联邦学习赋能医疗数据隐私保护:FedAvg算法实践指南
发布时间: 2024-08-20 01:21:11 阅读量: 17 订阅数: 13 

# 1. 联邦学习概述与隐私保护
联邦学习是一种分布式机器学习技术,允许多个参与者在不共享原始数据的情况下协作训练机器学习模型。它通过保护数据隐私,同时利用来自不同来源的大量数据来提高模型性能。
联邦学习的基本原理是:
- **数据分散:** 参与者(例如设备、机构或组织)拥有自己的本地数据集,这些数据集不共享。
- **模型共享:** 参与者训练自己的本地模型,然后将更新的模型参数共享给中央服务器。
- **模型聚合:** 中央服务器聚合来自所有参与者的模型更新,创建全局模型。
- **模型更新:** 参与者使用全局模型更新自己的本地模型,并继续训练。
联邦学习通过保护数据隐私解决了传统机器学习中的数据共享问题。它通过保持数据在本地,同时允许协作训练来实现这一点。
# 2. FedAvg算法原理与实践
### 2.1 FedAvg算法的理论基础
#### 2.1.1 联邦学习的基本概念
联邦学习是一种分布式机器学习范式,它允许在不共享原始数据的情况下,在多台设备或服务器上协作训练模型。在联邦学习中,每个设备或服务器都拥有本地数据集,并且只与其他设备或服务器共享模型参数或梯度更新。
#### 2.1.2 FedAvg算法的数学推导
FedAvg算法是一种联邦学习算法,它通过以下步骤迭代地更新全局模型:
1. **客户端模型训练:**每个客户端使用其本地数据集训练一个本地模型。
2. **服务器模型聚合:**服务器收集所有客户端的本地模型参数,并计算它们的加权平均值。
3. **模型更新:**服务器将聚合后的模型参数发送回客户端,客户端使用这些参数更新其本地模型。
FedAvg算法的数学推导如下:
设:
* $K$:客户端数量
* $w_k$:客户端 $k$ 的本地模型参数
* $W$:全局模型参数
* $\alpha_k$:客户端 $k$ 的权重
则全局模型参数更新公式为:
```
W = \frac{1}{K} \sum_{k=1}^K \alpha_k w_k
```
### 2.2 FedAvg算法的实现步骤
#### 2.2.1 客户端模型训练
每个客户端使用其本地数据集训练一个本地模型。训练过程与传统机器学习中的模型训练类似,包括数据预处理、模型定义、模型训练和模型评估。
#### 2.2.2 服务器模型聚合
服务器收集所有客户端的本地模型参数。为了防止模型参数过大,可以使用模型压缩技术(如量化或蒸馏)来减少模型参数的大小。
#### 2.2.3 模型更新
服务器将聚合后的模型参数发送回客户端。客户端使用这些参数更新其本地模型。更新过程包括:
1. 将聚合后的模型参数加载到本地模型中。
2. 使用本地数据集微调本地模型。
3. 重复客户端模型训练过程。
# 3. FedAvg算法在医疗数据中的应用
### 3.1 医疗数据隐私保护的挑战
医疗数据包含大量个人健康信息,其隐私保护至关重要。然而,传统的集中式数据共享方式存在以下挑战:
- **医疗数据的敏感性:**医疗数据涉及疾病诊断、治疗方案、基因信息等高度敏感信息,一旦泄露可能造成严重后果。
- **数据共享的障碍:**医疗机构出于竞争、监管和法律限制等原因,往往不愿意共享数据。这阻碍了医疗数据的整合和分析,限制了医疗研究和创新。
### 3.2 FedAvg算法在医疗数据中的优势
FedAvg算法通过分布式训练和隐私保护机制,解决了医疗数据隐私保护的挑战,并带来了以下优势:
- **保护数据隐私:**FedAvg算法在客户端设备上训练模型,数据无需上传到中央服务器,有效保护了数据隐私。
- **提高模型性能:**FedAvg算法通过聚合来自不同客户端的局部模型,可以获得比单一客户端训练更好的模型性能。
#### 3.2.1 具体应用场景
FedAvg算法在医疗数据中的应用场景包括:
- **疾病诊断:**通过联邦学习训练疾病诊断模型,可以利用来自不同医院和诊所的患者数据,提高诊断准确率。
- **药物研发:**通过联邦学习训练药物研发模型,可以利用来自不同制药公司的患者数据,加速药物开发和临床试验。
- **个性化医疗:**通过联邦学习训练个性化医疗模型,可以利用来自不同患者的健康数据,为患者提供定制化的治疗方案。
#### 3.2.2 代码示例
以下代码示例展示了FedAvg算法在医疗数据中的应用:
```python
import tensorflow as tf
# 定义客户端模型
class ClientModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense1 = tf.keras.layers.Dense(128, activation='relu')
self.dense2 = tf.keras.layers.Dense(1, activation='sigmoid')
# 定义服务器模型
class ServerModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense1 = tf.keras.layers.Dense(128, activation='relu')
self.dense2 = tf.keras.layers.Dense(1, activation='sigmoid')
# 定义联邦学习过程
def fedavg(clients, server, num_rounds):
for round in range(num_rounds):
# 客户端训练
for client in clients:
client.model.fit(client.data, client.labels, epochs=1)
# 上传局部模型更新
client.upload_model_update(server)
# 服务器聚合模型
server.aggregate_model_updates(clients)
# 更新服务器模型
server.update_model()
# 训练模型
clients = [ClientModel() for _ in range(10)]
server = ServerModel()
fedavg(clients, server, 10)
```
#### 3.2.3 代码逻辑分析
- **客户端训练:**每个客户端在自己的设备上训练局部模型,并上传模型更新到服务器。
- **服务器聚合:**服务器聚合来自所有客户端的模型更新,得到全局模型更新。
- **服务器更新:**服务器使用全局模型更新更新自己的模型。
- **模型评估:**训练完成后,服务器模型可以在新的医疗数据上进行评估,以验证其性能。
# 4. FedAvg算法的性能优化
### 4.1 通信效率优化
#### 4.1.1 模型压缩技术
**原理:**
模型压缩技术通过降低模型大小来减少通信开销。常见的方法包括:
* **量化:**将浮点权重和激活值转换为低精度格式,如int8或int16。
* **剪枝:**移除模型中不重要的权重和节点。
* **蒸馏:**使用较小的学生模型从较大的教师模型中学习知识。
**代码示例:**
```python
import tensorflow as tf
# 量化模型
quantized_model = tf.quantization.quantize_model(model)
# 剪枝模型
pruned_model = tf.keras.models.prune_low_magnitude(model)
# 蒸馏模型
student_model = tf.keras.models.Sequential()
student_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
student_model.fit(X_train, y_train, epochs=10)
```
**逻辑分析:**
* `quantize_model()`函数将模型转换为量化模型。
* `prune_low_magnitude()`函数将权重幅度较低的节点剪枝。
* `fit()`函数使用教师模型训练学生模型。
#### 4.1.2 差异化更新策略
**原理:**
差异化更新策略仅更新模型中与客户端本地数据相关的部分,而不是整个模型。这可以显著减少通信量。
**代码示例:**
```python
import tensorflow as tf
# 差异化更新策略
differential_update_strategy = tf.distribute.experimental.ParameterServerStrategy()
# 创建分布式数据集
dataset = tf.data.Dataset.from_tensor_slices(data).batch(batch_size)
dataset = differential_update_strategy.experimental_distribute_dataset(dataset)
# 创建分布式模型
model = tf.keras.models.Sequential()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(dataset, epochs=10)
```
**逻辑分析:**
* `ParameterServerStrategy()`创建差异化更新策略。
* `experimental_distribute_dataset()`将数据集转换为分布式数据集。
* `fit()`函数使用差异化更新策略训练模型。
### 4.2 模型训练优化
#### 4.2.1 局部模型训练的并行化
**原理:**
通过并行化客户端上的模型训练,可以缩短训练时间。
**代码示例:**
```python
import tensorflow as tf
# 并行化模型训练
parallel_model = tf.data.experimental.map_and_batch(
lambda x, y: (tf.nn.softmax(x), y),
(X_train, y_train),
batch_size=batch_size,
num_parallel_calls=tf.data.experimental.AUTOTUNE
)
# 创建分布式模型
model = tf.keras.models.Sequential()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(parallel_model, epochs=10)
```
**逻辑分析:**
* `map_and_batch()`函数并行化模型训练。
* `AUTOTUNE`参数自动调整并行调用次数以优化性能。
* `fit()`函数使用并行模型训练训练模型。
#### 4.2.2 自适应学习率调整
**原理:**
自适应学习率调整算法根据训练进度动态调整学习率,以提高训练效率。
**代码示例:**
```python
import tensorflow as tf
# 自适应学习率调整算法
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
optimizer = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=0.001,
decay_steps=1000,
decay_rate=0.96
)
# 创建分布式模型
model = tf.keras.models.Sequential()
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10)
```
**逻辑分析:**
* `ExponentialDecay`类创建自适应学习率调整算法。
* `initial_learning_rate`参数设置初始学习率。
* `decay_steps`参数设置学习率衰减的步数。
* `decay_rate`参数设置学习率衰减率。
* `fit()`函数使用自适应学习率调整算法训练模型。
# 5. FedAvg算法的安全性考虑
### 5.1 数据泄露风险
#### 5.1.1 模型反向工程
模型反向工程是指通过分析模型的输出或内部结构来推断出模型的训练数据。在联邦学习中,客户端模型包含了本地数据的特征和隐私信息。如果攻击者能够反向工程出客户端模型,则可能泄露敏感的个人信息。
**缓解措施:**
* **差分隐私:**在训练客户端模型时加入差分隐私技术,通过添加随机噪声来降低模型对单个数据点的敏感性。
* **同态加密:**使用同态加密技术对客户端模型进行加密,使攻击者无法直接访问模型参数。
#### 5.1.2 梯度泄露
在FedAvg算法中,客户端将训练后的模型梯度上传到服务器。这些梯度包含了本地数据的隐私信息。如果攻击者能够截获这些梯度,则可能通过梯度下降攻击来推断出客户端模型和本地数据。
**缓解措施:**
* **梯度裁剪:**对客户端上传的梯度进行裁剪,限制其大小,防止攻击者通过梯度反向传播推断出模型参数。
* **加密梯度传输:**使用加密技术对梯度进行加密,防止攻击者在传输过程中截获梯度。
### 5.2 算法鲁棒性
#### 5.2.1 对抗样本攻击
对抗样本是指精心构造的输入数据,能够欺骗机器学习模型做出错误的预测。在联邦学习中,攻击者可能通过向客户端注入对抗样本,破坏客户端模型的训练,从而影响全局模型的性能。
**缓解措施:**
* **对抗样本检测:**使用对抗样本检测算法识别并过滤掉对抗样本,防止其影响模型训练。
* **对抗训练:**在训练客户端模型时加入对抗样本,增强模型对对抗样本的鲁棒性。
#### 5.2.2 模型中毒攻击
模型中毒攻击是指攻击者通过向训练数据中注入恶意数据,使模型做出有利于攻击者的预测。在联邦学习中,攻击者可能通过控制部分客户端设备,向其注入恶意数据,从而影响全局模型的性能。
**缓解措施:**
* **数据验证:**在客户端上传数据之前进行数据验证,过滤掉异常或恶意数据。
* **异常检测:**使用异常检测算法识别并剔除训练数据中的异常点,防止模型中毒攻击。
# 6. FedAvg算法的未来发展与展望
### 6.1 联邦学习的趋势和挑战
随着联邦学习的不断发展,一些新的趋势和挑战也随之而来:
- **跨域联邦学习:**不同领域或行业的组织之间的数据往往存在差异,跨域联邦学习旨在解决不同数据域之间的数据异质性问题。
- **异构数据联邦学习:**参与联邦学习的设备或组织可能拥有不同类型或格式的数据,异构数据联邦学习需要解决数据异构性问题。
### 6.2 FedAvg算法的改进方向
为了应对联邦学习的新趋势和挑战,FedAvg算法也在不断改进和优化:
- **隐私增强技术:**进一步增强算法的隐私保护能力,防止数据泄露和梯度泄露等风险。
- **模型泛化能力提升:**提高算法对不同数据分布和任务的泛化能力,提升模型的鲁棒性和准确性。
此外,联邦学习领域还有以下一些值得关注的发展方向:
- **联邦学习平台:**提供一站式联邦学习平台,简化算法开发和部署过程。
- **联邦学习标准化:**制定联邦学习的标准化协议和规范,促进算法的互操作性和可移植性。
- **联邦学习应用:**探索联邦学习在更多领域的应用,例如金融、供应链管理和物联网。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏聚焦于联邦学习,一种在保护数据隐私的同时进行机器学习的方法。它深入探讨了 FedAvg 算法,这是联邦学习中的关键算法,并提供了其实践指南。此外,专栏还分析了 FedAvg 的局限性并提出了改进策略。它还讨论了隐私保护学习的挑战和机遇,以及联邦学习中数据异构性的问题和解决方案。该专栏还提供了有关联邦学习在医疗保健中应用的案例研究,以及数据安全和隐私保护的权威指南。通过深入分析和实用建议,本专栏为读者提供了联邦学习和隐私保护学习的全面理解。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Installation and Usage of Notepad++ on Different Operating Systems: Cross-Platform Use to Meet Diverse Needs
# 1. Introduction to Notepad++
Notepad++ is a free and open-source text editor that is beloved by programmers and text processors alike. It is renowned for its lightweight design, powerful functionality, and excellent cross-platform compatibility.
Notepad++ supports syntax highlighting and auto-co
The Application and Challenges of SPI Protocol in the Internet of Things
# Application and Challenges of SPI Protocol in the Internet of Things
The Internet of Things (IoT), as a product of the deep integration of information technology and the physical world, is gradually transforming our lifestyle and work patterns. In IoT systems, each physical device can achieve int
【Practical Exercise】Simulink Simulation Implementation of Incremental PID
# 2.1 Introduction to the Simulink Simulation Environment
Simulink is a graphical environment for modeling, simulating, and analyzing dynamic systems within MATLAB. It offers an intuitive user interface that allows users to create system models using blocks and connecting lines. Simulink models con
Advanced Network Configuration and Port Forwarding Techniques in MobaXterm
# 1. Introduction to MobaXterm
MobaXterm is a powerful remote connection tool that integrates terminal, X11 server, network utilities, and file transfer tools, making remote work more efficient and convenient.
### 1.1 What is MobaXterm?
MobaXterm is a full-featured terminal software designed spec
The Status and Role of Tsinghua Mirror Source Address in the Development of Container Technology
# Introduction
The rapid advancement of container technology is transforming the ways software is developed and deployed, making applications more portable, deployable, and scalable. Amidst this technological wave, the image source plays an indispensable role in containers. This chapter will first
【持久化与不变性】:JavaScript中数据结构的原则与实践

# 1. JavaScript中的数据结构原理
## 数据结构与算法的连接点
在编程领域,数据结构是组织和存储数据的一种方式,使得我们可以高效地进行数据访问和修改。JavaScript作为一种动态类型语言,具有灵活的数据结构处理能力,这使得它在处理复杂的前端逻辑时表现出色。
数据结构与算法紧密相关,算法的效率往往依赖于数据结构的选择。例如,数组提供对元素的快速访问,而链表则在元素的插入和删除操作上更为高效。
Clock Management in Verilog and Precise Synchronization with 1PPS Signal
# 1. Introduction to Verilog
Verilog is a hardware description language (HDL) used for modeling, simulating, and synthesizing digital circuits. It provides a convenient way to describe the structure and behavior of digital circuits and is widely used in the design and verification of digital system
【环形链表的基础】:理解JavaScript中的环形数据结构
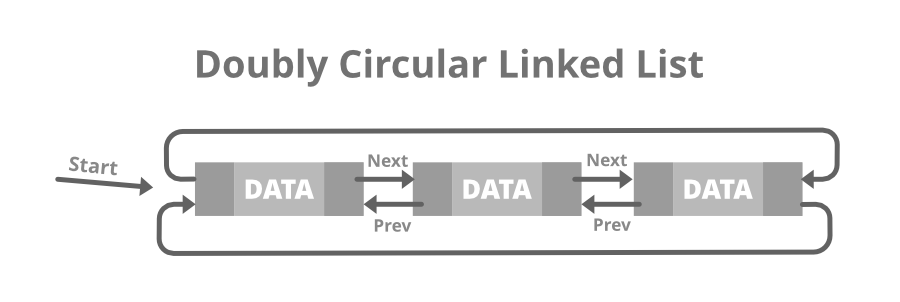
# 1. 环形链表的概念与特性
## 简介
环形链表是一种链表结构,其中每个节点指向下一个节点,且最后一个节点的指针又回到第一个节点,形成一个环。这种数据结构在计算机科学中常用于模拟循环队列、内存管理和其他需要周期性处理的任务。
## 特性
环形链表与传统的单链表或双向链表相比,具有独特的属性。其头部和尾部并不像线性链表
【JS树结构转换新手入门指南】:快速掌握学习曲线与基础
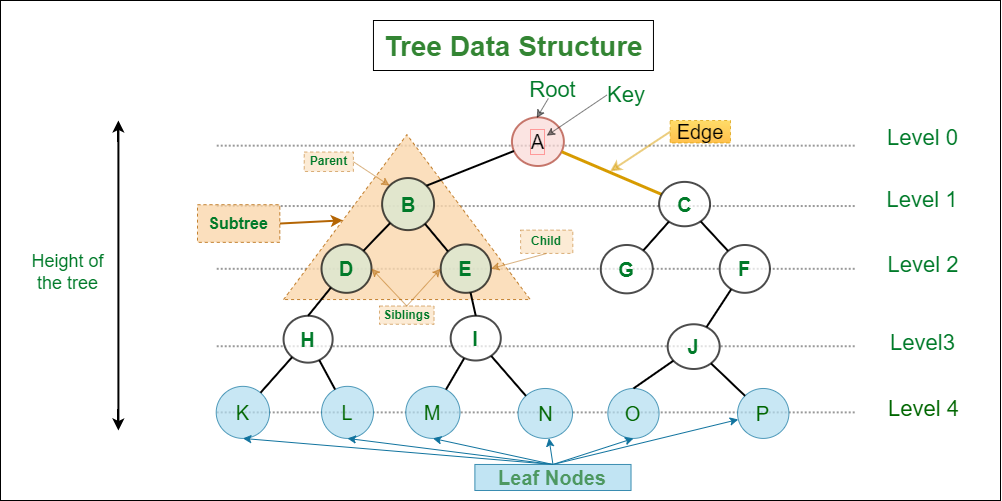
# 1. JS树结构转换基础知识
## 1.1 树结构转换的含义
在JavaScript中,树结构转换主要涉及对树型数据结构进行处理,将其从一种形式转换为另一种形式,以满足不同的应用场景需求。转换过程中可能涉及到节点的添加、删除、移动等操作,其目的是为了优化数据的存储、检索、处理速度,或是为了适应新的数据模型。
## 1.2 树结构转换的必要性
树结构转
【Basic】Signal Encoding and Decoding in MATLAB: Implementing PCM, DPCM, and ADPCM Coding
# 1. An Overview of Signal Encoding and Decoding
Signal encoding and decoding are fundamental techniques in digital signal processing, used to convert analog signals into digital signals for easier storage, transmission, and processing. The encoding process involves discretizing continuous analog s
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )