【NLTK库基础】:开启自然语言处理之旅
发布时间: 2024-10-04 17:35:47 阅读量: 32 订阅数: 42 
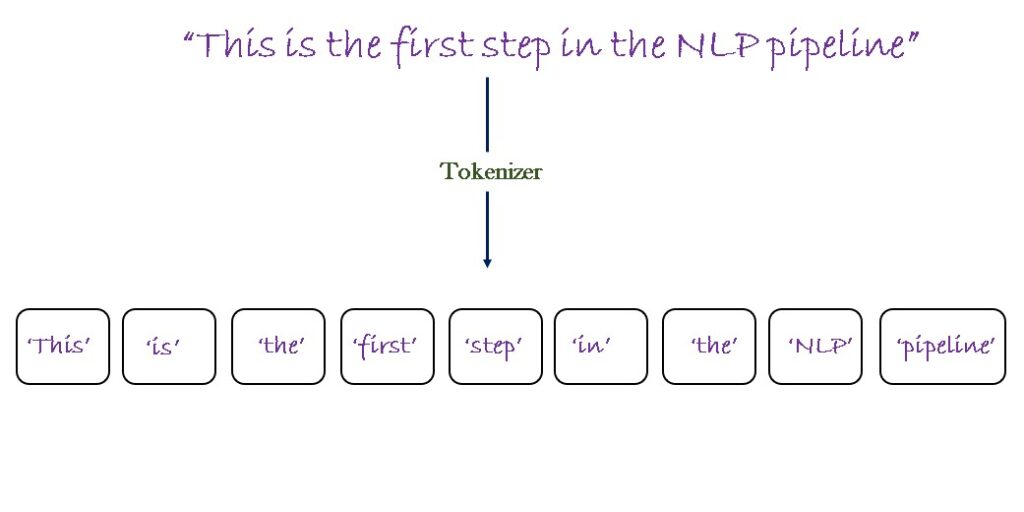
# 1. 自然语言处理简介
自然语言处理(NLP)是人工智能和语言学领域的一个分支,它赋予计算机理解和处理人类语言的能力。从基础的拼写检查到复杂的机器翻译系统,自然语言处理的应用已经深入我们的日常生活中。它将人类的语言转换为计算机能够理解和处理的格式,从而使得机器能够执行从语言翻译到情感分析等多种任务。本章将介绍自然语言处理的基本概念、历史背景、以及在现代科技中的应用,为读者构建起对NLP的初步认识框架。
# 2. NLTK库安装与环境配置
## 2.1 安装NLTK库及其依赖
安装NLTK(Natural Language Toolkit)是进行自然语言处理(NLP)的第一步。NLTK是一个强大的Python库,包含了文本处理所需的各种工具。它为机器学习提供了必要的接口,并且与众多的语言数据资源(corpora)一起使用。
首先,在你的Python环境中安装NLTK,可以使用`pip`命令来完成安装:
```shell
pip install nltk
```
安装完成后,我们需要安装NLTK的额外数据包,这些数据包包含了执行NLP任务所需的基本语料库和词汇资源。你可以通过NLTK提供的`nltk.download()`函数来下载所需的资源:
```python
import nltk
nltk.download('punkt') # 分词器
nltk.download('averaged_perceptron_tagger') # 词性标注器
nltk.download('stopwords') # 停用词表
nltk.download('wordnet') # WordNet的词典
# ... 其他数据包
```
代码逻辑分析:`nltk.download()`函数通过网络下载指定的资源包。参数是资源包的名称,例如`'punkt'`用于分词,`'averaged_perceptron_tagger'`用于词性标注。
在Python中,可以通过`help()`函数查看更多关于`nltk.download()`的信息,例如:
```python
help(nltk.download)
```
参数说明:在调用`nltk.download()`时,可以通过指定不同的参数来下载不同的资源包。例如,`'punkt'`是NLTK内置的分词模型,用于将文本分割成一个个句子或单词。
## 2.2 环境准备和配置方法
确保你有一个合适的Python环境是至关重要的,它将帮助你顺利地进行NLP任务。对于NLTK,推荐使用Python 3.x版本,因为它提供了更广泛的支持和更好的性能。
### Python环境配置
1. 安装Python:
如果你的操作系统是Windows,可以访问Python官网下载安装器;如果是Linux或Mac,通常系统自带Python。你可以通过命令行检查Python版本:
```shell
python --version # 或者 python3
```
2. 创建虚拟环境(可选):
使用虚拟环境有助于隔离项目依赖,避免不同项目间版本冲突。可以使用`venv`模块创建虚拟环境:
```shell
python -m venv myenv
source myenv/bin/activate # Linux或Mac
myenv\Scripts\activate # Windows
```
3. 安装NLTK及依赖:
在创建的虚拟环境中,确保NLTK及其依赖正常安装。
### 配置代码编辑器
安装一个适合编写Python代码的编辑器,例如Visual Studio Code(VS Code)、PyCharm、Sublime Text等。以VS Code为例,你需要安装Python扩展,它支持代码高亮、智能补全、调试和更多功能。
确保安装了Python扩展后,你可以打开命令面板(`Ctrl+Shift+P`),搜索并运行`Python: Select Interpreter`来选择你的Python环境。选择与你刚才创建的虚拟环境相对应的解释器。
### 检查NLTK安装
在Python解释器中或在你的代码编辑器的交互式窗口中,尝试导入NLTK并检查其版本,以确保一切安装正确:
```python
import nltk
print(nltk.__version__)
```
这一步骤不仅可以验证NLTK是否正确安装,还能帮助确认Python环境中是否包含了所有必要的NLTK资源。
在完成这些步骤后,你的Python环境就为进行NLP任务做好了准备。下一节将介绍如何进行文本预处理和分词技术,为后续的NLP分析打下基础。
# 3. 文本预处理与分词技术
在自然语言处理(NLP)中,文本预处理与分词技术是至关重要的步骤。预处理确保了文本数据的质量,去除了对分析无用的信息。分词(Tokenization)则是将文本切分为更小、更易于处理的单位,通常是单词或字符。本章将详细探讨文本预处理和分词技术。
## 3.1 文本清洗和标准化
文本数据往往包含许多不需要的元素,如标点符号、数字和特殊字符。为了确保后续处理的准确性和有效性,首先需要对文本进行清洗和标准化处理。
### 3.1.1 去除标点和数字
在预处理的第一步,我们需要清除文本中的标点符号和数字,它们可能对理解句子含义没有直接贡献,反而会增加后续处理的复杂度。例如,去除句号、逗号和数字等可以简化文本数据。
```python
import string
# 示例文本
text = "Hello, World! NLTK is great. #1."
# 去除标点符号和数字
clean_text = text.translate(str.maketrans('', '', string.punctuation + string.digits))
print(clean_text) # 输出: "Hello World NLTK is great"
```
该代码段首先导入了Python中的`string`模块,然后定义了含有标点和数字的文本。`str.translate`方法与`str.maketrans`结合使用,创建了一个翻译表,用于删除所有标点符号和数字。
### 3.1.2 文本编码的统一
为了处理来自不同源头的文本数据,统一编码是必要的。常见的编码包括ASCII、UTF-8等。使用统一的编码格式可以避免在后续处理中出现乱码和兼容性问题。
```python
# 假设text是原始文本数据,可能包含不同的编码
text = text.encode('utf-8').decode('utf-8')
print(text) # 确保文本是utf-8编码
```
## 3.2 分词基础与高级技巧
分词是将连续的文本切分成一个个有意义的单元(tokens),例如单词或句子。分词的准确度直接影响到后续分析的质量。
### 3.2.1 基于规则的分词方法
基于规则的分词方法依赖于预定义的规则和词典,根据语言学特征如空格、标点等来确定分词边界。这种方法在资源丰富的语言(如英语)上效果较好,但对那些没有明确分隔符的语言(如中文)则不太适用。
```python
# 以空格为基础的分词示例
text = "NLTK is a leading platform for building Python programs to work with human language data."
tokens = text.split()
print(tokens) # 输出: ['NLTK', 'is', 'a', 'leading', 'platform', 'for', 'building', 'Python', 'programs', 'to', 'work', 'with', 'human', 'language', 'data']
```
### 3.2.2 基于统计的分词方法
与基于规则的方法不同,基于统计的分词方法利用机器学习算法和大规模语料库来学习单词出现的模式,从而确定最佳分词方式。这种方法通常在没有明确分隔符的语言中表现更佳。
```python
import nltk
from nltk.tokenize import word_tokenize
# 使用NLTK的word_tokenize方法进行分词
text = "NLTK is a leading platform for building Python programs to work with human language data."
tokens = word_tokenize(text)
print(tokens) # 输出: ['NLTK', 'is', 'a', 'leading', 'platform', 'for', 'building', 'Python', 'programs', 'to', 'work', 'with', 'human', 'language', 'data', '.']
```
在上述代码中,`nltk.tokenize.word_tokenize`函数利用了预先训练好的模型对文本进行分词处理。结果包含了原始文本中的单词和标点符号。
为了进一步展示高级分词技术,我们可以使用正则表达式和条件规则结合的方法来处理文本。
```python
# 正则表达式在分词中的应用示例
import re
# 定义一个简单的正则表达式来匹配连续的英文单词字符
text = "NLTK is a leading platform for building Python programs to work with human language data."
tokens = re.findall(r'\b\w+\b', text)
print(tokens) # 输出: ['NLTK', 'is', 'a', 'leading', 'platform', 'for', 'building', 'Python', 'programs', 'to', 'work', 'with', 'human', 'language', 'data']
```
这个示例使用了正则表达式`\b\w+\b`来匹配由单词边界包围的连续字母和数字序列。这种方法简单有效,但可能不如基于统计的方法准确,特别是在处理歧义时。
## 总结
本章详细介绍了NLP中的文本预处理和分词技术。从基础的文本清洗,如去除标点和数字,到统一文本编码,再到运用不同方法进行分词,每一步都是确保后续分析准确性的关键。基于规则的分词和基于统计的分词方法各有优势和局限,选择合适的方法取决于具体任务和语言的特性。预处理和分词是NLP中的基础,为后续的词性标注、句法分析、语义分析和文本分类等高级处理提供了坚实的基础。
在实际应用中,选择合适的分词工具和方法至关重要。虽然本章主要以英文处理为例,但分词技术在处理中文、日文等其他语言时具有同样的重要性,且技术细节会有所不同。因此,理解并掌握本章内容,对于任何想要深入自然语言处理领域的开发者来说都是必不可少的。
# 4. 词性标注和句法分析
词性标注(Part-of-Speech Tagging, POS Tagging)和句法分析(Parsing)是自然语言处理中的重要组成部分,它们帮助我们理解句子的结构和语法功能,为进一步的语义分析奠定基础。
## 4.1 词性标注(POS Tagging)
### 4.1.1 POS Tagging的原理和应用
词性标注是将文本中的每个词(word)分配到它所属的语法类别(tag)的过程。POS Tagging是理解自然语言的关键步骤之一,它为句法分析、语义理解提供了基础。
在自然语言处理的许多任务中,如信息检索、文本挖掘、机器翻译等,POS Tagging都扮演着至关重要的角色。例如,它可以帮助我们更好地理解查询意图、文本话题、或者翻译过程中的词义选择。
### 4.1.2 常见的POS Tagging模型
#### 统计模型
统计模型,如隐马尔科夫模型(Hidden Markov Model, HMM)和条件随机场模型(Conditional Random Fields, CRF),在POS Tagging领域长期占据主导地位。这些模型依赖于大量带有标注的训练数据来学习不同词汇和标签之间的转换概率。
以CRF为例,它是一种序列建模方法,能够考虑到整个句子的上下文信息,而不是仅依赖于局部信息。CRF通过定义一个联合概率模型来对整个句子的标签序列进行优化。
```python
# 以下是一个简单的CRF模型示例
from sklearn_crfsuite import CRF
from sklearn.metrics import make_scorer, f1_score
# 定义特征提取函数
def word2features(sent, i):
word = sent[i]
postag = sent[i][1]
features = {
'bias': 1.0,
'word.lower()': word.lower(),
'word[-3:]': word[-3:],
'word.isupper()': word.isupper(),
'word.istitle()': word.istitle(),
'word.isdigit()': word.isdigit(),
'postag': postag,
}
return features
# 将标签转换为唯一的整数索引
tag2idx = {"NOUN": 0, "VERB": 1, "ADJ": 2, "ADV": 3, "PRT": 4, "ADP": 5, "CONJ": 6, "DET": 7, "NUM": 8, ".": 9}
# CRF模型训练
crf = CRF(algorithm='lbfgs', max_iterations=100, all_possible_transitions=True)
X_train = [word2features(s, i) for s in sentences for i in range(len(s))]
y_train = [[tag2idx[tag] for tag in doc] for doc in train_tags]
crf.fit(X_train, y_train)
# 模型评估
def evaluate(crf, sentences, true_tags):
y_pred = crf.predict(sentences)
scores = [f1_score(true, pred, average='weighted') for true, pred in zip(true_tags, y_pred)]
return scores
scores = evaluate(crf, test_sentences, test_tags)
print("CRF F1 Score: ", sum(scores)/len(scores))
```
在上述代码中,我们定义了一个特征提取函数`word2features`,它将每个单词转换为一系列特征,然后使用CRF模型进行训练和预测。这里展示了如何从原始数据中提取特征并训练一个CRF模型。该模型可以通过计算F1分数来评估。
## 4.2 句法分析(Parsing)
句法分析是指对句子的结构进行分析,通常通过生成一棵句法树来表示。句法树是句子语法结构的层级表示,其中树的节点表示语法成分,如短语和单词,而边表示这些成分之间的关系。
### 4.2.1 句法树的构建方法
构建句法树是理解句子语法结构的重要步骤。常见的句法分析方法包括基于转移的系统(如转移系统)和基于图表的系统(如CYK算法)。
例如,转移系统通过一系列动作来构建句法树。动作包括“移入”(将下一个单词移入栈中)、“规约”(将栈顶的几个元素规约为一个成分),以及“左分支”和“右分支”(将当前处理的单词作为子成分添加到左边或右边的成分中)。
#### 基于转移的解析示例
```python
# 假设我们有一个简单的移入-规约解析器,我们用一个简化的文法规则集合
# 这里仅用于示例,实际应用中会更复杂
def parse_sentence(sentence):
# 初始化栈和输出缓冲区
stack = ['TOP']
output = []
words = sentence.split()
idx = 0
while stack:
top = stack.pop()
# 移入动作
if top == 'TOP':
stack.append('TOP')
stack.append(words[idx])
idx += 1
# 规约动作
elif top == words[idx]:
stack.append(top)
idx += 1
# 文法规约
else:
# 假设这里的右分支动作是将一个元素添加到短语中
right_phrase = stack.pop()
left_phrase = stack.pop()
stack.append(left_phrase + '->' + right_phrase)
stack.append(left_phrase)
return stack.pop()
# 对句子进行解析
sentence = "the quick brown fox jumps over the lazy dog"
parse_tree = parse_sentence(sentence)
print("Parse Tree:", parse_tree)
```
上述伪代码展示了如何通过一个简化版的移入-规约系统构建句法树。在实际应用中,需要有完备的文法规则和更复杂的决策逻辑来处理各种句型结构。
### 4.2.2 句法分析在语言理解中的作用
句法分析对于语言理解和生成至关重要,它不仅帮助我们揭示句子的语法结构,还可以辅助其他NLP任务,如情感分析、问题回答和文本摘要等。句法树可以作为一种特征输入到机器学习模型中,从而提高模型在特定任务上的性能。
## 总结
通过本章节的介绍,我们了解了词性标注和句法分析在自然语言处理中的重要性。词性标注帮助我们理解词汇的语法功能,而句法分析则揭示了词汇之间的关系和句子的结构。这些技术为后续的语义分析奠定了坚实的基础,使得机器能够更加深入地理解自然语言。
# 5. ```
# 第五章:语义分析与文本分类
在第四章中,我们深入了解了文本预处理和分词技术,以及词性标注和句法分析的重要性。进入第五章,我们将探讨语义分析的深入课题,并介绍文本分类技术与模型。这些技术是自然语言处理领域的核心,它们在理解和处理文本数据方面起到了至关重要的作用。
## 5.1 语义角色标注和词义消歧
### 5.1.1 语义角色标注技术
语义角色标注(Semantic Role Labeling, SRL)是理解句子中各个成分在事件中所扮演角色的过程。这些角色可能包括施事者、受事者、工具、地点、时间等。SRL的目标是识别出句子中的谓语(动词)和与之相关的论元(名词短语或代词),并将它们标注为诸如施事、受事等语义角色。
要实现有效的语义角色标注,我们需要构建一个模型,它能够理解不同句子中谓语和论元的语义关系。现代的SRL系统通常使用深度学习技术,尤其是序列标注模型,例如基于BiLSTM-CRF(双向长短期记忆网络-条件随机场)的模型。
以下是使用Python进行语义角色标注的一个基础示例:
```python
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("The cat sat on the mat.")
for token in doc:
print(f"{token.text:{10}} {token.dep_:{6}} {token.head.text:{10}}")
```
在这个代码段中,我们使用了`spacy`库加载了一个小型的英文模型,并对一个简单的句子进行了标注。`token.dep_`提供了每个词的依存关系标签,而`token.head.text`是该词所依存的中心词。通过这样的分析,可以为语义角色标注打下基础。
### 5.1.2 词义消歧的方法和挑战
词义消歧(Word Sense Disambiguation, WSD)是解决多义词在特定上下文中准确意义的问题。例如,单词“bank”可以表示“银行”或“河岸”,而词义消歧的任务就是根据上下文来判断其具体含义。
实现词义消歧的方法多种多样,从基于规则的方法到基于机器学习的方法。近年来,深度学习模型特别是预训练语言模型(如BERT)在词义消歧任务上展现了出色的性能。
下面是一个使用NLTK库来实现简单词义消歧的例子:
```python
import nltk
from nltk.corpus import wordnet
word = "bank"
synsets = wordnet.synsets(word)
for syn in synsets:
print(f"{syn.name()} ({syn.pos()}) : {syn.definition()}")
# 模拟上下文
context = "river bank"
# 获取上下文中的词义
similarities = dict()
for syn in synsets:
w1 = nltk.WSDCorpusReader().synset(word)
w2 = syn
similarities[syn.name()] = w1.path_similarity(w2)
# 找出最相似的词义
best = max(similarities, key=similarities.get)
print(f"Most similar sense for '{word}' in context '{context}': {best}")
```
在这个示例中,我们首先检索了词“bank”的所有同义词集(synsets),然后根据给定的上下文,使用NLTK的词义消歧器来找出最合适的词义。
## 5.2 文本分类技术与模型
### 5.2.1 文本分类的基本概念
文本分类是自然语言处理和机器学习领域的一个核心问题,它涉及到将文本数据分配到一个或多个类别中。文本分类的应用十分广泛,包括垃圾邮件检测、情感分析、新闻文章分类等等。
从技术角度看,文本分类一般分为以下几步:
1. 数据预处理和特征提取。
2. 模型选择和训练。
3. 模型评估和优化。
在特征提取阶段,常见的方法包括词袋模型(Bag of Words)、TF-IDF(Term Frequency-Inverse Document Frequency)以及基于深度学习的词嵌入(Word Embedding)等。
### 5.2.2 使用NLTK进行文本分类
NLTK库提供了一系列用于文本分类的工具,如朴素贝叶斯分类器(Naive Bayes Classifier)、决策树分类器等。在这一小节中,我们将通过一个简单的示例来展示如何使用NLTK进行文本分类。
假设我们有以下文本数据和相应的标签:
```plaintext
文本数据: 'The quick brown fox jumps over the lazy dog'
标签: 'positive'
文本数据: 'The slow red turtle crawled under the moonlight'
标签: 'negative'
```
我们将使用朴素贝叶斯分类器来训练和分类这些文本数据:
```python
from nltk.corpus import subjectivity
from nltk.sentiment import SentimentAnalyzer
from nltk.sentiment.util import *
from nltk.classify import NaiveBayesClassifier
# 准备训练数据
training_data = [
('The quick brown fox jumps over the lazy dog', 'positive'),
('The slow red turtle crawled under the moonlight', 'negative')
]
# 创建朴素贝叶斯分类器实例
classifier = NaiveBayesClassifier.train(training_data)
# 测试分类器的准确性
test_data = [
('The quick brown fox jumps over the lazy dog', 'positive'),
('The slow red turtle crawled under the moonlight', 'negative')
]
print('Accuracy of the classifier: {:.2f}%'.format(
100 * classify准确率(classifier, test_data)
```
在上述代码中,我们首先导入了`NaiveBayesClassifier`以及相关模块,然后创建了一个朴素贝叶斯分类器实例,并用准备好的数据训练了这个分类器。之后,我们对分类器进行测试,并输出其准确性。
朴素贝叶斯分类器是基于概率理论的简单算法,在许多文本分类任务中都能取得不错的性能。不过,对于更复杂的任务,可能需要使用深度学习方法,例如通过TensorFlow或PyTorch实现的卷积神经网络(CNN)或循环神经网络(RNN)。
通过本章节的介绍,我们探索了语义分析的两个重要方面:语义角色标注和词义消歧。接着,我们深入了解了文本分类技术及其在NLTK库中的应用。在下一章,我们将探索NLTK在实际项目中的应用案例,包括情感分析、自动摘要和问答系统等。
```
# 6. NLTK在实际项目中的应用案例
自然语言处理(NLP)技术已经广泛应用于各个领域,例如情感分析、自动摘要生成以及问答系统等。NLTK(Natural Language Toolkit)作为Python中最流行的NLP库之一,提供了一系列工具和方法,来帮助开发者在实际项目中实现这些应用。
## 6.1 情感分析应用实例
### 6.1.1 情感分析的原理
情感分析(Sentiment Analysis),又称为意见挖掘(Opinion Mining),是NLP中的一项应用,旨在识别和提取文本中所包含的情绪倾向性。这种倾向性可以是正面的(如满意、喜悦)、负面的(如不满、愤怒),或者是中性的(如事实陈述)。在社交媒体、产品评论、客户反馈等领域,情感分析已经成为理解和衡量公众对某一话题或产品态度的有效手段。
### 6.1.2 构建情感分析系统
以下是构建一个基本情感分析系统的步骤:
1. **数据准备**:首先收集一组带有情感标签的文本数据作为训练集。
2. **文本预处理**:清洗数据,进行分词、去除停用词等操作。
3. **特征提取**:将文本转换为机器学习模型能够处理的特征向量,常见的方法有词袋模型(Bag of Words)、TF-IDF等。
4. **模型训练**:使用诸如朴素贝叶斯、支持向量机(SVM)或深度学习模型(如卷积神经网络CNN)等算法来训练情感分类器。
5. **模型评估**:在测试集上评估模型的性能,使用准确率、召回率和F1分数等指标。
6. **应用部署**:将训练好的模型部署到应用程序中,实时分析新的文本数据。
一个简单的Python代码示例,展示了如何使用NLTK和朴素贝叶斯算法进行情感分析:
```python
import nltk
from nltk.corpus import subjectivity
from nltk.sentiment import SentimentAnalyzer
from nltk.sentiment.util import *
# 加载NLTK的股票评论数据集
nltk.download('subjectivity')
nltk.download('punkt')
# 数据准备和预处理
texts = [(sent, 'subj' if lab else 'obj') for sent, lab in subjectivity.sents(categories='subj')]
all_words = nltk.word_tokenize(' '.join(texts).lower())
word_features = list(set(all_words))
def find_features(document):
words = nltk.word_tokenize(document.lower())
features = {}
for word in word_features:
features[word] = (word in words)
return features
# 通过特征提取转换文本
features = [(find_features(text), label) for (text, label) in texts]
# 拆分数据集为训练和测试
train_data, test_data = features[100:], features[:100]
# 训练朴素贝叶斯分类器
sa = SentimentAnalyzer()
train_set = sa.apply_features(find_features, train_data)
trainer = NaiveBayesClassifier.train
classifier = sa.train(trainer, train_set)
# 测试和评估
test_set = sa.apply_features(find_features, test_data)
print(nltk.classify.util.accuracy(classifier, test_set))
# 分析一个新的评论
review = "The movie was fantastic! I really enjoyed it."
print(classifier.classify(find_features(review)))
```
## 6.2 自动摘要和问答系统
### 6.2.1 自动摘要生成技术
自动摘要技术的目标是从大量文本中提取关键信息,生成简洁明了的摘要。自动摘要有两种主要的方法:
- **抽取式摘要**(Extractive Summarization):通过评分机制选择文本中最重要或最相关的句子,然后直接从原文中抽取这些句子形成摘要。
- **生成式摘要**(Abstractive Summarization):通过理解原文内容并重新生成文本,以提供一个更简洁、流畅的摘要。
### 6.2.2 构建简单问答系统
问答系统(Q&A System)是一种模拟人类问答行为的交互式系统,它能够通过解析用户的自然语言问题,然后从知识库中检索或计算出答案。构建一个简单的问答系统需要以下步骤:
1. **问题理解**:通过自然语言处理技术解析问题,理解问题的意图和关键信息。
2. **知识检索**:在知识库中检索与问题相关的信息。
3. **答案生成**:根据检索到的信息生成答案。
4. **答案优化**:优化答案的形式,使其更加符合用户的需求和期望。
使用NLTK构建一个简单的问答系统涉及到对话管理、意图识别、实体抽取等方面。例如,可以利用NLTK中的正则表达式来实现简单的实体抽取,结合预先设定的知识库来生成答案。
```python
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.tag import pos_tag
from nltk.chunk import ne_chunk
# 示例问题和知识库
question = "Who is the founder of Apple?"
knowledge_base = {
'founder': 'Steve Jobs',
'company': 'Apple',
'position': 'founder'
}
# 简单的实体抽取和回答逻辑
def answer_question(question):
sentences = sent_tokenize(question)
tokens = word_tokenize(question)
pos_tags = pos_tag(tokens)
# 查找问题中的命名实体
chunked = ne_chunk(pos_tags)
for subtree in chunked:
if type(subtree) == nltk.tree.Tree and subtree.label() == 'PERSON':
person = ' '.join(word for word, tag in subtree.leaves())
if person in knowledge_base:
return knowledge_base[person]
else:
return "I'm sorry, I don't have the answer to that."
return "I'm sorry, I don't have the answer to that."
print(answer_question(question))
```
在这段代码中,我们通过正则表达式定义了一个简单的实体抽取规则,当检测到问题中包含“PERSON”类型的命名实体时,尝试从预设的知识库中检索答案。如果没有匹配项或问题不符合预期格式,则返回无法回答的信息。
第六章介绍的实际应用案例展示了NLTK在解决NLP实际问题中的强大能力和灵活性。通过这些例子,可以了解到NLTK如何协助开发者构建功能丰富的自然语言处理系统。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 NLTK 专栏,这是一份全面的指南,旨在帮助您掌握自然语言处理 (NLP) 的强大功能。本专栏涵盖了从基础到高级的广泛主题,包括词性标注、句法分析、情感分析、语言学资源管理、机器学习集成、插件和扩展、深度学习准备、跨平台应用、错误处理、云计算、网络安全、数据可视化和移动集成。通过本专栏,您将深入了解 NLTK 的功能,并学习如何利用它来解决各种 NLP 挑战。无论您是 NLP 新手还是经验丰富的从业者,本专栏都将为您提供宝贵的见解和实用技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘ETA6884移动电源的超速充电:全面解析3A充电特性

# 摘要
本文详细探讨了ETA6884移动电源的技术规格、充电标准以及3A充电技术的理论与应用。通过对充电技术的深入分析,包括其发展历程、电气原理、协议兼容性、安全性理论以及充电实测等,我们提供了针对ETA6884移动电源性能和效率的评估。此外,文章展望了未来充电技术的发展趋势,探讨了智能充电、无线充电以
【编程语言选择秘籍】:项目需求匹配的6种语言选择技巧

# 摘要
本文全面探讨了编程语言选择的策略与考量因素,围绕项目需求分析、性能优化、易用性考量、跨平台开发能力以及未来技术趋势进行深入分析。通过对不同编程语言特性的比较,本文指出在进行编程语言选择时必须综合考虑项目的特定需求、目标平台、开发效率与维护成本。同时,文章强调了对新兴技术趋势的前瞻性考量,如人工智能、量子计算和区块链等,以及编程语言如何适应这些技术的变化。通
【信号与系统习题全攻略】:第三版详细答案解析,一文精通

# 摘要
本文系统地介绍了信号与系统的理论基础及其分析方法。从连续时间信号的基本分析到频域信号的傅里叶和拉普拉斯变换,再到离散时间信号与系统的特性,文章深入阐述了各种数学工具如卷积、
微波集成电路入门至精通:掌握设计、散热与EMI策略

# 摘要
本文系统性地介绍了微波集成电路的基本概念、设计基础、散热技术、电磁干扰(EMI)管理以及设计进阶主题和测试验证过程。首先,概述了微波集成电路的简介和设计基础,包括传输线理论、谐振器与耦合结构,以及高频电路仿真工具的应用。其次,深入探讨了散热技术,从热导性基础到散热设计实践,并分析了散热对电路性能的影响及热管理的集成策略。接着,文章聚焦于EMI管理,涵盖了EMI基础知识、
Shell_exec使用详解:PHP脚本中Linux命令行的实战魔法

# 摘要
本文详细探讨了PHP中的Shell_exec函数的各个方面,包括其基本使用方法、在文件操作与网络通信中的应用、性能优化以及高级应用案例。通过对Shell_exec函数的语法结构和安全性的讨论,本文阐述了如何正确使用Shell_exec函数进行标准输出和错误输出的捕获。文章进一步分析了Shell_exec在文件操作中的读写、属性获取与修改,以及网络通信中的Web服
NetIQ Chariot 5.4高级配置秘籍:专家教你提升网络测试效率

# 摘要
NetIQ Chariot是网络性能测试领域的重要工具,具有强大的配置选项和高级参数设置能力。本文首先对NetIQ Chariot的基础配置进行了概述,然后深入探讨其高级参数设置,包括参数定制化、脚本编写、性能测试优化等关键环节。文章第三章分析了Net
【信号完整性挑战】:Cadence SigXplorer仿真技术的实践与思考
# 摘要
本文全面探讨了信号完整性(SI)的基础知识、挑战以及Cadence SigXplorer仿真技术的应用与实践。首先介绍了信号完整性的重要性及其常见问题类型,随后对Cadence SigXplorer仿真工具的特点及其在SI分析中的角色进行了详细阐述。接着,文章进入实操环节,涵盖了仿真环境搭建、模型导入、仿真参数设置以及故障诊断等关键步骤,并通过案例研究展示了故障诊断流程和解决方案。在高级
【Python面向对象编程深度解读】:深入探讨Python中的类和对象,成为高级程序员!

# 摘要
本文深入探讨了面向对象编程(OOP)的核心概念、高级特性及设计模式在Python中的实现和应用。第一章回顾了面向对象编程的基础知识,第二章详细介绍了Python类和对象的高级特性,包括类的定义、继承、多态、静态方法、类方法以及魔术方法。第三章深入讨论了设计模式的理论与实践,包括创建型、结构型和行为型模式,以及它们在Python中的具体实现。第四
Easylast3D_3.0架构设计全解:从理论到实践的转化
# 摘要
Easylast3D_3.0是一个先进的三维设计软件,其架构概述及其核心组件和理论基础在本文中得到了详细阐述。文中详细介绍了架构组件的解析、设计理念与原则以及性能评估,强调了其模块间高效交互和优化策略的重要性。
【提升器件性能的秘诀】:Sentaurus高级应用实战指南

# 摘要
Sentaurus是一个强大的仿真工具,广泛应用于半导体器件和材料的设计与分析中。本文首先概述了Sentaurus的工具基础和仿真环境配置,随后深入探讨了其仿真流程、结果分析以及高级仿真技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )