【堆与优先队列应用课】:堆结构的算法魔术揭秘
发布时间: 2024-11-13 16:49:20 阅读量: 3 订阅数: 13 

# 1. 堆结构的理论基础
## 堆的定义和特性
堆是一种特殊的完全二叉树,通常利用数组来实现。它允许任何一个节点的值都满足“父节点的值总是大于(或小于)其子节点的值”的特性,从而保证了堆的有序性。基于这样的特性,堆可以分为最大堆和最小堆,分别用于实现优先级队列。
## 完全二叉树与二叉堆的关系
完全二叉树是一种特殊的二叉树,其特点是除了最后一层外,其他各层的节点数都是满的,而最后一层的节点都集中在左侧。二叉堆是一种基于完全二叉树的堆结构,能够用数组表示,从而实现高效的动态数据集合管理。由于这种表示方式,二叉堆支持快速的堆化操作,如上浮和下沉,这为优先级队列提供了基础。
## 堆操作的基本原理:插入和删除
堆的基本操作包括插入和删除。插入操作是将一个元素加入堆中,并通过上浮操作保持堆的有序性;而删除操作通常是移除堆顶元素,然后将堆的最后一个元素放到堆顶,通过下沉操作重新调整堆。这些操作保证了堆的结构特性,也是优先级队列实现的基础。
```python
# 假设这是最小堆的实现
class MinHeap:
def __init__(self):
self.heap = []
def parent(self, index):
return (index - 1) // 2
def insert(self, key):
self.heap.append(key)
index = len(self.heap) - 1
while index != 0 and self.heap[self.parent(index)] > self.heap[index]:
self.heap[index], self.heap[self.parent(index)] = self.heap[self.parent(index)], self.heap[index]
index = self.parent(index)
def extract_min(self):
if len(self.heap) <= 0:
return None
elif len(self.heap) == 1:
return self.heap.pop()
root = self.heap[0]
self.heap[0] = self.heap.pop()
self.heapify(0)
return root
def heapify(self, index):
smallest = index
left = 2 * index + 1
right = 2 * index + 2
if left < len(self.heap) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self.heap) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != index:
self.heap[index], self.heap[smallest] = self.heap[smallest], self.heap[index]
self.heapify(smallest)
```
在上述示例中,我们定义了一个最小堆的类`MinHeap`,其中包含了插入`insert`和删除最小值`extract_min`的基本操作。插入操作是通过上浮(`heapify`函数从下往上)实现的,而删除最小值操作则是通过下沉(`heapify`函数从上往下)来实现。这保证了我们的堆始终保持最小堆的性质。
# 2. 堆的内部实现机制
## 2.1 堆的数组表示
### 2.1.1 数组与堆节点的映射关系
堆在内存中的存储通常使用数组来完成。数组中的元素按照堆序性质排列,即任何一个父节点的值都必须大于或等于其子节点的值。这种性质使得堆的表示异常简洁,且便于通过数组索引来快速访问堆中的任意节点。
在数组中,对于任意一个位于索引`i`的节点,其子节点的索引分别为`2*i + 1`和`2*i + 2`(如果存在的话),其父节点的索引为`(i - 1) / 2`。这个映射关系是堆操作能够快速执行的根基。以下是具体映射关系的代码实现:
```python
def get_left_child(index, heap_size):
"""返回索引为index的节点的左子节点索引"""
return 2 * index + 1 if 2 * index + 1 < heap_size else None
def get_right_child(index, heap_size):
"""返回索引为index的节点的右子节点索引"""
return 2 * index + 2 if 2 * index + 2 < heap_size else None
def get_parent(index):
"""返回索引为index的节点的父节点索引"""
return (index - 1) // 2
# 示例数组表示的堆结构
heap_array = [5, 7, 9, 1, 3] # 二叉堆数组表示
```
### 2.1.2 堆序性质的数学证明
堆序性质的数学证明基于归纳法。我们可以定义一个基础情况(通常是一棵只有根节点的树),然后假设对于一个具有`k`个节点的堆,堆序性质是成立的。接着我们证明当我们在堆中添加一个新的节点并重新调整后,堆序性质依然保持。
添加新节点通常意味着在堆的底部添加一个元素,然后执行上浮(或称作提升)操作,通过交换节点,直到新节点满足堆序性质。这个过程确保了新节点会与较小的父节点交换,保证了每个父节点的值都不小于其子节点的值。
### 2.2 堆的调整过程
#### 2.2.1 上浮与下沉操作原理
上浮(或提升)操作是将一个新插入的节点与它的父节点比较,如果节点的值大于父节点的值,则交换它们的位置。这个过程一直重复,直到节点的值不再大于父节点的值为止。上浮操作保证了堆序性质中父节点总是大于其子节点的要求。
下沉(或下沉)操作则是执行相反的操作。当我们从堆中移除最大的元素(即堆顶元素)后,我们用堆的最后一个元素填充这个空位,然后执行下沉操作,将这个新的堆顶元素与它的子节点比较,并与较大的子节点交换位置。这个过程会一直进行,直到新的堆顶元素大于或等于其子节点为止。下沉操作确保了移除最大元素后,剩余部分依然保持堆序性质。
```python
def sift_up(index, heap):
"""上浮操作""
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“数据结构知识点串讲”专栏系统性地讲解了数据结构的各个核心概念和技术,涵盖了从基础到高级的广泛内容。专栏以一系列深入的文章为基础,深入探讨了线性表、栈、队列、树结构、图论、散列表、动态规划、二叉搜索树、堆、红黑树、空间优化、时间复杂度分析、递归算法、排序算法、链表高级操作、动态数组、哈希表冲突解决、跳表、并查集和布隆过滤器等关键主题。通过这些文章,读者可以全面了解数据结构的原理、应用和最佳实践,从而提升他们在算法和数据处理方面的技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据分片技术】:实现在线音乐系统数据库的负载均衡
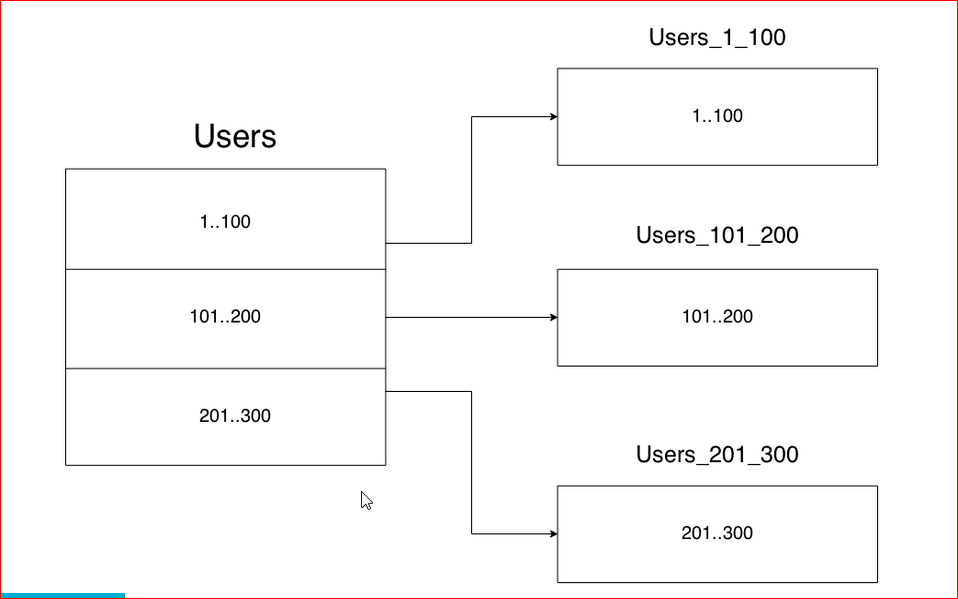
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
【多线程编程】:指针使用指南,确保线程安全与效率
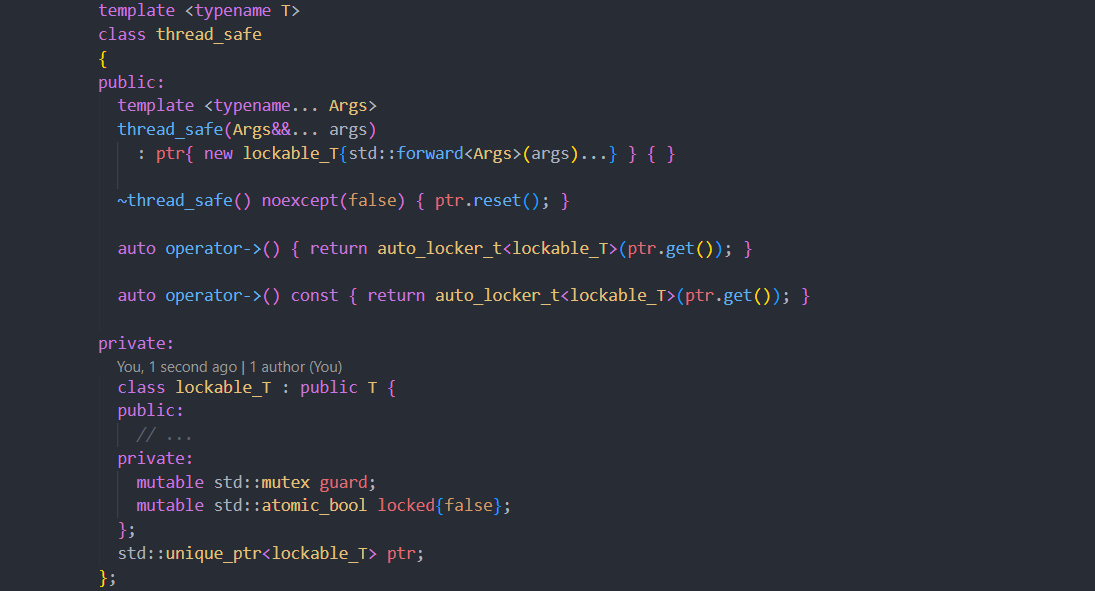
# 1. 多线程编程基础
## 1.1 多线程编程的必要性
在现代软件开发中,为了提升程序性能和响应速度,越来越多的应用需要同时处理多个任务。多线程编程便是实现这一目标的重要技术之一。通过合理地将程序分解为多个独立运行的线程,可以让CPU资源得到有效利用,并提高程序的并发处理能力。
## 1.2 多线程与操作系统
多线程是在操作系统层面上实现的,操作系统通过线程调度算法来分配CPU时
微信小程序后端交互原理详解:Python实现细节
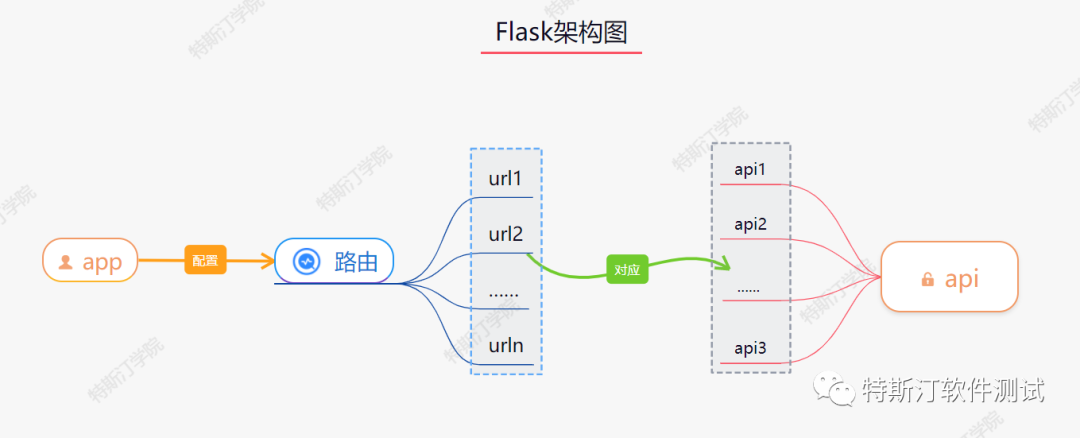
# 1. 微信小程序后端交互基础
微信小程序作为一种轻量级的应用程序,以其无需下载安装即可使用的优势,迅速占领了移动应用市场的一席之地。其后端交互能力的强大与否,直接关系到小程序的性能和用户体验。本章将引领读者进入微信小程序与服务器后端之间交互的世界,为接下来深入探讨Python后端开发和API接口设计打下基础。
首先,了解微信小程序后端交互的基本概念至关重要。微信小程序支持的后端
Java中间件服务治理实践:Dubbo在大规模服务治理中的应用与技巧
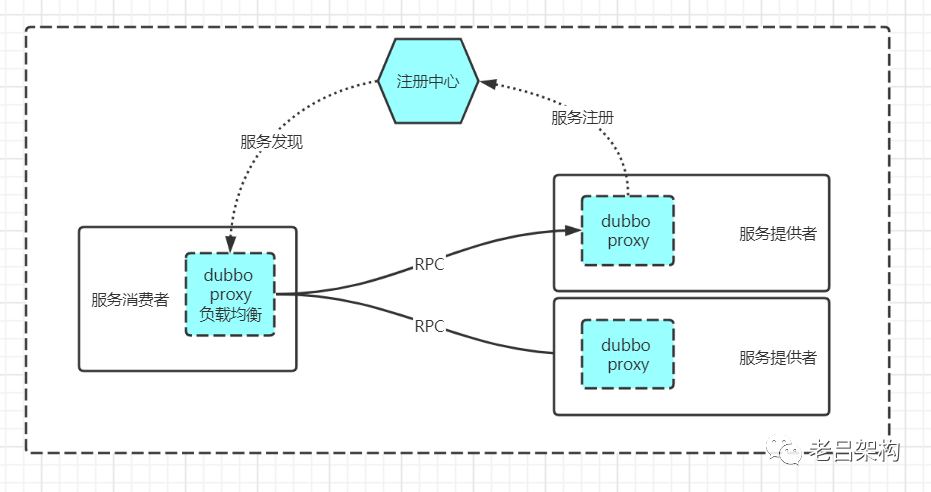
# 1. Dubbo框架概述及服务治理基础
## Dubbo框架的前世今生
Apache Dubbo 是一个高性能的Java RPC框架,起源于阿里巴巴的内部项目Dubbo。在2011年被捐赠给Apache,随后成为了Apache的顶级项目。它的设计目标是高性能、轻量级、基于Java语言开发的SOA服务框架,使得应用可以在不同服务间实现远程方法调用。随着微服务架构
Rhapsody 7.0消息队列管理:确保消息传递的高可靠性

# 1. Rhapsody 7.0消息队列的基本概念
消息队列是应用程序之间异步通信的一种机制,它允许多个进程或系统通过预先定义的消息格式,将数据或者任务加入队列,供其他进程按顺序处理。Rhapsody 7.0作为一个企业级的消息队列解决方案,提供了可靠的消息传递、消息持久化和容错能力。开发者和系统管理员依赖于Rhapsody 7.0的消息队
【MySQL大数据集成:融入大数据生态】
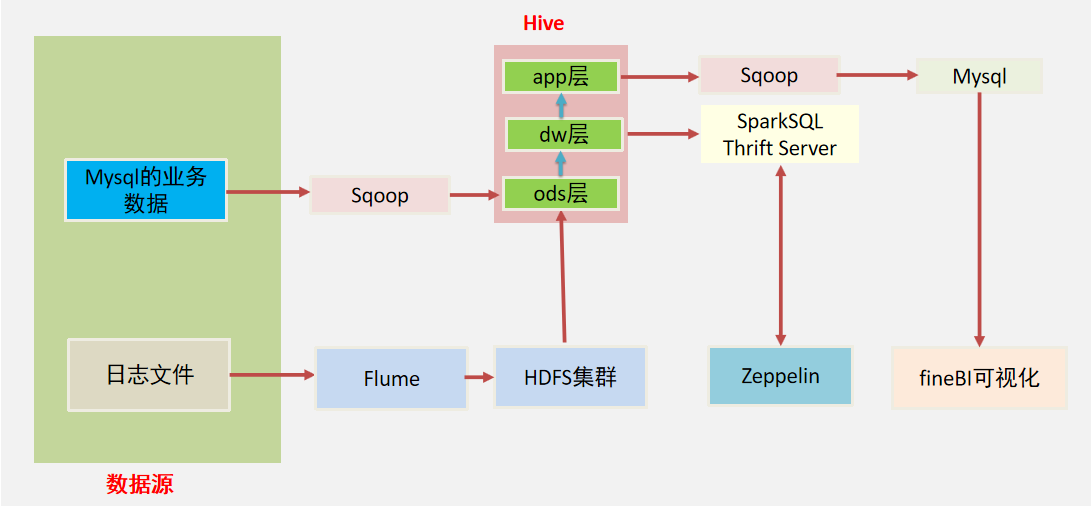
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
移动优先与响应式设计:中南大学课程设计的新时代趋势

# 1. 移动优先与响应式设计的兴起
随着智能手机和平板电脑的普及,移动互联网已成为人们获取信息和沟通的主要方式。移动优先(Mobile First)与响应式设计(Responsive Design)的概念应运而生,迅速成为了现代Web设计的标准。移动优先强调优先考虑移动用户的体验和需求,而响应式设计则注重网站在不同屏幕尺寸和设
Java药店系统国际化与本地化:多语言支持的实现与优化
# 1. Java药店系统国际化与本地化的概念
## 1.1 概述
在开发面向全球市场的Java药店系统时,国际化(Internationalization,简称i18n)与本地化(Localization,简称l10n)是关键的技术挑战之一。国际化允许应用程序支持多种语言和区域设置,而本地化则是将应用程序具体适配到特定文化或地区的过程。理解这两个概念的区别和联系,对于创建一个既能满足
大数据量下的性能提升:掌握GROUP BY的有效使用技巧
# 1. GROUP BY的SQL基础和原理
## 1.1 SQL中GROUP BY的基本概念
SQL中的`GROUP BY`子句是用于结合聚合函数,按照一个或多个列对结果集进行分组的语句。基本形式是将一列或多列的值进行分组,使得在`SELECT`列表中的聚合函数能在每个组上分别计算。例如,计算每个部门的平均薪水时,`GROUP BY`可以将员工按部门进行分组。
## 1.2 GROUP BY的工作原理
mysql-connector-net-6.6.0云原生数据库集成实践:云服务中的高效部署

# 1. mysql-connector-net-6.6.0概述
## 简介
mysql-connector-net-6.6.0是MySQL官方发布的一个.NET连接器,它提供了一个完整的用于.NET应用程序连接到MySQL数据库的API。随着云
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )