




AUC值与成本敏感学习:平衡误分类成本的实用技巧


深入理解ROC曲线和AUC值:评估分类模型性能的利器
1. AUC值与成本敏感学习概述
在当今IT行业和数据分析中,评估模型的性能至关重要。AUC值(Area Under the Curve)是衡量分类模型预测能力的一个标准指标,特别是在不平衡数据集中。与此同时,成本敏感学习(Cost-Sensitive Learning)作为机器学习的一个分支,旨在减少模型预测中的成本偏差。本章将介绍AUC值的基本概念,解释为什么在成本敏感学习中考虑AUC值至关重要,并为读者提供相关应用的概述。
1.1 AUC值的定义与应用场景
AUC值是ROC曲线(Receiver Operating Characteristic Curve)下的面积,用来量化模型区分正负样本的能力。它提供了一个不依赖于特定阈值的性能评估方式。在诸如信用评分、欺诈检测、医疗诊断等场景中,错误分类的成本非常高,此时使用AUC值来评价模型显得尤为关键。
1.2 成本敏感学习的重要性
成本敏感学习对不同类型的错误赋予不同的权重,以此来降低总体预测成本。在业务逻辑复杂或错误分类代价不等同的领域,成本敏感学习策略能够显著提高模型的商业价值。例如,在金融领域,对假阳性(错拒)的惩罚成本往往要远高于假阴性(错批)。
本章的阐述为后续章节对AUC值的深入理解以及成本敏感学习方法的探索打下了坚实的基础。在接下来的章节中,我们将深入了解AUC值的理论与计算方法,并探索如何将成本敏感学习应用于实际问题之中。
2. AUC值的基础理论与计算方法
2.1 AUC值的定义与重要性
2.1.1 AUC值的统计意义
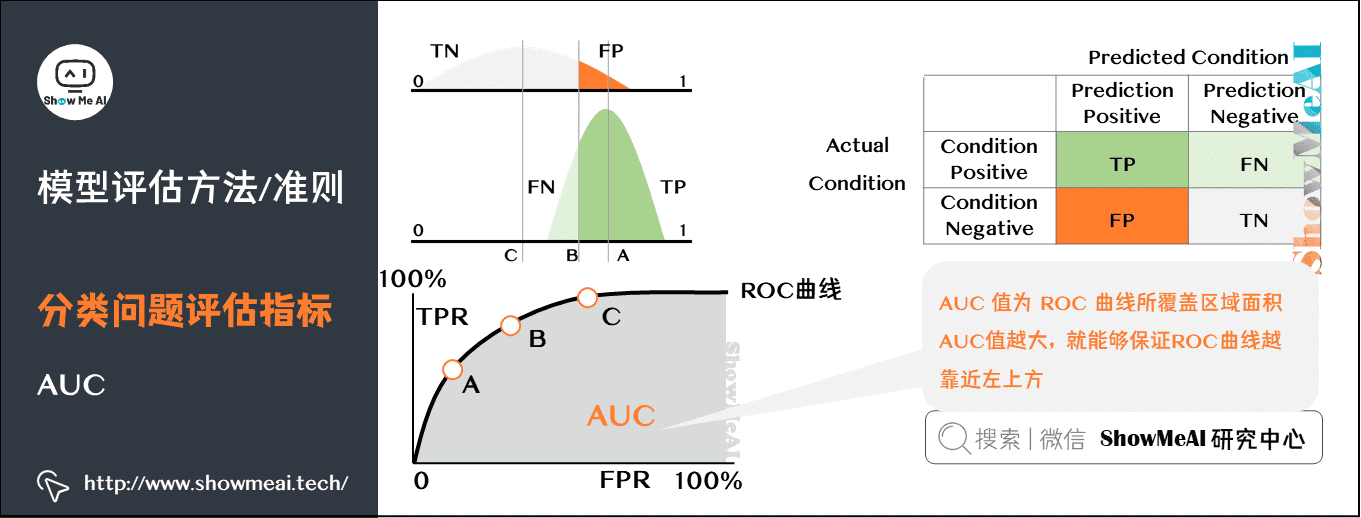
AUC值(Area Under the Curve)是评估二分类模型性能的指标,它基于ROC曲线(Receiver Operating Characteristic Curve)来衡量模型在所有可能分类阈值下的表现。AUC值的统计意义在于,它可以量化模型对正负样本分类的能力,而不受实际分类阈值选择的影响。AUC值的范围在0到1之间,值越大表示模型的预测能力越强,通常AUC值大于0.7就被认为是一个好的模型。
2.1.2 AUC与ROC曲线的关系
ROC曲线是一个重要的工具,用于可视化分类器的性能。它通过绘制真正率(True Positive Rate, TPR)和假正率(False Positive Rate, FPR)来展示模型的性能。TPR与FPR之间的平衡能够直观地展示分类器在不同阈值下的表现。AUC值是ROC曲线下的面积,它能够提供一个单一的数值来概括模型的分类性能。一般来说,AUC值越接近1,模型性能越好。
2.2 AUC值的计算实践
2.2.1 AUC值计算公式详解
AUC值的计算涉及对ROC曲线下的面积进行积分计算。在统计上,可以通过计算不同分类阈值下TPR和FPR的积分来得到AUC值。实际操作中,更常见的方法是使用非参数估计,如梯形法则,来近似计算AUC值。在一些机器学习库中,如Python的scikit-learn,提供了直接计算AUC值的函数,简化了计算过程。
2.2.2 AUC值的实际计算过程
为了计算AUC值,首先需要生成模型的预测概率,然后根据这些概率选择不同的阈值,得到不同的TPR和FPR值。通过这些值,可以绘制ROC曲线,并使用梯形法则等方法来计算曲线下的面积。在Python中,使用scikit-learn的roc_auc_score函数可以轻松获得AUC值,代码如下:
- from sklearn.metrics import roc_auc_score
- # 假定 y_true 是真实的二元标签,y_scores 是模型的预测概率
- y_true = [0, 1, 1, 0, 1]
- y_scores = [0.1, 0.4, 0.35, 0.8, 0.7]
- # 计算AUC值
- auc_value = roc_auc_score(y_true, y_scores)
- print(f'AUC Value: {auc_value}')
在这段代码中,roc_auc_score函数计算了真实的标签和预测概率之间的AUC值。在计算之前,需要保证模型输出的是概率而不是类别标签,并且标签数据和概率数据是对应的。
通过以上章节内容,我们了解了AUC值的定义、重要性和计算方法,深入到AUC值的统计意义和与ROC曲线的密切联系,并通过实际例子演示了AUC值的计算过程。这为后续探讨成本敏感学习提供了坚实的理论基础。接下来,我们将深入探讨成本敏感学习的基础理论与应用场景。
3. 成本敏感学习基础与应用场景
随着机器学习和数据科学的迅速发展,数据不平衡的问题日益成为研究的热点。成本敏感学习是处理不平衡数据的有力工具,它通过引入不等成本来提高模型对少数类的识别能力。为了深入了解成本敏感学习,我们首先需要对其概念进行解析,并探讨它在不同分类问题中的应用。
3.1 成本敏感学习概念解析
3.1.1 成本敏感学习的基本原则
成本敏感学习,顾名思义,是一种在模型训练过程中引入分类错误成本的学习方法。这种方法强调不同类型的错误会有不同的成本,并尝试最小化总成本。相比传统学习方法,它对成本较高的错误赋予更大的权重,从而提高模型在实际应用中的性能。
在成本敏感学习中,通常会有一个成本矩阵(cost matrix),该矩阵定义了每一种分类错误的代价。例如,在金融欺诈检测问题中,将一个欺诈交易误判为非欺诈可能会造成巨大的经济损失,而将非欺诈交易误判为欺诈则只涉及处理费用。成本敏感学习旨在通过调整分类边界来降低高成本错误的发生概率。
3.1.2 成本敏感学习与传统学习方法的对比
传统机器学习模型通常以整体准确度为优化目标,这在数据不平衡的情况下会导致模型偏向多数类。相比之下,成本敏感学习将分类错误的成本考虑在内,更符合现实世界问题的需求。
以支持向量机(SVM)为例,传统SVM试图最大化两类之间的边界,而在成本敏感的SVM中,我们可以为不同类型的错误分配不同的成本,从而影响决策边界的设定。通过这种方式,成本敏感学习为应对不平衡数据提供了一个强有力的工具。
3.2 成本敏感学习的分类与应用
3.2.1 二分类问题的成本敏感策略
在二分类问题中,成本敏感学习策略的一个常见方法是修改分类阈值。例如,对于一个二分类问题,如果我们将分类阈值从0.5降低到某个较低的值,模型将更倾向于将样本分类为正类(少数类),从而减少漏检的可能性。
这种方法在医学诊断、信用卡欺诈检测等领域具有广泛的应用。通过对错误分类的高成本进行加权,我们能够提高模型对少数类样本的检测能力,避免严重的后果。
3.2.2 多分类问题的成本敏感策略
多分类问题的成本敏感策略比二分类问题更为复杂。这通常涉及到构建一个多类成本矩阵,矩阵中的元素代表了各个类别间错误分类的成本。在这个框架下,我们可以使用不同的策略来处理成本,比如:
- cost-sensitive tree:构建一

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
网络性能优化指南】:10个策略提高网络系统响应速度
【霍尼韦尔PKS系统安全设置】:保障工业控制系统安全的策略
【Keil开发环境搭建】:一步到位搞定STM32G0系列开发工具链
Unity集成百度地图:10分钟打造超速入门指南
【Qt多线程编程实践】:提升万年历应用性能的关键技术
STM32F10x SWD下载模式:从零到英雄的24小时速成指南
【多系统部署技巧】:轻松打造双系统或多系统环境的曙光服务器
内存管理优化挑战全解:微型计算机技术核心攻略
【C51项目实战】:如何使用STARTUp.A51优化你的硬件环境
【KUKA机器人数据交换协议详解】:掌握数据流动的每一个细节


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















