【Tidy库实战演练】:构建数据管道与机器学习数据预处理
发布时间: 2024-10-14 04:26:33 阅读量: 1 订阅数: 12 

# 1. Tidy库与数据管道的基础
在数据分析的世界中,Tidy库是一个革命性的工具,它提供了一种简洁而强大的方式来处理和分析数据。Tidy的核心理念是将数据组织成易于理解和操作的结构,即“tidy data”。本章将带你了解Tidy库的基础知识,以及如何使用数据管道来简化数据处理流程。
## 1.1 Tidy数据的五项原则
Tidy数据遵循五项基本原则,这些原则使得数据分析变得更加直观和高效:
- 每一个变量构成一列
- 每一个观测构成一行
- 每一个值都有自己的单元格
- 每一个表只包含一种类型的数据
- 每一个变量都有一个明确的名称
通过遵循这些原则,我们可以轻松地将数据加载、处理和可视化。
## 1.2 数据管道的概念
数据管道是一种处理数据的方法,它将多个数据处理步骤串联起来,形成一个处理流程。在R语言中,Tidy库提供了`%>%`管道操作符,允许我们将一个函数的输出作为下一个函数的输入。
例如,如果我们想要对一个数据框(data frame)进行一系列操作,如选择特定的列、过滤行、排序和汇总,我们可以使用管道操作符将这些步骤连接起来:
```r
library(tidyverse)
data %>%
select(column1, column2) %>%
filter(column1 > 10) %>%
arrange(desc(column2)) %>%
summarise(mean_value = mean(column2))
```
在上述代码中,`data`是我们的原始数据框,`%>%`是管道操作符,`select`、`filter`、`arrange`和`summarise`是Tidy库中的函数,用于选择列、过滤行、排序和数据汇总。
通过使用数据管道,我们不仅可以提高代码的可读性,还可以使数据处理流程更加清晰和易于维护。
# 2. Tidy库的核心功能
## 2.1 数据整理与变换
### 2.1.1 选择列与过滤行
在数据分析过程中,我们经常需要从数据集中选择特定的列,或者根据一定的条件过滤掉不需要的行。Tidy库提供了简洁的方法来完成这些任务。
选择列可以通过`select()`函数实现,它允许我们根据列名或者列的位置来选择数据。例如,如果我们想要从一个名为`df`的数据框中选择名为`col1`和`col2`的列,我们可以使用以下代码:
```R
library(tidyverse)
# 假设df是我们的数据框
df <- data.frame(col1 = 1:10, col2 = letters[1:10], col3 = runif(10))
# 选择col1和col2
selected_df <- df %>% select(col1, col2)
```
过滤行则可以通过`filter()`函数来完成,它允许我们根据逻辑表达式来选择行。以下是一个示例,展示了如何过滤掉`col1`值大于5的行:
```R
# 过滤col1大于5的行
filtered_df <- df %>% filter(col1 > 5)
```
在R语言中,`%>%`是管道操作符,它允许我们将一个函数的输出直接作为下一个函数的输入。这种语法大大简化了函数嵌套的复杂性,使代码更加清晰易读。
### 2.1.2 数据排序与分组
数据排序通常是为了让数据更容易阅读和理解。Tidy库中的`arrange()`函数可以帮助我们完成这项工作。默认情况下,`arrange()`函数将数据按照升序排列,但也可以通过设置`desc()`函数来实现降序排列。
```R
# 按照col1升序排序
sorted_df <- df %>% arrange(col1)
# 按照col1降序排序
sorted_df_desc <- df %>% arrange(desc(col1))
```
分组操作则使用`group_by()`函数,它可以帮助我们对数据进行分组,这对于分组汇总和分组计算非常有用。`summarise()`函数通常与`group_by()`一起使用,来对每个分组进行汇总计算。
```R
# 分组并计算每组的平均值
grouped_df <- df %>% group_by(col2) %>% summarise(mean_col1 = mean(col1))
```
### 2.1.3 数据汇总与合并
数据汇总是数据分析中的一个重要步骤,它涉及到将数据按照某种方式进行汇总或聚合。在Tidy库中,`summarise()`函数可以用来进行这种操作。例如,我们可以计算整个数据集的平均值、中位数或标准差。
数据合并则可以使用`bind_rows()`和`bind_cols()`函数,分别用于行合并和列合并。这些函数是tidyverse中的基础函数,能够方便地处理多个数据集。
```R
# 按照col2进行分组并计算每组的平均值
summarised_df <- df %>% group_by(col2) %>% summarise(mean_col1 = mean(col1))
# 将两个数据框按行合并
df1 <- data.frame(col1 = 1:5, col2 = letters[1:5])
df2 <- data.frame(col1 = 6:10, col2 = letters[6:10])
merged_df <- bind_rows(df1, df2)
```
通过本章节的介绍,我们可以看到Tidy库提供了强大的数据整理和变换功能,使得数据处理变得更加直观和高效。这些功能不仅减少了代码的复杂性,还提高了数据操作的可读性和可维护性。在接下来的章节中,我们将进一步探讨数据管道操作,以及如何将Tidy库与其他数据分析工具结合使用。
# 3. Tidy库与机器学习数据预处理
## 3.1 特征工程与数据转换
### 3.1.1 特征选择与提取
在机器学习中,特征工程是提高模型性能的关键步骤之一。Tidy库提供了丰富的函数来支持特征选择和提取。通过选择与模型性能密切相关的特征,可以简化模型结构,减少过拟合的风险,并提高训练速度。
#### 特征选择方法
特征选择通常分为过滤式、包裹式和嵌入式三种方法。Tidy库中的`select()`函数可以结合`nearZeroVar()`或`findCorrelation()`等函数来实现过滤式特征选择,即通过统计测试或相关性分析来过滤掉不重要的特征。
```r
# 示例代码:过滤式特征选择
library(caret)
data(iris)
# 使用nearZeroVar函数找出接近零方差的特征
zero_var_features <- nearZeroVar(iris, saveMetrics = TRUE)
# 选择非零方差的特征
selected_features <- iris[, !zero_var_features$zeroVar]
```
在这个例子中,`nearZeroVar()`函数用于找出接近零方差的特征,然后通过逻辑否定操作符`!`选择剩余的特征。
#### 特征提取技术
特征提取通常涉及降维技术,如主成分分析(PCA)或线性判别分析(LDA)。Tidy库通过`prcomp()`函数支持PCA分析,可以用来提取数据的主要成分,从而减少特征数量并降低计算复杂度。
```r
# 示例代码:主成分分析(PCA)
pca_result <- prcomp(iris[, -5], scale. = TRUE)
# 查看主成分贡献率
summary(pca_result)
```
在这里,`prcomp()`函数用于对除去标签列的iris数据集进行PCA分析,`scale. = TRUE`参数表示对数据进行标准化处理。
### 3.1.2 编码分类变量
在机器学习模型中,分类变量需要转换为数值形式。Tidy库提供了`mutate()`和`factor()`函数,可以将分类变量转换为因子类型,进而转换为数值编码。
#### 分类变量编码示例
```r
# 示例代码:分类变量编码
library(dplyr)
# 创建包含分类变量的数据框
data <- data.frame(Color = c("Red", "Green", "Blue", "Red"))
# 将分类变量转换为因子类型
data <- mutate(data, Color = factor(Color))
# 查看因子类型编码
levels(data$Color)
```
在这个例子中,`mutate()`函数与`factor()`函数结合使用,将颜色分类变量`Color`转换为因子类型,并通过`levels()`函数查看编码。
### 3.1.3 数据标准化与归一化
数据标准化和归一化是预处理步骤中常见的操作,它们可以提高算法的收敛速度和性能。Tidy库通过`mutate()`和`scale()`函数支持数据标准化。
#### 数据标准化示例
```r
# 示例代码:数据标准化
data <- data.frame(A = c(1, 2, 3, 4), B = c(5, 6, 7, 8))
# 对数据进行标准化处理
standardized_data <- mutate(data, across(everything(), scale))
```
在这个例子中,`mutate()`函数与`across()`函数结合使用,将所有列的数据进行标准化处理,`everything()`函数表示选择所有列。
## 3.2 数据集划分与交叉验证
### 3.2.1 训练集与测试集的划分
划分数据集是机器学习中的一个重要步骤,它可以帮助我们评估模型在未知数据上的性能。Tidy库提供了`createDataPartition()`函数来帮助我们进行数据集的划分。
#### 数据集划分示例
```r
# 示例代码:数据集划分
library(caret)
data(iris)
# 使用createDataPartition函数进行数据划分
set.seed(123)
train_index <- createDataPartition(iris$Species, p = 0.7, list = FALSE)
train_data <- iris[train_index, ]
test_data <- iris[-train_index, ]
```
在这里,`createDataPartition()`函数用于将iris数据集按照70%的比例划分为训练集和测试集,`list = FALSE`参数表示返回索引而非列表。
### 3.2.2 交叉验证的实现
交叉验证是一种评估模型性能的方法,它可以减少模型评估的方差。Tidy库的`train()`函数提供了交叉验证的支持。
#### 交叉验证示例
```r
# 示例代码:交叉验证
library(caret)
data(iris)
# 定义训练控制函数,使用10折交叉验证
train_control <- trainControl(
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 Tidy 专栏!
本专栏深入探讨了 Tidy 库,一个强大的 Python 数据处理工具。从入门指南到高级功能,再到与 Pandas 的对比和绘图功能,我们涵盖了 Tidy 库的方方面面。
此外,我们还提供了实用技巧和案例分析,帮助您掌握条件筛选、自定义功能、文本处理、异常值检测和复杂数据转换。通过本专栏,您将了解如何利用 Tidy 库提升 Python 数据处理效率,并打造数据可视化和数据清洗的利器。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【并发优化】:提升***ments.forms处理并发请求的高效策略
# 1. 并发处理的基本概念和挑战
并发处理是现代软件开发中的一个重要概念,它允许同时执行多个计算任务,以提高系统的响应速度和吞吐量。在多核心处理器和高并发应用场景中,理解并合理地实施并发处理变得尤为重要。然而,并发处理也带来了诸多挑战,例如数据一致性、
【Django.timesince进阶技巧】:定制时间格式,增强用户交互体验

# 1. Django.timesince简介
Django.timesince 是 Django 框架中一个非常实用的工具,它可以帮助开发者以一种友好的方式显示两个日期之间的时间差。这个功能对于构建用户界面时显示文章发表时间、更新时间等非常有用,能够提高用户体验
【Python日志管理秘籍】:Logger库文件的初步探索与最佳实践
# 1. 日志管理的重要性与Python中的作用
## 日志管理的重要性
在IT行业中,日志管理是保障系统稳定运行、快速定位问题的关键。它不仅记录了系统的行为轨迹,也是审计和合规的重要依据。有效的日志管理可以帮助我们:
- 快速定位问题:通过分析日志,可以迅速发
【py_compile与自定义编译器】:创建自定义Python编译器的步骤

# 1. py_compile模块概述
## 1.1 Python编译过程简介
Python作为一种解释型语言,其源代码在执行前需要被编译成字节码。这个编译过程是Python运行时自动完成的,但也可以通过`py_compile`模块手动触发。编译过程主要是将`.py`文件转换为`.pyc`文件,这些字节码文件可以被Python解释器更高效地加载和执行。
##
【Django GIS模块扩展】:如何开发django.contrib.gis.utils插件的6大步骤
# 1. Django GIS模块扩展概述
在这一章节中,我们将对Django GIS模块扩展进行概述,为读者提供一个全面的理解框架。首先,我们会定义什么是Dja
【Python终端内存管理】:优化内存使用提升性能
# 1. Python内存管理概述
## 简介
在Python中,内存管理是保证程序高效运行的关键环节。由于Python是一种高级编程语言,它对内存的操作对开发者来说大多是透明的。然而,了解其内存管理机制对于编写高效、稳定的程序至关重要。
## 内存管理的重要性
良好的内存管理不仅可以提升程序的运行效率,还能避免内存泄漏等问题,从而延长程序的生命周期。Python的
Python中的Win32GUI:性能优化与资源管理的策略

# 1. Win32GUI编程基础
## 介绍Win32GUI编程环境
Win32 GUI编程是Windows平台上应用程序开发的基础。在深入探讨Win32 GUI编程的高级技巧之前,我们首先需要了解其基础环境。Win32 API(Application Programming Interface)是一套提供给Windows应
Numpy.Testing异常测试:处理和测试代码中的异常情况(异常处理指南)

# 1. Numpy.Testing异常测试概述
## 异常测试在Numpy中的重要性
Numpy作为Python编程语言中最著名的数学库,其稳定性和健壮性对于科学计算至关重要。在进行数值计算和数据处理时,Numpy可能会遇到各种预期之外的情况,这些情况通常以异常的形式表现出来。Numpy.Testing是Numpy官方提供的测试框架,它不仅能够帮助开发者
网络应用性能提升秘籍:Eventlet性能优化技巧
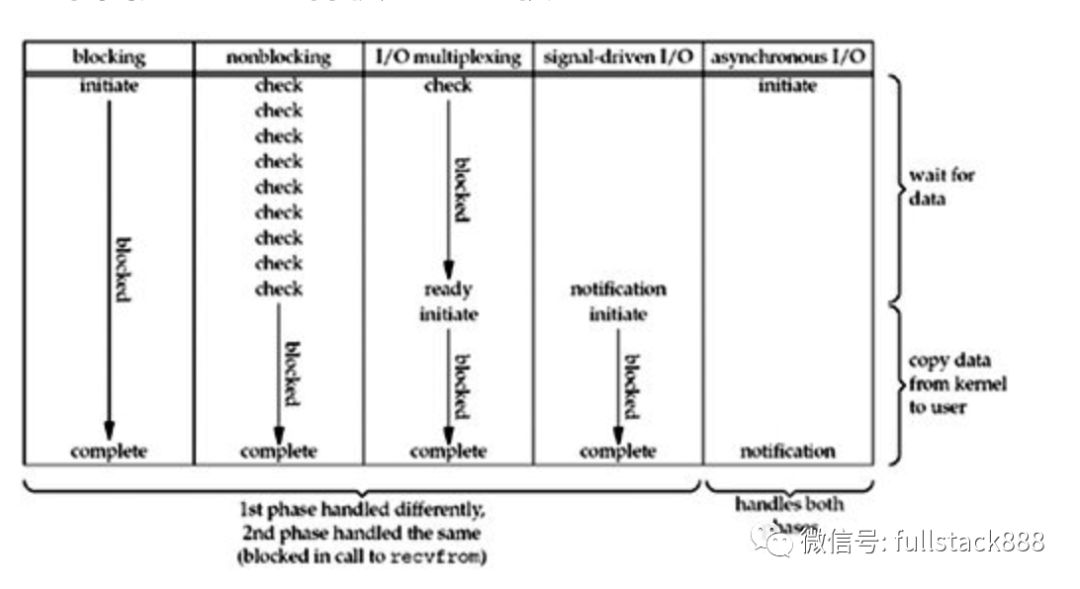
# 1. Eventlet简介与安装
## Eventlet简介
Eventlet是一个用Python编写的网络库,它提供了一种简单的方式来编写高性能的网络应用程序。Eventlet解决了传统的同步网络编程模型的局限性,允许开发者以异步方式编写代码,从而提高程序的性能和效率。
## 安装Eventlet
要开始使用Eventlet,首先需要安装它。可以通过Python的包管理工具pip来安装。在命令行
【数据库操作最佳实践】:Win32serviceutil服务程序中的数据库集成
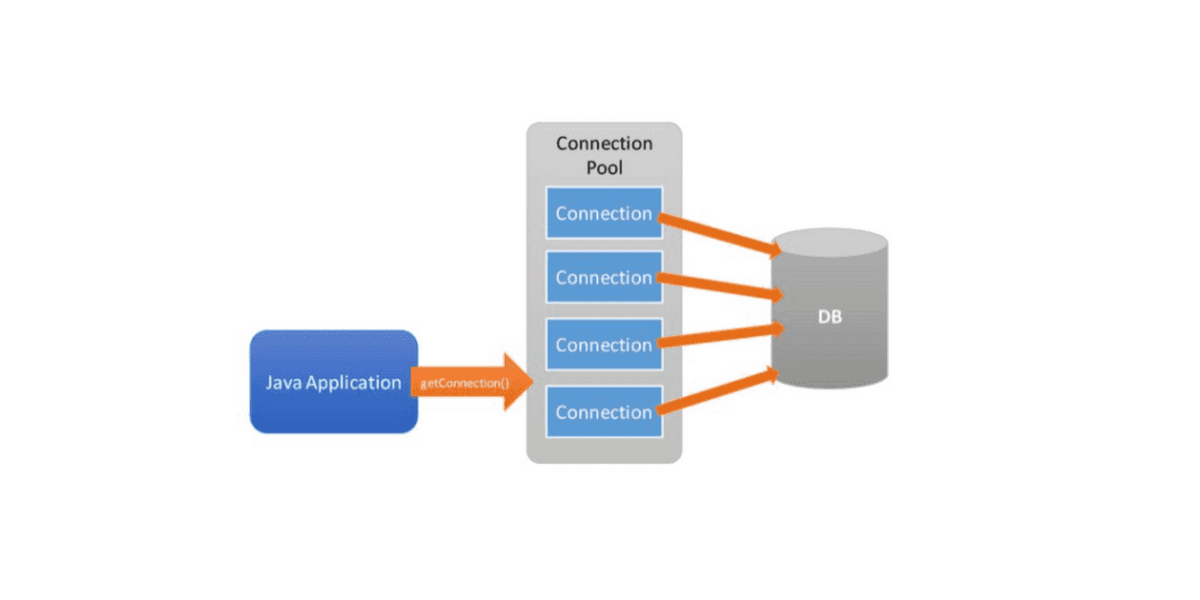
# 1. 数据库操作与Win32serviceutil服务程序概述
数据库操作是现代软件开发中不可或缺的一部分,它涉及到数据的存储、检索、更新和删除等核心功能。而在Windows环境下,Win32serviceutil服务程序提供了一种将数据库操作集成到后台服务中去的方法,使得应用程序可以更加稳定和高效地运
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )