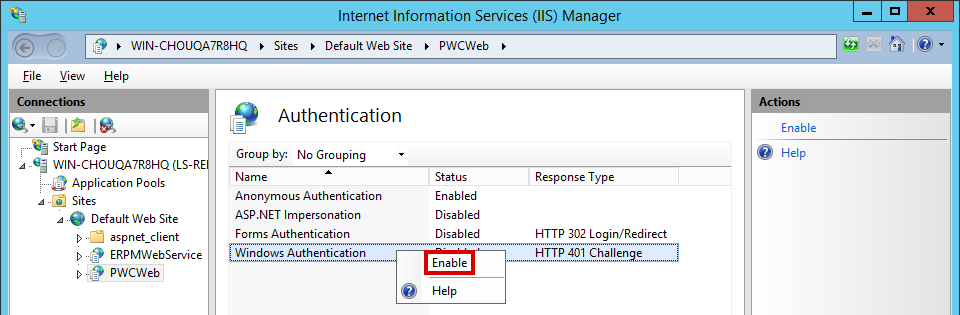
# 摘要
本文深入探讨了ISAPI与IIS协同工作的机制,详细介绍了ISAPI过滤器和扩展程序的高级策略,以及IIS应用程序池的深入管理。文章首先阐述了ISAPI过滤器的基础知识,包括其生命周期、工作原理和与IIS请求处理流程的相互作用。接着,文章探讨了ISAPI扩展程序的开发与部
【APK资源优化】:图片、音频与视频文件的优化最佳实践
# 摘要
随着移动应用的普及,APK资源优化成为提升用户体验和应用性能的关键。本文概述了APK资源优化的重要性,并深入探讨了图片、音频和视频文件的优化技术。文章分析了不同媒体格式的特点,提出了尺寸和分辨率管理的最佳实践,以及压缩和加载策略。此外,本文介绍了高效资源优
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )