深入理解Python优化:让你的代码效率飞跃的7种策略
发布时间: 2024-08-31 13:10:05 阅读量: 108 订阅数: 79 

深入理解快速排序:Python实现与优化策略

# 1. Python优化概述
在当今信息飞速发展的时代,Python已成为IT行业中不可或缺的一部分。它以简洁的语法、强大的功能以及广泛的第三方库支持,广泛应用于从Web开发、数据分析到人工智能的各个领域。然而,随着应用场景的复杂化与性能要求的提高,Python代码的性能优化显得尤为关键。优化不仅仅是为了提升程序的执行效率,更是为了提高资源利用率、增强用户体验和缩短产品上市时间。在这一章节,我们将探讨性能优化的重要性,并对优化策略进行初步概述,为后续章节的深入分析和实践应用奠定基础。
# 2. Python代码的性能分析
## 2.1 性能分析工具的介绍
### 2.1.1 cProfile的使用方法
cProfile是Python标准库中提供的一个性能分析工具,能够帮助开发者了解程序运行期间函数调用的时间开销。使用cProfile对Python程序进行性能分析时,可以按照以下步骤操作:
首先,可以使用命令行直接运行cProfile,指定要分析的Python脚本:
```bash
python -m cProfile -s time my_script.py
```
在这个命令中,`-m cProfile`表示调用cProfile模块,`-s time`表示按照函数调用所花费的时间排序结果,`my_script.py`是需要分析的脚本文件名。
在Python代码中直接使用cProfile也非常方便:
```python
import cProfile
def function_to_analyze():
# 这里写入你想要分析的代码
pass
if __name__ == "__main__":
profiler = cProfile.Profile()
profiler.enable()
function_to_analyze()
profiler.disable()
profiler.print_stats()
```
这段代码首先导入了`cProfile`模块,并在程序的主体部分创建了一个`Profile`实例。通过调用`enable()`和`disable()`方法来控制分析的开始和结束。最后,`print_stats()`方法会打印出分析统计的结果。
cProfile能够提供相当详尽的性能数据,包括调用次数、总时间、平均时间等,这些数据可以帮助开发者定位性能瓶颈。
### 2.1.2 line_profiler的深入应用
虽然cProfile非常有用,但它不能提供每一行代码执行时间的详细信息。此时,`line_profiler`就显得尤为重要,它是一款用于提供代码逐行执行时间的分析工具。可以通过以下步骤使用`line_profiler`:
1. 安装`line_profiler`:
```bash
pip install line_profiler
```
2. 在要分析的函数上方添加装饰器`@profile`(这个装饰器是`line_profiler`识别被分析函数的方式)。
3. 使用`kernprof`命令来分析脚本:
```bash
kernprof -l -v my_script.py
```
`-l`表示行级别的分析,`-v`表示详细输出结果。
`line_profiler`能够提供每行代码的具体执行时间,非常适合对性能要求极高的代码段进行优化。它能够揭示出一些意想不到的性能瓶颈,比如某些小循环的效率低下导致整个程序性能下降。
## 2.2 理解性能瓶颈
### 2.2.1 CPU瓶颈的识别
识别CPU瓶颈主要是为了确定程序中哪些部分占用了过多的CPU资源。典型的CPU瓶颈表现为算法复杂度过高或循环执行过于频繁。
在使用性能分析工具时,特别需要注意那些函数调用次数较多和执行时间较长的部分。如果分析结果显示某个函数消耗了绝大多数CPU资源,那么很可能就是性能瓶颈所在。
为了识别CPU瓶颈,我们通常采取以下步骤:
1. 使用cProfile或line_profiler对代码进行性能分析。
2. 根据报告中函数的调用次数和执行时间排序,找出消耗时间最多的函数。
3. 分析这些函数内部的算法复杂度和循环逻辑,寻找优化的空间。
### 2.2.2 I/O瓶颈的识别和处理
I/O瓶颈是指程序在进行输入输出操作时,尤其是读写磁盘或者网络请求时,耗时较长导致性能下降的情况。识别I/O瓶颈通常涉及以下几个步骤:
1. 运行性能分析工具并查看报告中哪些函数涉及大量的I/O操作。
2. 分析这些函数的I/O逻辑,查找可能的问题,比如不必要的大文件读写、频繁的小文件操作或者网络延时等。
3. 采用如下的策略来优化I/O瓶颈:
- **合并小文件操作**:在可能的情况下,合并多个小文件操作为一个大文件操作,减少I/O调用的次数。
- **异步I/O操作**:如果适用,使用异步I/O来避免程序在等待I/O操作完成时阻塞。
- **使用缓存**:对于重复的I/O操作,可以采用缓存机制,避免重复读写。
接下来,我们将深入探讨如何优化Python代码,提高程序的性能。
# 3. 优化Python代码实践
## 3.1 算法和数据结构的优化
### 3.1.1 时间复杂度和空间复杂度
在程序优化的过程中,对算法和数据结构的选择至关重要。算法的效率通常用时间复杂度和空间复杂度两个指标来衡量。时间复杂度表示算法执行时间随输入数据量增长的变化趋势,而空间复杂度则反映算法在运行过程中临时占用存储空间的大小。
对于时间复杂度,常见的复杂度顺序从低到高依次是 O(1), O(log n), O(n), O(n log n), O(n²), O(2ⁿ), O(n!)。举例来说,对于一个长度为n的列表,使用for循环进行遍历的时间复杂度是O(n),而嵌套循环则可能是O(n²)。尽可能选择时间复杂度更低的算法,尤其是在处理大规模数据时更为关键。
空间复杂度的考量也很重要。如果一个算法使用额外的空间很少,我们称它为原地(in-place)操作,空间复杂度为O(1)。相反,如果算法需要额外的空间与输入数据量成正比,则空间复杂度为O(n)。比如在排序问题中,快速排序的空间复杂度为O(log n)(递归栈空间),而归并排序则需要O(n)的额外空间。
### 3.1.2 列表推导式和生成器的使用
Python 提供了列表推导式(List Comprehension)和生成器(Generators)这两种便捷的数据结构处理方式,它们不仅可以使代码更加简洁,还能提高程序的执行效率。
列表推导式是一种从其他列表派生出新列表的简洁方式。例如,对于一个数字列表 `[1, 2, 3, 4, 5]`,使用列表推导式快速创建一个包含每个数字平方的列表,代码如下:
```python
squares = [x**2 for x in range(1, 6)]
```
生成器是一种特殊的迭代器,它允许在迭代过程中逐个产生值,而不是一次性生成整个列表。这样可以节省内存,特别是处理大量数据时。例如,使用生成器表达式来遍历一个大范围的数字并产生平方值:
```python
squares_generator = (x**2 for x in range(1, 6))
```
需要注意的是,虽然列表推导式和生成器可以提高代码效率,但它们并不总是最优解。在一些情况下,传统的循环可能更易于调试和维护。
## 3.2 利用Python标准库优化
### 3.2.1 高效的字符串操作
Python标准库中包含了诸多用于高效处理字符串的方法和模块。其中,`str` 类型提供了多种方法用于字符串的拼接、分割、替换等常见操作。
字符串的拼接如果使用 `+` 操作符在循环中会非常低效,因为它会不断创建新的字符串对象。推荐使用 `str.join()` 方法进行高效拼接。例如:
```python
words = ['Hello', 'World', 'Python']
sentence = ' '.join(words)
```
此外,使用 `re` 模块可以高效地进行复杂的字符串匹配和文本解析。正则表达式是处理文本的强大工具,但需要小心其性能消耗,特别是在复杂的模式匹配中。对于简单的情况,使用字符串的 `.replace()` 和 `.split()` 方法更加高效。
### 3.2.2 集合和字典的高级用法
Python 中的集合(Set)和字典(Dict)是处理数据集和键值对映射的高效数据结构。它们都基于哈希表实现,拥有常数时间复杂度 O(1) 的查找、添加和删除操作。
集合特别适合用于去重和成员资格检查:
```python
unique_items = set([1, 2, 2, 3, 3, 3])
```
字典同样高效,它允许以键值对的形式存储数据。字典推导式(Dictionary Comprehension)可以简洁地构建字典:
```python
squares_dict = {x: x**2 for x in range(1, 6)}
```
在涉及到查找和统计的场景中,使用集合和字典可以大幅减少代码的复杂度,并提升执行效率。字典在处理大量的键值对映射时尤其有优势。
以上所述的每一个实践点,都是基于对Python语言深刻理解后的优化建议。通过对算法和数据结构的精深了解,使用标准库提供的高级功能,能够使Python程序在保证功能的同时,还能拥有更好的性能表现。随着实践的不断深入,我们能够进一步体会Python的灵活和强大,并通过各种优化手段,达到提升性能的目的。
# 4. Python内存管理
在处理大型数据集或复杂系统时,内存管理显得尤为重要。Python中的内存管理虽然大部分由解释器自动处理,但开发者仍然需要了解基本原理以及如何诊断和修复内存泄漏问题,并且掌握内存优化技巧,以确保程序运行的高效性和稳定性。
## 4.1 内存泄漏的诊断与修复
内存泄漏是指程序在申请内存后,未能释放已不再使用的内存,导致内存占用持续增加。虽然Python的垃圾回收器可以自动管理大部分内存,但不当的编程习惯可能会导致内存泄漏。
### 4.1.1 内存泄漏常见原因分析
内存泄漏的一个常见原因是循环引用,即两个或更多的对象相互引用,形成了一个闭环,导致它们都不能被垃圾回收器回收。例如,如果一个列表包含了一个指向自身的字典,而这个字典又通过一个键值对指向这个列表,那么这两个对象就形成了循环引用。
另一个常见的内存泄漏来源是全局变量。全局变量没有固定的生命周期,如果程序持续运行,它们占用的内存也可能不断增加。
开发者也可能在不自觉中创建了缓存,随着时间的积累,这些缓存可能占用大量内存。此外,打开文件或数据库连接后忘记关闭,也会导致内存泄漏。
### 4.1.2 使用gc模块进行内存监控
Python的`gc`模块提供了与垃圾收集器相关的接口。通过使用这个模块,开发者可以监控和诊断内存泄漏。
示例代码展示了如何使用`gc`模块:
```python
import gc
# 开启垃圾收集器的调试模式
gc.set_debug(gc.DEBUG_LEAK)
# 创建一些对象
for i in range(10):
a = [i]
b = [a] * 10000
# 强制进行垃圾收集
gc.collect()
# 检查垃圾收集器的日志
for record in gc.garbage:
print("Uncollectable object found:", record)
```
在这个示例中,`set_debug`函数将垃圾收集器设置为调试模式,这样当无法回收的对象出现时,解释器会打印相关的信息。随后,代码尝试创建一个潜在的内存泄漏场景,并强制执行垃圾收集来诊断问题。
## 4.2 内存优化技巧
为了提升程序的性能,开发者通常会尝试各种内存优化技巧,以减少内存的使用并提高内存的分配和回收效率。
### 4.2.1 对象池模式的应用
对象池模式是指预先创建一批对象以供重复使用,这样可以避免频繁的内存分配和回收操作,从而减少内存碎片和提高程序的性能。
Python标准库中的`queue.Queue`类就实现了对象池模式,其内部使用一个列表来保存对象,当对象被从队列中移除时,并不会立即销毁,而是返回到列表中供下一次使用。
如果需要手动实现对象池,可以参考以下代码:
```python
class ObjectPool:
def __init__(self, object_func):
self._object_func = object_func
self._pool = []
def get(self):
if self._pool:
return self._pool.pop()
return self._object_func()
def put(self, obj):
self._pool.append(obj)
def __len__(self):
return len(self._pool)
# 使用对象池获取和回收对象
def create_obj():
return [0] * 1000
pool = ObjectPool(create_obj)
obj = pool.get() # 从池中获取对象
pool.put(obj) # 用完后将对象返回池中
```
在上述代码中,`ObjectPool`类接受一个函数`object_func`,该函数负责创建对象。当调用`get()`方法时,对象池会尝试从其内部列表中返回一个可用对象,如果没有可用对象,则调用传入的函数创建一个新对象。当对象不再需要时,可以通过`put()`方法将其返回到池中。
### 4.2.2 使用__slots__节省内存
Python允许在类中使用`__slots__`属性来声明实例变量,这样做的好处是可以减少实例对象所占用的内存。当使用`__slots__`时,Python不会为每个实例创建一个`__dict__`字典,而是为每个实例变量分配一个固定的空间。
下面的代码展示了如何使用`__slots__`:
```python
class Point:
__slots__ = ('x', 'y') # 为x和y变量分配空间
def __init__(self, x, y):
self.x = x
self.y = y
# 使用__slots__后内存节省效果
point_with_slots = Point(10, 20)
print(point_with_slots.__dict__) # 这里不会显示字典
# 对比没有使用__slots__的普通类
class PointNoSlots:
def __init__(self, x, y):
self.x = x
self.y = y
point_no_slots = PointNoSlots(10, 20)
print(point_no_slots.__dict__)
```
在这个例子中,`Point`类使用了`__slots__`属性来声明实例变量`x`和`y`。当创建`Point`类的实例时,实例不会拥有一个`__dict__`属性,而是直接存储`x`和`y`变量的值。而`PointNoSlots`类则没有使用`__slots__`,它为每个实例创建了一个`__dict__`字典来存储实例变量。
通过这种方式,`__slots__`为内存使用提供了一种优化手段,尤其对于那些拥有大量实例且实例变量不多的类来说非常有用。
在本章节中,我们探讨了Python内存管理的相关知识,深入分析了内存泄漏的常见原因,并演示了如何使用`gc`模块来监控内存泄漏。此外,我们还分享了对象池模式的实现示例和通过`__slots__`减少内存使用的技巧。掌握这些知识和技能,对于编写高效且稳定的Python代码来说至关重要。
# 5. 多线程与多进程编程
## 5.1 多线程编程的正确打开方式
### 5.1.1 GIL的误解和事实
全局解释器锁(GIL)是Python语言中的一个机制,它存在于CPython解释器中,是导致Python多线程编程困难的主要原因之一。由于GIL的存在,同一时刻只有一个线程能够执行Python字节码。因此,对于计算密集型任务,多线程并不能发挥其应有的优势,有时甚至会因为线程调度开销而导致性能下降。不过,对于I/O密集型任务,多线程能够通过释放GIL来让其他线程执行,从而提高整体程序的并发性能。
很多人认为GIL阻止了多核CPU的充分利用,这其实是一种误解。GIL并不阻止Python程序在多核上运行,因为在多核环境中,每个核心上运行的Python解释器可以有自己的GIL。为了利用多核,我们通常使用多进程(如5.2节所述),而不是多线程。
### 5.1.2 使用threading模块提高并发
尽管存在GIL,Python的threading模块仍然在很多场景下非常有用,特别是当涉及到I/O操作时。Python的I/O操作(如文件读写、网络通信)会阻塞当前线程,释放GIL,允许其他线程运行。这时使用多线程可以显著提升程序的效率。
下面是一个使用`threading`模块的简单例子:
```python
import threading
import time
def thread_function(name):
print(f'Thread {name}: starting')
time.sleep(2)
print(f'Thread {name}: finishing')
if __name__ == "__main__":
print("Main : before creating thread")
x = threading.Thread(target=thread_function, args=(1,))
print("Main : before running thread")
x.start()
x.join()
print("Main : thread finished")
```
在这个例子中,我们创建并启动了一个线程,它执行`thread_function`函数。使用`start()`方法启动线程,然后调用`join()`等待线程完成。这个简单的程序展示了线程的创建和运行过程。
线程间的协作和数据共享是多线程编程中需要关注的问题。应避免使用全局变量和不恰当的线程同步机制,如锁、信号量等,因为它们可能导致死锁和竞态条件。在实际应用中,通过合理设计,确保线程之间安全高效地交换信息,是非常重要的。
## 5.2 多进程编程的优势
### 5.2.1 使用multiprocessing实现并行计算
与多线程不同,Python的`multiprocessing`模块能够绕过GIL限制,允许程序在多核处理器上实现真正的并行计算。这个模块通过在多个进程之间共享数据,来实现并行运行,每个进程都有自己的Python解释器和内存空间,因此不受GIL的限制。
下面是一个使用`multiprocessing`模块进行并行计算的简单例子:
```python
from multiprocessing import Process
import os
def info(title):
print(title)
print(f'module name: {__name__}')
print(f'process id: {os.getpid()}')
def f(name):
info('function f')
print(f'hello {name}')
if __name__ == '__main__':
info('main line')
p = Process(target=f, args=('bob',))
p.start()
p.join()
```
这个例子展示了如何创建一个进程,并执行一个函数。每个进程都运行在独立的Python解释器中,互不干扰。程序中的`info`函数输出了模块名称和进程ID,可以观察到不同进程有不同的解释器实例和进程ID。
### 5.2.2 进程间通信IPC机制
多进程间通信(IPC)是多进程编程的一个重要方面。Python的`multiprocessing`模块提供了多种机制来进行进程间通信,如`Pipe()`和`Queue()`。
- Pipe():创建一个管道,允许两个进程之间双向通信。
- Queue():创建一个队列,允许多个进程之间共享数据,支持先进先出(FIFO)。
下面是一个使用`Queue()`的例子:
```python
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()
```
在这个例子中,我们创建了一个队列和一个进程,子进程将数据放入队列中,主进程从中取数据。进程间通信是多进程程序的核心,正确的使用IPC机制对于构建稳定高效的多进程应用至关重要。
使用`multiprocessing`模块时,每个进程都需要独立的内存空间,所以在创建大量进程时要考虑到内存和资源的限制。合理规划进程数量,以及通过进程池来限制并发进程数,是优化多进程程序性能的一个重要策略。
# 6. 外部库和C扩展的使用
## 6.1 选择合适的外部库
在Python中,外部库可以提供额外的功能和性能提升。库的选择不仅取决于所需的功能,还取决于性能要求。Python社区中一些最流行的科学计算库包括NumPy和SciPy,它们在处理大量数据时表现出色。
### 6.1.1 NumPy和SciPy在科学计算中的应用
NumPy库提供了高性能的多维数组对象和工具集,这些工具集用于对数组进行操作。SciPy则在此基础上,提供了许多科学计算中常用的算法。使用NumPy和SciPy可以提高科学计算的性能,因为它们使用了C和Fortran编写的高效代码。
```python
import numpy as np
from scipy import stats
# 使用NumPy创建数组
data = np.array([1.0, 2.0, 3.0, 4.0, 5.0])
# 使用SciPy计算数据的统计信息
mean = stats.describe(data).mean
```
上述代码示例展示了如何使用NumPy创建一个数组,并使用SciPy库中的描述性统计函数来计算平均值。
### 6.1.2 Cython和CFFI在性能提升中的作用
当需要对性能要求极高的部分代码进行优化时,可以考虑使用Cython将Python代码编译成C代码,或者使用CFFI调用现有的C库。这些方法可以大大提升性能,因为它们绕过了Python解释器的开销。
```python
# 使用Cython编译的代码片段
cimport cython
import numpy as np
@cython.boundscheck(False)
@cython.wraparound(False)
def dot_product(double[:] x, double[:] y):
cdef int i, n = x.shape[0]
cdef double result = 0.0
for i in range(n):
result += x[i] * y[i]
return result
```
上例展示了如何用Cython编译一个计算向量点积的函数,这个过程能带来显著的性能提升。
## 6.2 C语言扩展的编写与集成
Python与C语言的集成通常可以带来性能上的显著提升,尤其是在CPU密集型任务中。通过编写C扩展模块,可以为Python带来C语言的效率。
### 6.2.1 创建C扩展模块的基本步骤
创建C扩展模块主要涉及到使用Python的C API,这需要一定的C语言知识。以下是创建C扩展模块的基本步骤:
1. 包含Python头文件并初始化Python解释器。
2. 编写C函数并暴露给Python。
3. 构建C扩展模块。
4. 在Python中导入并使用C扩展模块。
示例代码:
```c
// example.c
#include <Python.h>
static PyObject* add(PyObject* self, PyObject* args) {
int a, b;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
return NULL;
}
return Py_BuildValue("i", a + b);
}
static PyMethodDef ExampleMethods[] = {
{"add", add, METH_VARARGS, "Add two numbers"},
{NULL, NULL, 0, NULL}
};
static struct PyModuleDef examplemodule = {
PyModuleDef_HEAD_INIT,
"example", /* name of module */
NULL, /* module documentation, may be NULL */
-1, /* size of per-interpreter state of the module,
or -1 if the module keeps state in global variables. */
ExampleMethods
};
PyMODINIT_FUNC PyInit_example(void) {
return PyModule_Create(&examplemodule);
}
```
### 6.2.2 利用ctypes和cffi调用外部C代码
在不需要编写C代码的情况下,可以使用ctypes或cffi库来调用现有的C库。这些库通过提供一个Python接口来调用C语言的函数,可以很轻松地集成现有的C代码。
使用ctypes示例:
```python
from ctypes import cdll
# 加载C动态链接库
lib = cdll.LoadLibrary('path/to/library.so')
# 调用C库中的函数
result = lib.add(1, 2)
```
使用cffi示例:
```python
from cffi import FFI
ffi = FFI()
# 声明C函数
ffi.cdef("int add(int a, int b);")
# 加载C动态链接库
lib = ffi.dlopen('path/to/library.so')
# 调用C库中的函数
result = lib.add(1, 2)
```
以上步骤展示了如何使用ctypes和cffi来调用C语言编写的函数,而无需创建C扩展。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 算法优化的各个方面,从基础技巧到高级策略。它提供了全面的指南,帮助开发者提升 Python 代码的效率和性能。专栏涵盖了内存管理、循环优化、数据结构选择、并发编程、缓存机制、算法调试、函数式编程、时间复杂度分析、动态规划、贪心算法、分治算法、回溯算法、排序和搜索算法等主题。通过实战案例研究和实用技巧,本专栏旨在帮助开发者掌握 Python 算法优化技术,从而创建更快速、更有效的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
【S参数转换表准确性】:实验验证与误差分析深度揭秘

# 摘要
本文详细探讨了S参数转换表的准确性问题,首先介绍了S参数的基本概念及其在射频领域的应用,然后通过实验验证了S参数转换表的准确性,并分析了可能的误差来源,包括系统误差和随机误差。为了减小误差,本文提出了一系列的硬件优化措施和软件算法改进策略。最后,本文展望了S参数测量技术的新进展和未来的研究方向,指出了理论研究和实际应用创新的重要性。
# 关键字
S参
【TongWeb7内存管理教程】:避免内存泄漏与优化技巧
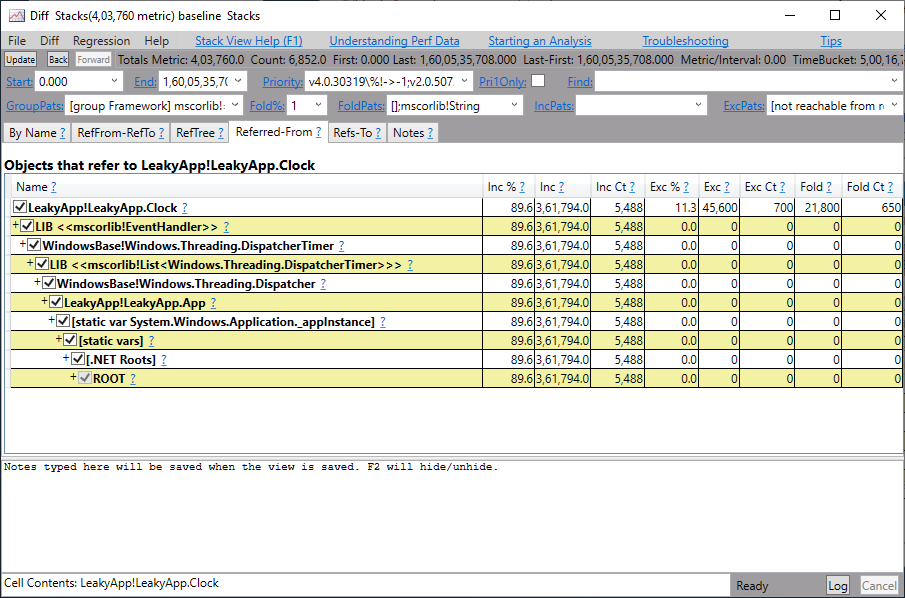
# 摘要
本文旨在深入探讨TongWeb7的内存管理机制,重点关注内存泄漏的理论基础、识别、诊断以及预防措施。通过详细阐述内存池管理、对象生命周期、分配释放策略和内存压缩回收技术,文章为提升内存使用效率和性能优化提供了实用的技术细节。此外,本文还介绍了一些性能优化的基本原则和监控分析工具的应用,以及探讨了企业级内存管理策略、自动内存管理工具和未来内存管理技术的发展趋
无线定位算法优化实战:提升速度与准确率的5大策略
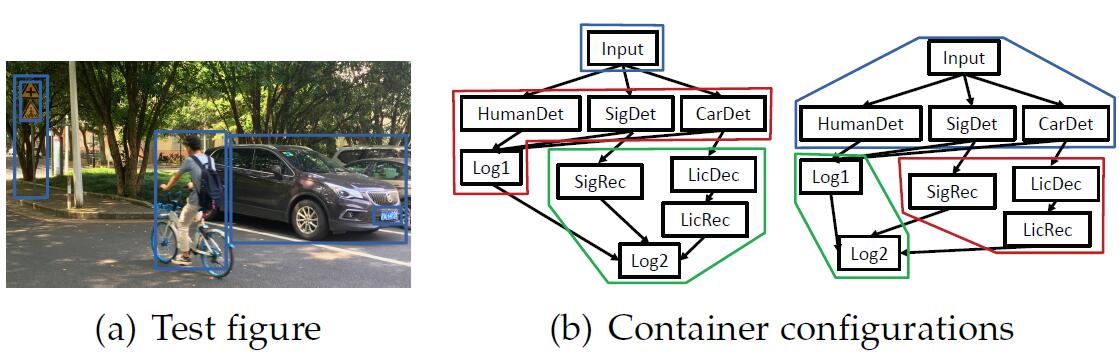
# 摘要
本文综述了无线定位技术的原理、常用算法及其优化策略,并通过实际案例分析展示了定位系统的实施与优化。第一章为无线定位技术概述,介绍了无线定位技术的基础知识。第二章详细探讨了无线定位算法的分类、原理和常用算法,包括距离测量技术和具体定位算法如三角测量法、指纹定位法和卫星定位技术。第三章着重于提升定位准确率、加速定位速度和节省资源消耗的优化策略。第四章通过分析室内导航系统和物联网设备跟踪的实际应用场景,说明了定位系统优化实施
成本效益深度分析:ODU flex-G.7044网络投资回报率优化
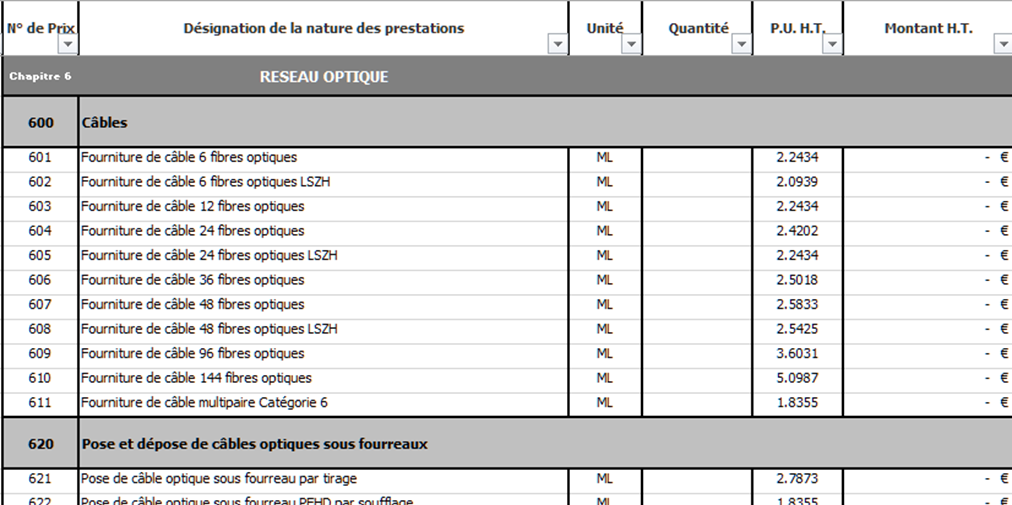
# 摘要
本文旨在介绍ODU flex-G.7044网络技术及其成本效益分析。首先,概述了ODU flex-G.7044网络的基础架构和技术特点。随后,深入探讨成本效益理论,包括成本效益分析的基本概念、应用场景和局限性,以及投资回报率的计算与评估。在此基础上,对ODU flex-G.7044网络的成本效益进行了具体分析,考虑了直接成本、间接成本、潜在效益以及长期影响。接着,提出优化投资回报
【Delphi编程智慧】:进度条与异步操作的完美协调之道

# 摘要
本文旨在深入探讨Delphi编程环境中进度条的使用及其与异步操作的结合。首先,基础章节解释了进度条的工作原理和基础应用。随后,深入研究了Delphi中的异步编程机制,包括线程和任务管理、同步与异步操作的原理及异常处理。第三章结合实
C语言编程:构建高效的字符串处理函数
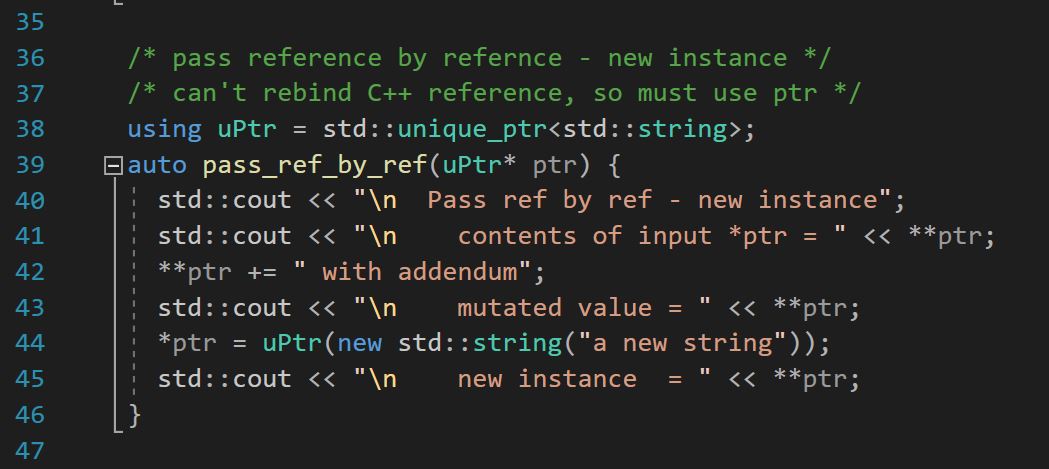
# 摘要
字符串处理是编程中不可或缺的基础技能,尤其在C语言中,正确的字符串管理对程序的稳定性和效率至关重要。本文从基础概念出发,详细介绍了C语言中字符串的定义、存储、常用操作函数以及内存管理的基本知识。在此基础上,进一步探讨了高级字符串处理技术,包括格式化字符串、算法优化和正则表达式的应用。
【抗干扰策略】:这些方法能极大提高PID控制系统的鲁棒性
# 摘要
PID控制系统作为一种广泛应用于工业过程控制的经典反馈控制策略,其理论基础、设计步骤、抗干扰技术和实践应用一直是控制工程领域的研究热点。本文从PID控制器的工作原理出发,系统介绍了比例(P)、积分(I)、微分(D)控制的作用,并探讨了系统建模、控制器参数整定及系统稳定性的分析方法。文章进一步分析了抗干扰技术,并通过案例分析展示了PID控制在工业温度和流量控制系统中的优化与仿真。最后,文章展望了PID控制系统的高级扩展,如
业务连续性的守护者:中控BS架构考勤系统的灾难恢复计划

# 摘要
本文旨在探讨中控BS架构考勤系统的业务连续性管理,概述了业务连续性的重要性及其灾难恢复策略的制定。首先介绍了业务连续性的基础概念,并对其在企业中的重要性进行了详细解析。随后,文章深入分析了灾难恢复计划的组成要素、风险评估与影响分析方法。重点阐述了中控BS架构在硬件冗余设计、数据备份与恢复机制以及应急响应等方面的策略。
自定义环形菜单

# 摘要
本文探讨了环形菜单的设计理念、理论基础、开发实践、测试优化以及创新应用。首先介绍了环形菜单的设计价值及其在用户交互中的应用。接着,阐述了环形菜单的数学基础、用户交互理论和设计原则,为深入理解环形菜单提供了坚实的理论支持。随后,文章详细描述了环形菜单的软件实现框架、核心功能编码以及界面与视觉设计的开发实践。针对功能测试和性能优化,本文讨论了测试方法和优化策略,确保环形菜单的可用性和高效性。最后,展望了环形菜单在新兴领域的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )