【MapReduce安全指南】:掌握保障数据处理安全性的关键步骤
发布时间: 2024-10-30 12:45:05 阅读量: 5 订阅数: 10 

# 1. MapReduce概述与安全挑战
MapReduce是一种为大数据处理设计的编程模型和处理框架,广泛应用于搜索引擎索引、数据统计等场景。尽管其在处理大规模数据集时表现出色,但数据安全和隐私保护却日益成为其面临的主要挑战之一。
随着企业数据资产价值的提高,MapReduce作业在执行过程中潜在的安全漏洞可能被利用,导致数据泄露或未授权访问。例如,未加密的数据在网络中传输、存储过程中的不当处理都可能引发安全问题。在处理敏感数据时,如何确保数据在MapReduce作业过程中的安全,是每个开发者和系统管理员都必须面对的问题。
因此,本章节将对MapReduce框架中涉及的安全问题进行概述,为后续章节中将详细讨论的加密技术、身份验证与授权管理、数据安全操作指南以及安全监控与审计等话题打下基础。这将帮助读者构建起MapReduce安全知识的全面框架,为设计和维护安全的MapReduce应用提供参考。
# 2. 数据加密技术在MapReduce中的应用
## 2.1 加密技术基础
### 2.1.1 对称加密与非对称加密原理
对称加密和非对称加密是数据加密领域中的两大基石。对称加密算法使用相同的密钥来加密和解密数据,这意味着密钥必须在加密和解密双方之间安全共享。其优点在于加密和解密过程非常快速,适合大量数据的处理。常见的对称加密算法包括AES(高级加密标准)、DES(数据加密标准)等。
对称加密的挑战在于密钥的分发和管理,任何拥有密钥的人都可以解密数据,这就使得密钥的保护变得至关重要。相比之下,非对称加密使用一对密钥,一个公开的公钥用于加密数据,另一个私有的私钥用于解密数据。因为非对称加密的密钥分发问题较为简单,它在互联网上得到了广泛的应用,比如RSA和ECC(椭圆曲线密码学)算法。
### 2.1.2 哈希函数和数字签名的作用
哈希函数是将任意长度的输入通过散列算法转换成固定长度输出的函数,它具有单向性和抗冲突性,意味着从哈希值难以反推原始输入,并且两个不同的输入几乎不可能得到相同的哈希值。常见的哈希算法有MD5、SHA-1和SHA-256等。
数字签名是一种电子签名的形式,它使用非对称加密技术来验证消息的完整性和来源。发送者用自己的私钥生成签名,接收者则用发送者的公钥来验证签名的有效性。数字签名保证了信息传输过程的不可抵赖性,并帮助确保数据在传输过程中未被篡改。
## 2.2 MapReduce数据加密实践
### 2.2.1 加密算法在MapReduce中的集成方法
在MapReduce框架中集成加密算法,首先需要对Hadoop的加密插件进行配置,然后在Map和Reduce任务中明确使用哪些加密算法。通常的做法是在数据进入系统前先进行加密,在Map和Reduce任务处理时,再对数据进行解密。当然,加密操作也可以根据需要延迟到数据写入存储系统之前。
在Hadoop环境中,可以使用Kerberos协议来保护集群通信,并结合数据加密算法确保数据在存储和传输过程中的安全。例如,使用AES加密算法来保护HDFS中的数据块。对于流数据处理,则可以集成SSL/TLS来为客户端和服务器之间的数据传输提供加密保护。
### 2.2.2 密钥管理与分发策略
密钥管理在加密过程中至关重要,特别是在大规模分布式系统中。一个良好的密钥管理策略应确保密钥的安全生成、存储、分发、轮换以及废除。在MapReduce框架中,密钥管理系统需要与Hadoop集群的认证机制相集成,确保只有授权的用户和应用程序可以访问密钥。
密钥分发可以通过密钥管理服务(如AWS KMS、HashiCorp Vault等)来实现。通过这样的服务,MapReduce作业可以请求所需的密钥进行加密操作,并在作业完成后安全地废弃密钥。密钥分发策略应包括对密钥请求的严格控制、密钥使用记录以及密钥生命周期的管理。
### 2.2.3 加密数据处理流程和性能优化
加密数据处理流程需在MapReduce作业的设计阶段就开始考虑。数据在输入时加密,处理过程中保持加密状态,只有在实际需要使用数据时才解密。为了提高处理效率,可以考虑在数据传输阶段使用压缩技术来减少I/O负载。同时,应尽量减少解密操作的次数,通过优化MapReduce作业来实现这一目标。
对于性能优化,可以采取如下策略:
1. 使用高效的加密算法和硬件加速器来提升加密和解密速度。
2. 通过数据本地性优化,减少数据在网络中的传输。
3. 对加密操作进行并行处理,利用MapReduce的分布式计算能力。
4. 使用缓存和预取技术来减少I/O瓶颈。
5. 在不损害数据安全的前提下,对数据进行批处理,以减少加密操作的开销。
此外,合理调整MapReduce作业的配置参数,如设置合适的内存和CPU资源,也能够有效提升处理加密数据的性能。
代码块示例和参数说明:
```java
// 示例代码:AES加密和解密数据
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SecretKey;
import java.security.SecureRandom;
public class AesEncryption {
// 加密方法
public static byte[] encrypt(byte[] data, SecretKey key) throws Exception {
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, key, new SecureRandom());
return cipher.doFinal(data);
}
// 解密方法
public static byte[] decrypt(byte[] cipherText, SecretKey key) throws Exception {
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
cipher.init(Cipher.DECRYPT_MODE, key, new SecureRandom());
return cipher.doFinal(cipherText);
}
// 主函数中演示密钥生成
public static void main(String[] args) throws Exception {
KeyGenerator keyGen = KeyGenerator.getInstance("AES");
keyGen.init(128); // AES-128
SecretKey secretKey = keyGen.generateKey();
// 应用密钥进行加密
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【HDFS安全升级】:datanode安全特性的增强与应用
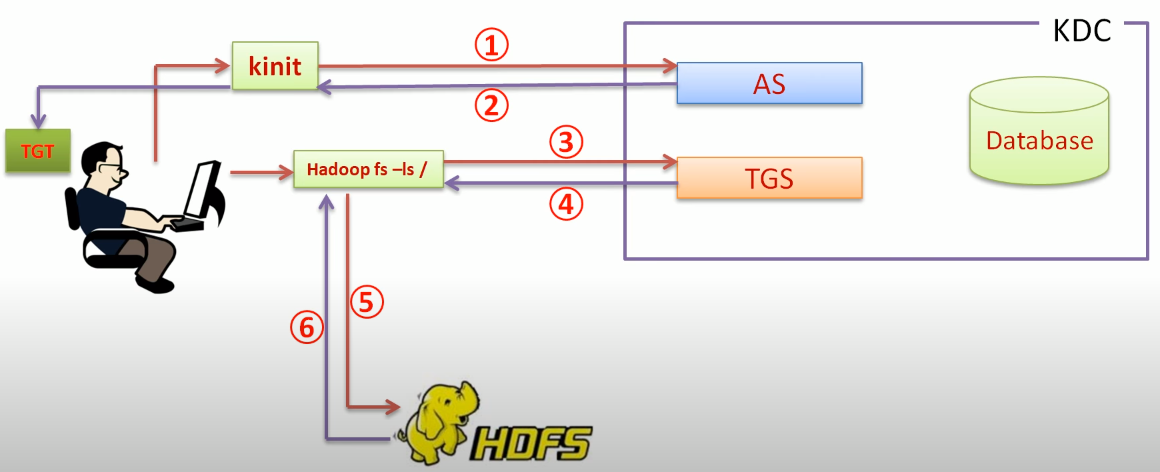
# 1. HDFS的安全性概述
在当今信息化快速发展的时代,数据的安全性已成为企业和组织所关注的核心议题之一。Hadoop分布式文件系统(HDFS)作为大数据存储的关键组件,其安全性备受重视。本章将概览HDFS的安全性问题,为读者揭示在分布式存储领域中,如何确保数据的机密性、完整性和可用性。
首先,我们探讨HDFS面临的安全威胁,包括数据泄露、未授权访问和恶意攻击等问题。其次,我们会
Hadoop数据上传与查询的高级策略:网络配置与性能调整全解析

# 1. Hadoop分布式存储概述
Hadoop分布式存储是支撑大数据处理的核心组件之一,它基于HDFS(Hadoop Distributed File System)构建,以提供高度可伸缩、容错和高吞吐量的数据存储解决方案。HDFS采用了主/从架构,由一个NameNode(主节点)和多个DataNode(数据节点)构成。NameNode负责管理文件系统的命名空间和客户端对文件的访问,而Data
【MapReduce性能调优】:专家级参数调优,性能提升不是梦
# 1. MapReduce基础与性能挑战
MapReduce是一种用于大规模数据处理的编程模型,它的设计理念使得开发者可以轻松地处理TB级别的数据集。在本章中,我们将探讨MapReduce的基本概念,并分析在实施MapReduce时面临的性能挑战。
## 1.1 MapReduce简介
MapReduce由Google提出,并被Apache Hadoop框架所采纳,它的核心是将复杂的、海量数据的计算过程分解为两个阶段:Map(映射)和Reduce(归约)。这个模型使得分布式计算变得透明,用户无需关注数据在集群上的分布和节点间的通信细节。
## 1.2 MapReduce的工作原理
系统不停机的秘诀:Hadoop NameNode容错机制深入剖析
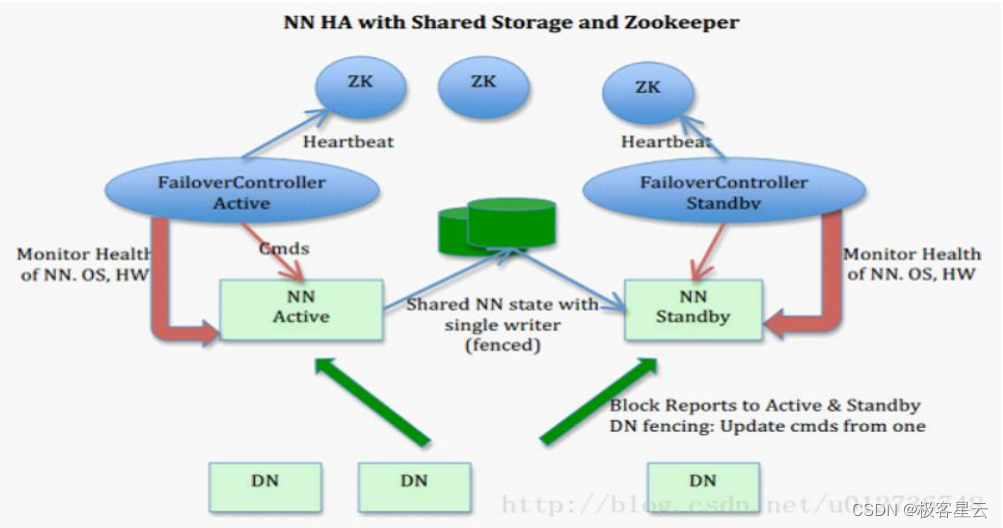
# 1. Hadoop NameNode容错机制概述
在分布式存储系统中,容错能力是至关重要的特性。在Hadoop的分布式文件系统(HDFS)中,NameNode节点作为元数据管理的中心点,其稳定性直接影响整个集群的服务可用性。为了保障服务的连续性,Hadoop设计了一套复杂的容错机制,以应对硬件故障、网络中断等潜在问题。本章将对Hadoop NameNode的容错机制进行概述,为理解其细节
【排序阶段】:剖析MapReduce Shuffle的数据处理优化(大数据效率提升专家攻略)

# 1. MapReduce Shuffle概述
MapReduce Shuffle是大数据处理框架Hadoop中的核心机制之一,其作用是将Map阶段产生的中间数据进行排序、分区和传输,以便于Reduce阶段高效地进行数据处理。这一过程涉及到大量的数据读写和网络传输,是影响MapReduce作业性能的关键
深入MapReduce:全面剖析数据处理流程
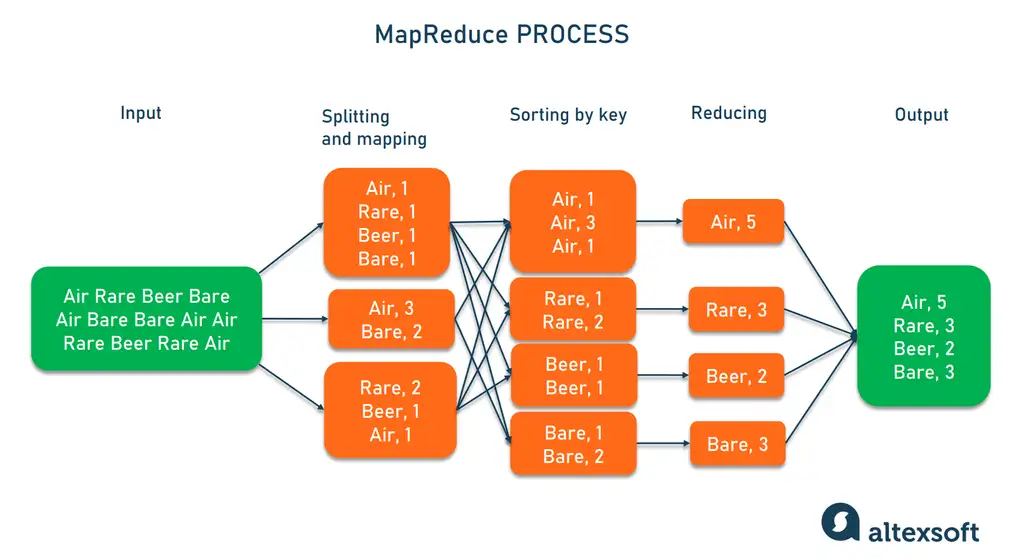
# 1. MapReduce概念与基本原理
MapReduce是一种编程模型,用于大规模数据集的并行运算。它由Google提出,并成为Hadoop等大数据处理框架的核心组件。基本原理是通过分而治之的方式将任务分为Map(映射)和Reduce(归约)两个阶段来处理。Map阶段处理数据并生成键值对(key-value pairs),而Reduce阶段则对具有相
数据完整性校验:Hadoop NameNode文件系统检查的全面流程
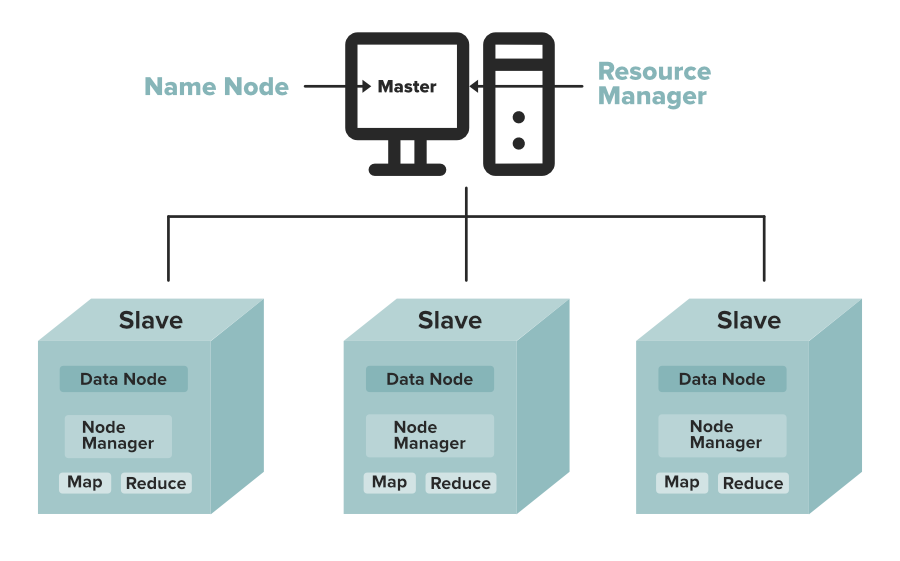
# 1. Hadoop NameNode数据完整性概述
Hadoop作为一个流行的开源大数据处理框架,其核心组件NameNode负责管理文件系统的命名空间以及维护集群中数据块的映射。数据完整性是Hadoop稳定运行的基础,确保数据在存储和处理过程中的准确性与一致性。
在本章节中,我们将对Hadoop NameNode的数据完
MapReduce在云计算与日志分析中的应用:优势最大化与挑战应对
# 1. MapReduce简介及云计算背景
在信息技术领域,云计算已经成为推动大数据革命的核心力量,而MapReduce作为一种能够处理大规模数据集的编程模型,已成为云计算中的关键技术之一。MapReduce的设计思想源于函数式编程中的map和reduce操作,它允许开发者编写简洁的代码,自动并行处理分布在多台机器上的大量数据。
云计算提供了一种便捷的资源共享模式,让数据的存储和计算不再受物理硬件的限制,而是通过网络连接实现资源的按需分配。通过这种方式,MapReduce能够利用云计算的弹性特性,实现高效的数据处理和分析。
本章将首先介绍MapReduce的基本概念和云计算背景,随后探
数据同步的守护者:HDFS DataNode与NameNode通信机制解析
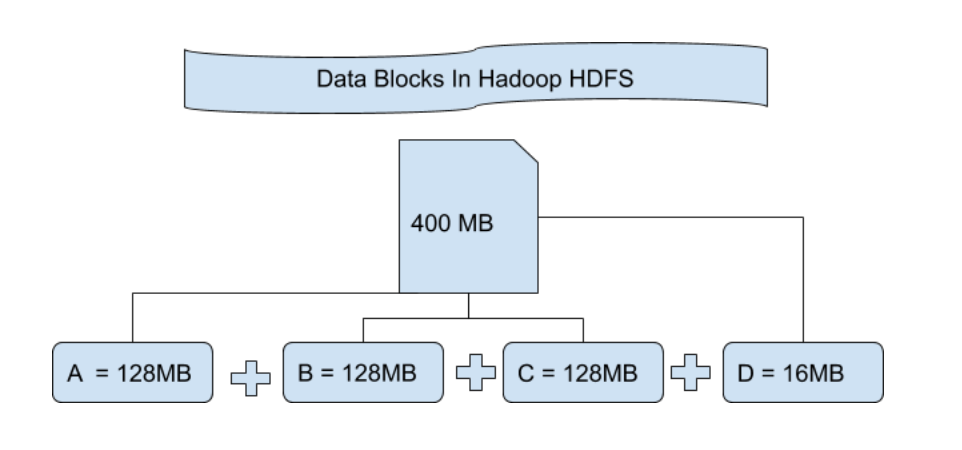
# 1. HDFS架构与组件概览
## HDFS基本概念
Hadoop分布式文件系统(HDFS)是Hadoop的核心组件之一,旨在存储大量数据并提供高吞吐量访问。它设计用来运行在普通的硬件上,并且能够提供容错能力。
## HDFS架构组件
- **NameNode**: 是HDFS的主服务器,负责管理文件系统的命名空间以及客户端对文件的访问。它记录了文
【MapReduce优化工具】:使用高级工具与技巧,提高处理速度与数据质量
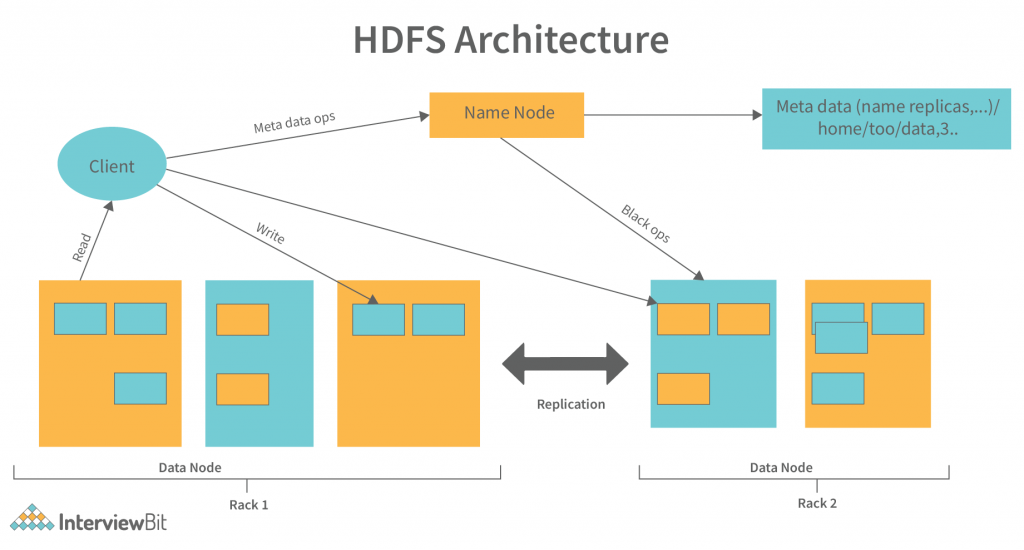
# 1. MapReduce优化工具概述
MapReduce是大数据处理领域的一个关键框架,随着大数据量的增长,优化MapReduce作业以提升效率和资源利用率已成为一项重要任务。本章节将引入MapReduce优化工具的概念,涵盖各种改进MapReduce执行性能和资源管理的工具与策略。这不仅包括Hadoop生态内的工具,也包括一些自定义开发的解决方案,旨在帮助
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )