【Feeds库安全性考量】:安全抓取数据的黄金法则
发布时间: 2024-10-13 13:45:38 阅读量: 19 订阅数: 23 
# 1. Feeds库概述和安全基础
## 1.1 Feeds库简介
Feeds库是一种广泛应用于数据集成和处理的工具,它提供了一套丰富的API来实现数据的发布、订阅和同步。作为一个强大的数据处理框架,Feeds库支持多种数据源和目标,包括数据库、文件系统、消息队列等,使得开发者能够在不同的系统之间轻松地传输数据。
## 1.2 Feeds库的安全挑战
随着数据的集成和流动,安全成为了Feeds库使用中的一个重要考虑因素。安全挑战主要体现在数据传输、认证机制、访问控制和加密技术等方面。例如,未经授权的访问可能会导致数据泄露,而弱认证机制则可能遭受恶意攻击。因此,了解并掌握Feeds库的安全基础对于构建一个安全可靠的数据集成环境至关重要。
```markdown
### 安全挑战总结
- **数据传输安全**:确保数据在传输过程中的安全,防止中间人攻击。
- **认证机制**:实现强大的用户认证机制,防止未授权访问。
- **访问控制**:限制对敏感数据的访问,确保只有授权用户才能操作。
- **数据加密**:使用加密技术保护数据存储和传输的安全性。
```
在接下来的章节中,我们将深入探讨Feeds库的认证机制和数据加密技术,以及如何实施有效的访问控制和安全实践。通过这些知识的学习,我们能够更好地保护我们的数据集成环境免受安全威胁。
# 2. Feeds库的认证机制
## 2.1 基本认证机制
### 2.1.1 用户名/密码认证
在本章节中,我们将深入探讨Feeds库的基本认证机制,首先是用户名/密码认证。这种认证方式是最为常见的一种,用户在注册时会设定一个用户名和密码,每次访问服务时都需要提供这些凭据。用户名/密码认证的流程相对简单,但同时也存在一些安全隐患,比如密码可能会被猜测或泄露。
```python
# 示例代码:用户名/密码认证的简单实现
import hashlib
def calculate_password_hash(password):
# 使用SHA-256算法计算密码的哈希值
return hashlib.sha256(password.encode()).hexdigest()
username = input("请输入用户名: ")
password = input("请输入密码: ")
# 假设数据库中存储的是经过哈希处理后的密码
stored_password_hash = "e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"
# 验证密码
if calculate_password_hash(password) == stored_password_hash:
print("登录成功")
else:
print("登录失败")
```
上述代码展示了如何使用Python计算密码的哈希值,并与存储的哈希值进行比对,以验证用户身份。这里使用的是SHA-256算法,它可以提供较高的安全性。
### 2.1.2 API密钥认证
API密钥认证是另一种常见的认证方式,它通常用于服务之间的通信。API密钥是一串字符,可以是简单的随机字符串,也可以是经过特殊编码或加密的字符串。使用API密钥时,服务端会验证请求中是否包含正确的密钥,以判断请求的合法性。
```python
# 示例代码:API密钥认证的简单实现
API_KEY = "***abcdef"
def validate_api_key(request):
# 从请求头中获取API密钥
api_key = request.headers.get("X-API-KEY")
# 检查API密钥是否正确
if api_key == API_KEY:
return True
else:
return False
# 假设这是一个客户端发送的请求
request = {
"headers": {
"X-API-KEY": "***abcdef"
}
}
# 验证API密钥
if validate_api_key(request):
print("API请求验证通过")
else:
print("API请求验证失败")
```
上述代码展示了如何通过HTTP请求头来验证API密钥。在这个例子中,我们假设API密钥存储在请求头的`X-API-KEY`字段中。
### 2.1.3 OAuth认证
OAuth是一种开放标准,允许用户授权第三方应用访问他们存储在其他服务提供者上的信息,而无需将用户名和密码提供给第三方应用。OAuth认证流程通常涉及四个角色:资源拥有者(用户)、资源服务器(服务提供者)、客户端(第三方应用)和认证服务器。
```mermaid
graph LR
A[资源拥有者<br>(用户)] -->|授权| B[客户端<br>(第三方应用)]
B -->|请求令牌| C[认证服务器<br>(服务提供者)]
C -->|授权令牌| B
B -->|使用令牌访问| D[资源服务器<br>(服务提供者)]
D -->|返回资源| B
```
上述mermaid图表描述了OAuth认证的基本流程。用户授权第三方应用访问他们的资源,第三方应用向认证服务器请求令牌,认证服务器返回授权令牌,最后第三方应用使用该令牌访问资源服务器并获取资源。
## 2.2 高级认证机制
### 2.2.1 双因素认证
双因素认证(2FA)是一种安全措施,要求用户在登录时不仅提供密码(知识因素),还要提供第二因素,通常是用户手机上接收到的一次性密码(拥有因素)或使用物理令牌生成的密码(生物因素)。这种认证方式比单一密码认证更加安全。
### 2.2.2 SAML认证
安全断言标记语言(SAML)是一种基于XML的开放标准,用于在网络上实现安全认证和授权。SAML允许服务提供者和身份提供者之间交换认证和授权数据,使得用户无需重新登录即可访问多个网络服务。
### 2.2.3 OpenID认证
OpenID是一种开放的认证协议,允许用户使用单一的账户登录多个网站。OpenID提供者是一个独立的第三方服务,负责管理用户的账户信息和身份验证。
通过本章节的介绍,我们可以了解到Feeds库的认证机制是多样的,从基本的用户名/密码认证到更高级的双因素认证、SAML认证和OpenID认证,每种方式都有其适用场景和安全考量。在实际应用中,可以根据服务的安全需求和用户体验选择合适的认证机制。
# 3. Feeds库的数据加密技术
## 3.1 数据传输加密
数据传输加密是保护数据在网络中传输时的安全性,防止数据被窃取或篡改的重要手段。在Feeds库的应用中,数据传输加密主要依赖于SSL/TLS协议、对称和非对称加密算法以及数据加密标准。
### 3.1.1 SSL/TLS协议
安全套接层(SSL)和传输层安全性(TLS)是两种广泛使用的加密协议,它们为互联网通信提供了安全性和数据完整性。SSL/TLS通过在客户端和服务器之间建立加密连接来保护数据。
#### SSL/TLS的工作原理
SSL/TLS协议分为握手和数据传输两个阶段。在握手阶段,客户端和服务器互相验证对方的身份,并通过非对称加密技术交换对称加密的密钥。一旦建立了连接,数据传输将使用对称加密算法,因为对称加密算法在速度上要优于非对称加密算法。
#### SSL/TLS的配置步骤
1. **安装证书**:服务器需要一个有效的SSL/TLS证书,该证书需要由受信任的证书颁发机构(CA)签发。
2. **配置服务器**:服务器配置中需要指定证书文件和密钥文件的位置,并开启SSL/TLS支持。
3. **客户端验证**:客户端需要验证服务器的SSL/TLS证书的有效性和证书链。
#### SSL/TLS的代码示例
```python
import ssl
import socket
context = ssl.create_default_context(ssl.Purpose.CLIENT_AUTH)
context.load_cert_chain(certfile='path/to/certificate.pem', keyfile='path/to/private_key.pem')
with socket.create_connection(('hostname', 443)) as sock:
with context.wrap_socket(sock, server_hostname='hostname') as ssock:
# 发送和接收加密数据
```
在本节中,我们介绍了SSL/TLS协议的基本工作原理、配置步骤和代码示例。通过SSL/TLS协议,可以确保数据在传输过程中的安全性和完整性。
### 3.1.2 对称和非对称加密
对称加密和非对称加密是两种主要的加密方法,它们在Feeds库中用于保护数据传输和存储。
#### 对称加密
对称加密使用相同的密钥进行加密和解密。这种方法的优点是速度快,适合加密大量数据。常见的对称加密算法包括AES、DES和3DES。
#### 非对称加密
非对称加密使用一对密钥:公钥和私钥。公钥用于加密数据,私钥用于解密数据。这种方法的优点是安全性高,但速度较慢。常见的非对称加密算法包括RSA、ECC和DH。
#### 对称和非对称加密的应用
在实际应用中,通常会结合使用对称和非对称加密技术。例如,使用非对称加密交换对称加密的密钥,然后使用对称加密传输数据。
#### 代码示例
```python
from Crypto.Cipher import AES, PKCS1_OAEP
from Crypto.PublicKey import RSA
from Crypto.Random import get_random_bytes
from base64 import b64encode
# 生成密钥对
key = RSA.generate(2048)
public_key = key.publickey()
# 加密数据
cipher_rsa = PKCS1_OAEP.new(p
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Python库文件学习之feeds专栏深入解析了feeds库的高级功能,包括RSS/Atom源解析、与网络爬虫的结合、数据库集成、异常处理、自定义解析器、性能优化、安全考量、扩展模块探索、数据分析应用、自动化测试应用、内存管理、多线程和异步处理等。通过实战指南、技巧分享和专家建议,本专栏旨在帮助读者精通feeds库,构建高效的Python爬虫,实现自动化数据抓取、数据同步、数据分析和自动化测试等任务,提升Python开发能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据集加载与分析】:Scikit-learn内置数据集探索指南

# 1. Scikit-learn数据集简介
数据科学的核心是数据,而高效地处理和分析数据离不开合适的工具和数据集。Scikit-learn,一个广泛应用于Python语言的开源机器学习库,不仅提供了一整套机器学习算法,还内置了多种数据集,为数据科学家进行数据探索和模型验证提供了极大的便利。本章将首先介绍Scikit-learn数据集的基础知识,包括它的起源、
【提高图表信息密度】:Seaborn自定义图例与标签技巧
# 1. Seaborn图表的简介和基础应用
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,它提供了一套高级接口,用于绘制吸引人、信息丰富的统计图形。Seaborn 的设计目的是使其易于探索和理解数据集的结构,特别是对于大型数据集。它特别擅长于展示和分析多变量数据集。
## 1.1 Seaborn
从Python脚本到交互式图表:Matplotlib的应用案例,让数据生动起来

# 1. Matplotlib的安装与基础配置
在这一章中,我们将首先讨论如何安装Matplotlib,这是一个广泛使用的Python绘图库,它是数据可视化项目中的一个核心工具。我们将介绍适用于各种操作系统的安装方法,并确保读者可以无痛地开始使用Matplotlib
概率分布计算全攻略:从离散到连续的详细数学推导

# 1. 概率分布基础概述
在统计学和概率论中,概率分布是描述随机变量取值可能性的一张蓝图。理解概率分布是进行数据分析、机器学习和风险评估等诸多领域的基本要求。本章将带您入门概率分布的基础概念。
## 1.1 随机变量及其性质
随机变量是一个可以取不同值的变量,其结果通常受概率影响。例如,掷一枚公平的六面骰子,结果就是随机变量的一个实例。随机变量通常分
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
Keras注意力机制:构建理解复杂数据的强大模型

# 1. 注意力机制在深度学习中的作用
## 1.1 理解深度学习中的注意力
深度学习通过模仿人脑的信息处理机制,已经取得了巨大的成功。然而,传统深度学习模型在处理长序列数据时常常遇到挑战,如长距离依赖问题和计算资源消耗。注意力机制的提出为解决这些问题提供了一种创新的方法。通过模仿人类的注意力集中过程,这种机制允许模型在处理信息时,更加聚焦于相关数据,从而提高学习效率和准确性。
## 1.2
【循环神经网络】:TensorFlow中RNN、LSTM和GRU的实现

# 1. 循环神经网络(RNN)基础
在当今的人工智能领域,循环神经网络(RNN)是处理序列数据的核心技术之一。与传统的全连接网络和卷积网络不同,RNN通过其独特的循环结构,能够处理并记忆序列化信息,这使得它在时间序列分析、语音识别、自然语言处理等多
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
PyTorch超参数调优:专家的5步调优指南

# 1. PyTorch超参数调优基础概念
## 1.1 什么是超参数?
在深度学习中,超参数是模型训练前需要设定的参数,它们控制学习过程并影响模型的性能。与模型参数(如权重和偏置)不同,超参数不会在训练过程中自动更新,而是需要我们根据经验或者通过调优来确定它们的最优值。
## 1.2 为什么要进行超参数调优?
超参数的选择直接影响模型的学习效率和最终的性能。在没有经过优化的默认值下训练模型可能会导致以下问题:
- **过拟合**:模型在
硬件加速在目标检测中的应用:FPGA vs. GPU的性能对比
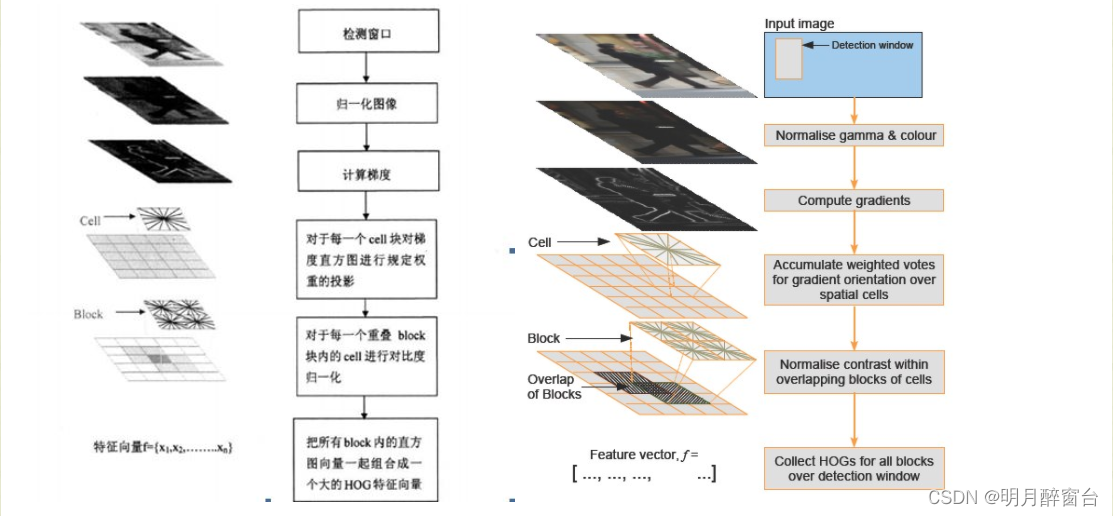
# 1. 目标检测技术与硬件加速概述
目标检测技术是计算机视觉领域的一项核心技术,它能够识别图像中的感兴趣物体,并对其进行分类与定位。这一过程通常涉及到复杂的算法和大量的计算资源,因此硬件加速成为了提升目标检测性能的关键技术手段。本章将深入探讨目标检测的基本原理,以及硬件加速,特别是FPGA和GPU在目标检测中的作用与优势。
## 1.1 目标检测技术的演进与重要性
目标检测技术的发展与深度学习的兴起紧密相关
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )