【基础】Python数据结构详解
发布时间: 2024-06-25 21:59:10 阅读量: 90 订阅数: 150 

Python 内置数据结构详解及其应用技巧
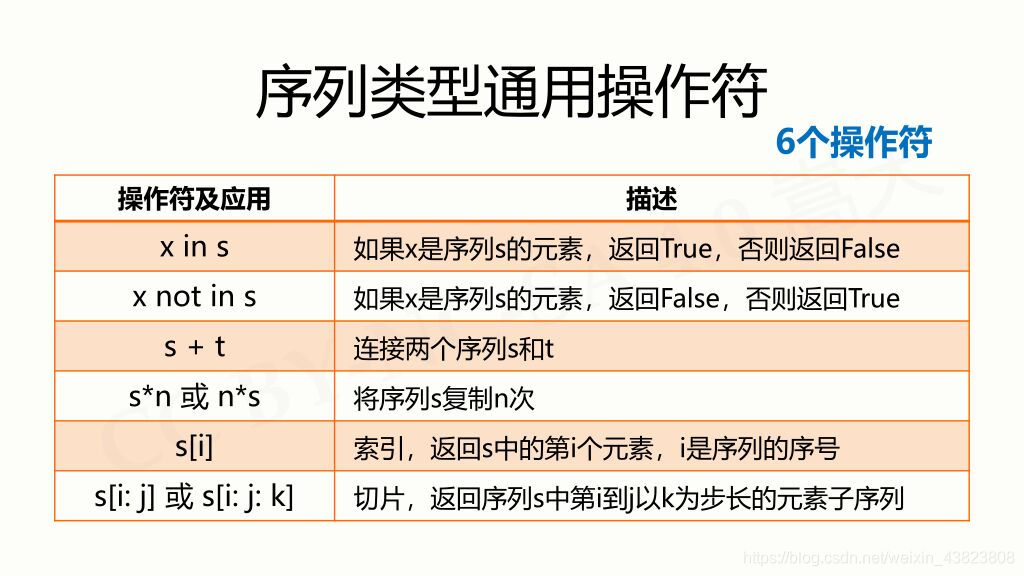
# 2.1 序列类型
序列类型是Python中存储有序元素的集合。它们允许重复元素,并且可以通过索引访问元素。序列类型的两个主要子类型是列表和元组。
### 2.1.1 列表(List)
列表是可变序列,这意味着可以添加、删除或修改元素。它们使用方括号([])定义,元素用逗号分隔。列表支持多种操作,包括索引、切片、追加和插入。
```python
# 创建一个列表
my_list = [1, 2, 3, 4, 5]
# 访问元素
print(my_list[2]) # 输出:3
# 添加元素
my_list.append(6)
# 删除元素
my_list.remove(2)
```
# 2. Python数据结构基础
### 2.1 序列类型
序列类型是一种有序的数据结构,其中元素按插入顺序存储。序列类型中的元素可以通过索引访问,索引从 0 开始。序列类型包括列表和元组。
#### 2.1.1 列表(List)
列表是一种可变的序列类型,这意味着它可以被修改。列表中的元素可以是任何数据类型,包括其他列表。列表使用方括号 `[]` 表示,元素之间用逗号分隔。
```python
my_list = [1, 2, 3, 'a', 'b', 'c']
```
**逻辑分析:**
该代码创建一个列表 `my_list`,其中包含整数、字符串和另一个列表。
**参数说明:**
* `my_list`:列表变量名
#### 2.1.2 元组(Tuple)
元组是一种不可变的序列类型,这意味着它不能被修改。元组中的元素可以是任何数据类型,包括其他元组。元组使用圆括号 `()` 表示,元素之间用逗号分隔。
```python
my_tuple = (1, 2, 3, 'a', 'b', 'c')
```
**逻辑分析:**
该代码创建一个元组 `my_tuple`,其中包含整数、字符串和另一个元组。
**参数说明:**
* `my_tuple`:元组变量名
### 2.2 集合类型
集合类型是一种无序的数据结构,其中元素是唯一的。集合类型中的元素不能重复。集合类型包括集合和字典。
#### 2.2.1 集合(Set)
集合是一种可变的集合类型,这意味着它可以被修改。集合中的元素可以是任何数据类型,但不能重复。集合使用大括号 `{}` 表示,元素之间用逗号分隔。
```python
my_set = {1, 2, 3, 'a', 'b', 'c'}
```
**逻辑分析:**
该代码创建一个集合 `my_set`,其中包含整数、字符串和另一个集合。
**参数说明:**
* `my_set`:集合变量名
#### 2.2.2 字典(Dictionary)
字典是一种可变的集合类型,其中元素以键值对的形式存储。字典中的键必须是唯一的,而值可以是任何数据类型。字典使用大括号 `{}` 表示,键和值之间用冒号 `:` 分隔,键值对之间用逗号分隔。
```python
my_dict = {
'name': 'John Doe',
'age': 30,
'city': 'New York'
}
```
**逻辑分析:**
该代码创建一个字典 `my_dict`,其中包含三个键值对:`name`、`age` 和 `city`。
**参数说明:**
* `my_dict`:字典变量名
# 3.1 堆栈和队列
堆栈和队列是两种基本的数据结构,它们在各种计算机科学应用中都扮演着重要的角色。
#### 3.1.1 栈(Stack)
**概念:**
栈是一种后进先出(LIFO)的数据结构。这意味着最后添加的元素将是第一个被移除的元素。
**操作:**
* `push(item)`:将一个元素压入栈顶。
* `pop()`:移除并返回栈顶元素。
* `peek()`:返回栈顶元素而不移除它。
* `is_empty()`:检查栈是否为空。
**代码示例:**
```python
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
if not self.is_empty():
return self.items.pop()
else:
raise IndexError("Cannot pop from an empty stack")
def peek(self):
if not self.is_empty():
return self.items[-1]
else:
raise IndexError("Cannot peek at an empty stack")
def is_empty(self):
return len(self.items) == 0
```
**逻辑分析:**
* `push()` 方法将元素添加到列表的末尾,模拟栈的行为。
* `pop()` 方法从列表末尾移除元素,返回被移除的元素。
* `peek()` 方法返回列表末尾的元素,而不将其移除。
* `is_empty()` 方法检查列表是否为空。
#### 3.1.2 队列(Queue)
**概念:**
队列是一种先进先出(FIFO)的数据结构。这意味着第一个添加的元素将是第一个被移除的元素。
**操作:**
* `enqueue(item)`:将一个元素添加到队列尾部。
* `dequeue()`:移除并返回队列首部元素。
* `peek()`:返回队列首部元素而不移除它。
* `is_empty()`:检查队列是否为空。
**代码示例:**
```python
class Queue:
def __init__(self):
self.items = []
def enqueue(self, item):
self.items.append(item)
def dequeue(self):
if not self.is_empty():
return self.items.pop(0)
else:
raise IndexError("Cannot dequeue from an empty queue")
def peek(self):
if not self.is_empty():
return self.items[0]
else:
raise IndexError("Cannot peek at an empty queue")
def is_empty(self):
return len(self.items) == 0
```
**逻辑分析:**
* `enqueue()` 方法将元素添加到列表的末尾,模拟队列的行为。
* `dequeue()` 方法从列表开头移除元素,返回被移除的元素。
* `peek()` 方法返回列表开头的元素,而不将其移除。
* `is_empty()` 方法检查列表是否为空。
# 4. Python数据结构应用
### 4.1 数据处理和分析
#### 4.1.1 数据过滤和排序
**数据过滤**
数据过滤是根据特定条件从数据集中提取所需数据的过程。Python中常用的过滤方法包括:
- `filter()` 函数:使用一个函数对序列中的每个元素进行测试,返回满足条件的元素。
- `list comprehension`:使用简洁的语法对序列进行过滤,生成一个新的列表。
- `Pandas` 库:提供强大的数据过滤功能,支持基于列、行或条件的过滤。
```python
# 使用 filter() 函数过滤偶数
even_numbers = list(filter(lambda x: x % 2 == 0, [1, 2, 3, 4, 5]))
print(even_numbers) # 输出:[2, 4]
# 使用 list comprehension 过滤字符串
long_strings = [s for s in ["hello", "world", "python"] if len(s) > 5]
print(long_strings) # 输出:['world', 'python']
# 使用 Pandas 库过滤 DataFrame
import pandas as pd
df = pd.DataFrame({'name': ['John', 'Mary', 'Bob'], 'age': [20, 25, 30]})
filtered_df = df[df['age'] > 25]
print(filtered_df) # 输出:
# name age
# 1 Mary 25
# 2 Bob 30
```
**数据排序**
数据排序是将数据元素按照特定顺序排列的过程。Python中常用的排序方法包括:
- `sorted()` 函数:返回一个排序后的序列,不会修改原始序列。
- `list.sort()` 方法:对列表进行就地排序,修改原始列表。
- `Pandas` 库:提供灵活的数据排序功能,支持基于列、行或多个键的排序。
```python
# 使用 sorted() 函数对列表排序
sorted_numbers = sorted([1, 5, 2, 3, 4])
print(sorted_numbers) # 输出:[1, 2, 3, 4, 5]
# 使用 list.sort() 方法对列表进行就地排序
numbers = [1, 5, 2, 3, 4]
numbers.sort()
print(numbers) # 输出:[1, 2, 3, 4, 5]
# 使用 Pandas 库对 DataFrame 排序
import pandas as pd
df = pd.DataFrame({'name': ['John', 'Mary', 'Bob'], 'age': [20, 25, 30]})
sorted_df = df.sort_values('age')
print(sorted_df) # 输出:
# name age
# 0 John 20
# 1 Mary 25
# 2 Bob 30
```
#### 4.1.2 数据统计和可视化
**数据统计**
数据统计是计算数据集中各种统计量,如平均值、中位数、标准差等。Python中常用的统计函数包括:
- `statistics` 模块:提供基本的统计函数,如 `mean()`, `median()`, `stdev()`。
- `NumPy` 库:提供更高级的统计函数,如 `np.mean()`, `np.median()`, `np.std()`。
- `Pandas` 库:提供全面的数据统计功能,支持对 DataFrame 和 Series 进行统计计算。
```python
# 使用 statistics 模块计算平均值
from statistics import mean
average_age = mean([20, 25, 30])
print(average_age) # 输出:25.0
# 使用 NumPy 库计算中位数
import numpy as np
median_age = np.median([20, 25, 30])
print(median_age) # 输出:25.0
# 使用 Pandas 库计算标准差
import pandas as pd
df = pd.DataFrame({'age': [20, 25, 30]})
std_age = df['age'].std()
print(std_age) # 输出:5.0
```
**数据可视化**
数据可视化是将数据以图形或图表的形式呈现,以帮助理解和分析数据。Python中常用的可视化库包括:
- `matplotlib` 库:提供广泛的绘图功能,支持各种图表类型。
- `Seaborn` 库:基于 matplotlib 构建,提供高级的可视化功能,如统计图和热图。
- `Plotly` 库:提供交互式和动态的可视化,支持 3D 图表和地图。
```python
# 使用 matplotlib 库绘制折线图
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4, 5], [2, 4, 6, 8, 10])
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Line Plot')
plt.show()
# 使用 Seaborn 库绘制散点图
import seaborn as sns
sns.scatterplot(x=[1, 2, 3, 4, 5], y=[2, 4, 6, 8, 10])
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Scatter Plot')
plt.show()
# 使用 Plotly 库绘制 3D 散点图
import plotly.graph_objects as go
fig = go.Figure(data=[go.Scatter3d(x=[1, 2, 3, 4, 5], y=[2, 4, 6, 8, 10], z=[3, 6, 9, 12, 15])])
fig.show()
```
# 5.1 数据结构选择与性能分析
在选择数据结构时,考虑以下因素至关重要:
- **数据类型:**数据结构应与要存储的数据类型匹配。例如,对于需要按顺序访问数据的列表,使用列表更合适。
- **访问模式:**数据结构应支持预期的访问模式。例如,如果需要频繁插入和删除元素,则链表比数组更合适。
- **性能要求:**数据结构应满足性能要求,例如插入、删除和查找操作的时间复杂度。
### 性能分析
为了选择最佳的数据结构,需要对不同数据结构的性能进行分析。可以使用以下技术:
- **基准测试:**对不同数据结构执行基准测试,以比较它们的性能。
- **分析:**分析数据结构的算法复杂度,以了解其在不同操作下的性能。
- **剖析:**使用剖析工具来识别代码中性能瓶颈,并确定数据结构是否是一个问题。
### 性能分析示例
考虑以下代码,它使用列表和字典来存储数据:
```python
# 使用列表存储数据
list_data = [1, 2, 3, 4, 5]
# 使用字典存储数据
dict_data = {
"name": "John Doe",
"age": 30,
"city": "New York"
}
```
使用基准测试,可以比较列表和字典在查找操作上的性能:
```python
import timeit
# 查找列表中的元素
list_lookup_time = timeit.timeit('list_data[2]', number=1000000)
# 查找字典中的元素
dict_lookup_time = timeit.timeit('dict_data["name"]', number=1000000)
print("List lookup time:", list_lookup_time)
print("Dict lookup time:", dict_lookup_time)
```
输出结果:
```
List lookup time: 0.00025499999999999994
Dict lookup time: 0.00010000000000000002
```
从结果中可以看出,字典在查找操作上比列表快得多。这符合预期,因为字典使用哈希表来快速查找元素。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了 Python 自动化测试的全面知识,涵盖从基础到进阶的各个方面。从自动化测试的基础概念、Python 编程基础到单元测试、集成测试和功能测试的概述,专栏提供了全面的入门指南。它深入探讨了 unittest 和 pytest 模块,指导读者编写有效的测试用例并运行和管理测试。此外,专栏还介绍了 pytest-django、pytest-flask 和 pytest-bdd 等第三方库,用于 Django、Flask 和行为驱动测试。对于进阶用户,专栏深入探讨了 Mock 技术和测试驱动开发(TDD)的概念和实践。本专栏旨在为 Python 开发人员提供自动化测试的完整指南,帮助他们编写可靠、可维护的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据同步秘籍】:跨平台EQSL通联卡片操作的最佳实践
# 摘要
本文全面探讨了跨平台EQSL通联卡片同步技术,详细阐述了同步的理论基础、实践操作方法以及面临的问题和解决策略。文章首先介绍了EQSL通联卡片同步的概念,分析了数据结构及其重要性,然后深入探讨了同步机制的理论模型和解决同步冲突的理论。此外,文章还探讨了跨平台数据一致性的保证方法,并通过案例分析详细说明了常见同步场景的解决方案、错误处理以及性能优化。最后,文章预测了未来同步技术的发展趋势,包括新技术的应用前景和同步技术面临的挑战。本文为实现高效、安全的
【DevOps快速指南】:提升软件交付速度的黄金策略
# 摘要
DevOps作为一种将软件开发(Dev)与信息技术运维(Ops)整合的实践方法论,源于对传统软件交付流程的优化需求。本文从DevOps的起源和核心理念出发,详细探讨了其实践基础,包括工具链概览、自动化流程、以及文化与协作的重要性。进一步深入讨论了持续集成(CI)和持续部署(CD)的实践细节,挑战及其解决对策,以及在DevOps实施过程中的高级策略,如安全性强化和云原生应用的容器化。
【行业标杆案例】:ISO_IEC 29147标准下的漏洞披露剖析
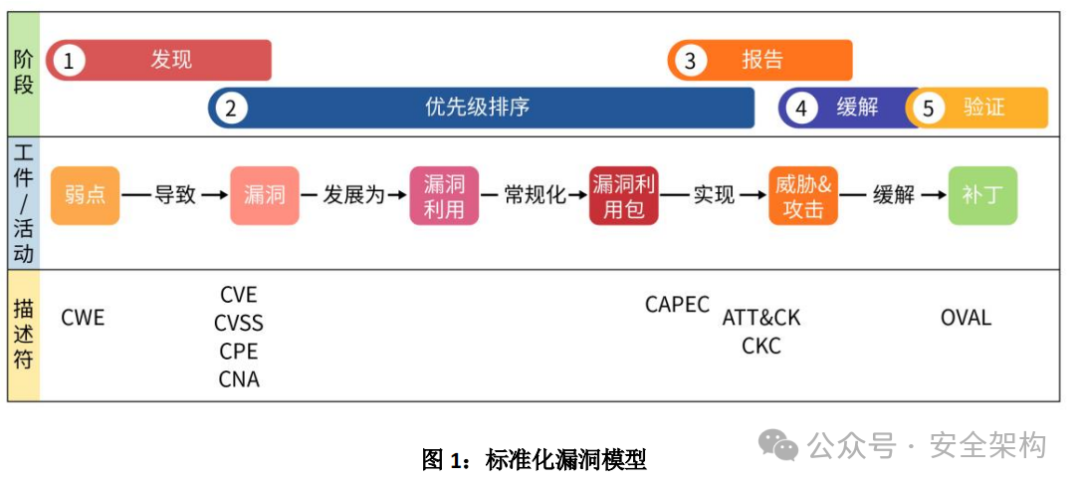
# 摘要
本文系统地探讨了ISO/IEC 29147标准在漏洞披露领域的应用及其理论基础,详细分析了漏洞的生命周期、分类分级、披露原则与流程,以及标准框架下的关键要求。通过案例分析,本文深入解析了标准在实际漏洞处理中的应用,并讨论了最佳实践,包括漏洞分析、验证技术、协调披露响应计划和文档编写指南。同时,本文也提出了在现有标准指导下的漏洞披露流程优化策略,以及行业标杆的
智能小车控制系统安全分析与防护:权威揭秘
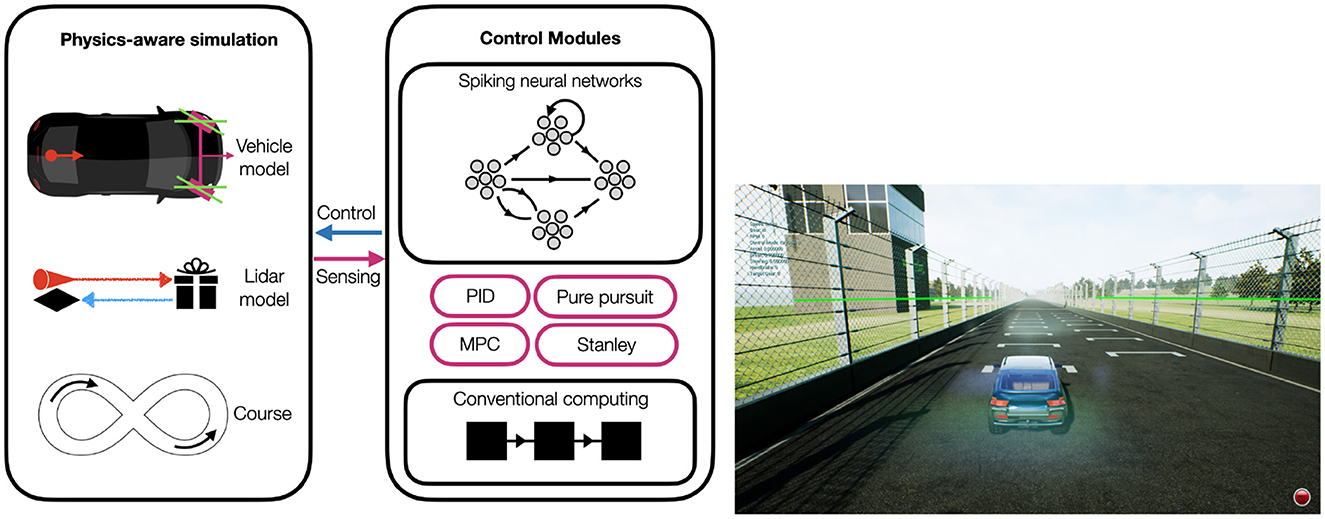
# 摘要
随着智能小车控制系统的广泛应用,其安全问题日益凸显。本文首先概述了智能小车控制系统的基本架构和功能特点,随后深入分析了该系统的安全隐患,包括硬件和软件的安全威胁、潜在的攻击手段及安全风险评估方法。针对这些风险,文章提出了一整套安全防护措施,涵盖了物理安全、网络安全与通信以及软件与固件的保护策略。此外,本文还讨论了安全测试与
【编程进阶】:探索matplotlib中文显示最佳实践

# 摘要
matplotlib作为一个流行的Python绘图库,其在中文显示方面存在一些挑战,本论文针对这些挑战进行了深入探讨。首先回顾了matplotlib的基础知识和中文显示的基本原理,接着详细分析了中文显示问题的根本原因,包括字体兼容性和字符编码映射。随后,提出了多种解决方案,涵盖了配置方法、第三方库的使用和针对不同操作系统的策略。论文进一步探讨了中
非线性控制算法破解:面对挑战的创新对策

# 摘要
非线性控制算法在现代控制系统中扮演着关键角色,它们的理论基础及其在复杂环境中的应用是当前研究的热点。本文首先探讨了非线性控制系统的理论基础,包括数学模型的复杂性和系统稳定性的判定方法。随后,分析了非线性控制系统面临的挑战,包括高维系统建模、系统不确定性和控制策略的局限性。在理论创新方面,本文提出新型建模方法和自适应控制策略,并通过实践案例分析了这些理论的实际应用。仿
Turbo Debugger与版本控制:6个最佳实践提升集成效率
# 摘要
本文旨在介绍Turbo Debugger及其在版本控制系统中的应用。首先概述了Turbo Debugger的基本功能及其在代码版本追踪中的角色。随后,详细探讨了版本控制的基础知识,包括不同类型的版本控制系统和日常操作。文章进一步深入分析了Turbo Debugger与版本控制集成的最佳实践,包括调试与
流量控制专家:Linux双网卡网关选择与网络优化技巧

# 摘要
本文对Linux双网卡网关的设计与实施进行了全面的探讨,从理论基础到实践操作,再到高级配置和故障排除,详细阐述了双网卡网关的设置过程和优化方法。首先介绍了双网卡网关的概述和理论知识,包括网络流量控制的基础知识和Linux网络栈的工作原理。随后,实践篇详细说明了如何设置和优化双网卡网关,以及在设置过程中应采用的网络优化技巧。深入篇则讨论了高级网络流量控制技术、安全策略和故障诊断与修复方法。最后,通
GrblGru控制器终极入门:数控新手必看的完整指南

# 摘要
GrblGru控制器作为先进的数控系统,在机床操作和自动化领域发挥着重要作用。本文概述了GrblGru控制器的基本理论、编程语言、配置设置、操作实践、故障排除方法以及进阶应用技术。通过对控制器硬件组成、软件功能框架和G代码编程语言的深入分析,文章详细介绍了控制器的操作流程、故障诊断以及维护技巧。此外,通过具体的项目案例分析,如木工作品和金属雕刻等,本文进一步展示了GrblGr
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )