疾病预测:监督学习算法的对比分析
需积分: 10 42 浏览量
更新于2024-07-09
收藏 1.79MB PDF 举报
"这篇研究文章比较了不同的监督机器学习算法在疾病预测中的应用,通过广泛的研究,选取了48篇文章进行分析,其中支持向量机(SVM)被最常应用,其次是朴素贝叶斯算法。"
正文:
疾病预测是医疗健康领域的重要课题,随着大数据和人工智能技术的发展,监督机器学习算法已成为挖掘健康数据、预测疾病风险的有效工具。监督学习是一种机器学习的方法,它依赖于已标记的数据来训练模型,从而对未知数据进行预测。在本研究中,作者深入探讨了不同类型的监督学习算法在疾病预测中的关键趋势、性能和使用情况。
首先,支持向量机(SVM)算法在疾病预测中占据了主导地位,被29项研究采用。SVM是一种强大的分类和回归算法,其核心思想是找到一个最优超平面,将不同类别的数据最大程度地分开。在疾病预测中,SVM可以有效地处理高维特征空间,尤其在小样本数据集上表现优秀,这可能是它被广泛使用的原因。
其次,朴素贝叶斯算法在23项研究中被应用。朴素贝叶斯基于概率理论,假设各特征之间相互独立,虽然这种假设在实际问题中可能过于简化,但在许多情况下,尤其是文本分类和疾病诊断中,它仍然表现出良好的性能,而且算法实现简单,计算效率高。
此外,其他监督学习算法如决策树、随机森林、逻辑回归、K近邻(K-NN)、神经网络等也在疾病预测中发挥了作用。例如,决策树和随机森林通过构建一系列规则来划分数据,易于理解和解释;逻辑回归适用于二元分类问题,能够量化疾病发生的概率;K-NN基于实例学习,对于新数据的分类依赖于其最近的邻居;神经网络则通过多层非线性变换,能捕获复杂的数据模式,特别适合处理大规模特征和高维数据。
研究发现,每种算法都有其优缺点和适用场景。选择哪种算法通常取决于数据的特性、预测任务的复杂度以及计算资源。例如,对于特征关联性强且数据量大的问题,神经网络可能更为合适;而对于特征独立且需要快速响应的结果,朴素贝叶斯可能更合适。
为了提高疾病预测的准确性,研究人员通常会采用集成学习方法,如AdaBoost、Bagging或Boosting,将多个模型的预测结果综合考虑,以达到提升整体性能的目的。同时,特征选择和特征工程也是优化模型性能的关键步骤,通过减少冗余特征、提取重要特征,可以降低模型过拟合的风险,提高泛化能力。
本文对48篇研究的分析揭示了监督学习算法在疾病预测中的广泛应用和多样性。未来的研究方向可能包括开发更适合医疗数据的新型算法,优化现有的模型,以及利用深度学习和迁移学习等先进技术进一步提升疾病预测的准确性和实用性。
outcomeforasmallchangeintheinputdata.They
are very s ensitive to their training data, which makes
them error-prone to the test dataset. The different
DTs of a n RF are trained using the different parts of
the training dataset. To classify a new sample, the
input vector of that sample is required to pass down
with each DT of the forest. Each DT then considers
a different part of that input vector and gives a clas-
sification outcome. The forest then chooses the clas-
sification of having the most ‘ votes’ (for discrete
classification outcome) or the average of all trees in
the forest (for numeric classification outcome). Since
the R F algorithm considers the outcomes from many
different DTs, it can reduce the variance resulted
from the consideration of a single DT for the same
dataset. Figure 4 shows an illustration of the RF
algorithm.
Naïve Bayes
Naïve Bayes (NB) is a classification technique based on
the Bayes’ theorem [27]. This theorem can describe the
probability of an event based on the prior knowledge of
conditions related to that event. This classifier assumes
that a particular feature in a class is not directly related
to any other feature although features for that class
could have interdependence among themselves [28]. By
considering the task of classifying a new object (white
circle) to ei ther ‘ green’ class or ‘ red’ class, Fig. 5 pro-
vides an illustration about how the NB technique
works. According to this figure, it is reasonable to be-
lieve that any new object is twice as likely to have
‘green’ membership rather than ‘ red’ since there are
twice as many ‘green’ objects (40) as ‘red’.Inthe
Bayesian analysis, this belief is known as the prior
probability. Therefore, the prior probabilities of
‘green’ and ‘red’ are 0.67 (40 ÷ 60) and 0.33 (20 ÷
60), respectively. Now to classify the ‘ white’ object,
we need to draw a circle around this object which
encompasses several points (to be chosen prior) irre-
spective of their class labels. Four points (three ‘red’
and one ‘green) were considered in this figure. Thus,
the likelihood of ‘ white’ given ‘green’ is 0.025 (1 ÷ 40)
and the likelihood of ‘ white’ given ‘ red’ is 0.15 (3 ÷
20). Although the prior probability indicates that the
new ‘white’ object is more likely to have ‘ green’ mem-
bership, the likelihood shows that it is more likely to
be in the ‘red’ class. In the Bay esian analysis, the final
classifier is produced by c ombining both sources of
information (i.e., prior probability and likelihood
value). The ‘
multiplication’ function is used to com-
bine these two types o f information and the product
is called the ‘posterior’ probability. Finally, the poster-
ior probability of ‘ white’ being ‘green’ is 0.017 (0.67 ×
0.025) a nd the posterior probability of ‘ white’ being
‘red’ is 0.049 (0.33 × 0.15). Thus, the new ‘white’ ob-
ject should be classified as a member of the ‘red’ class
according to the NB technique.
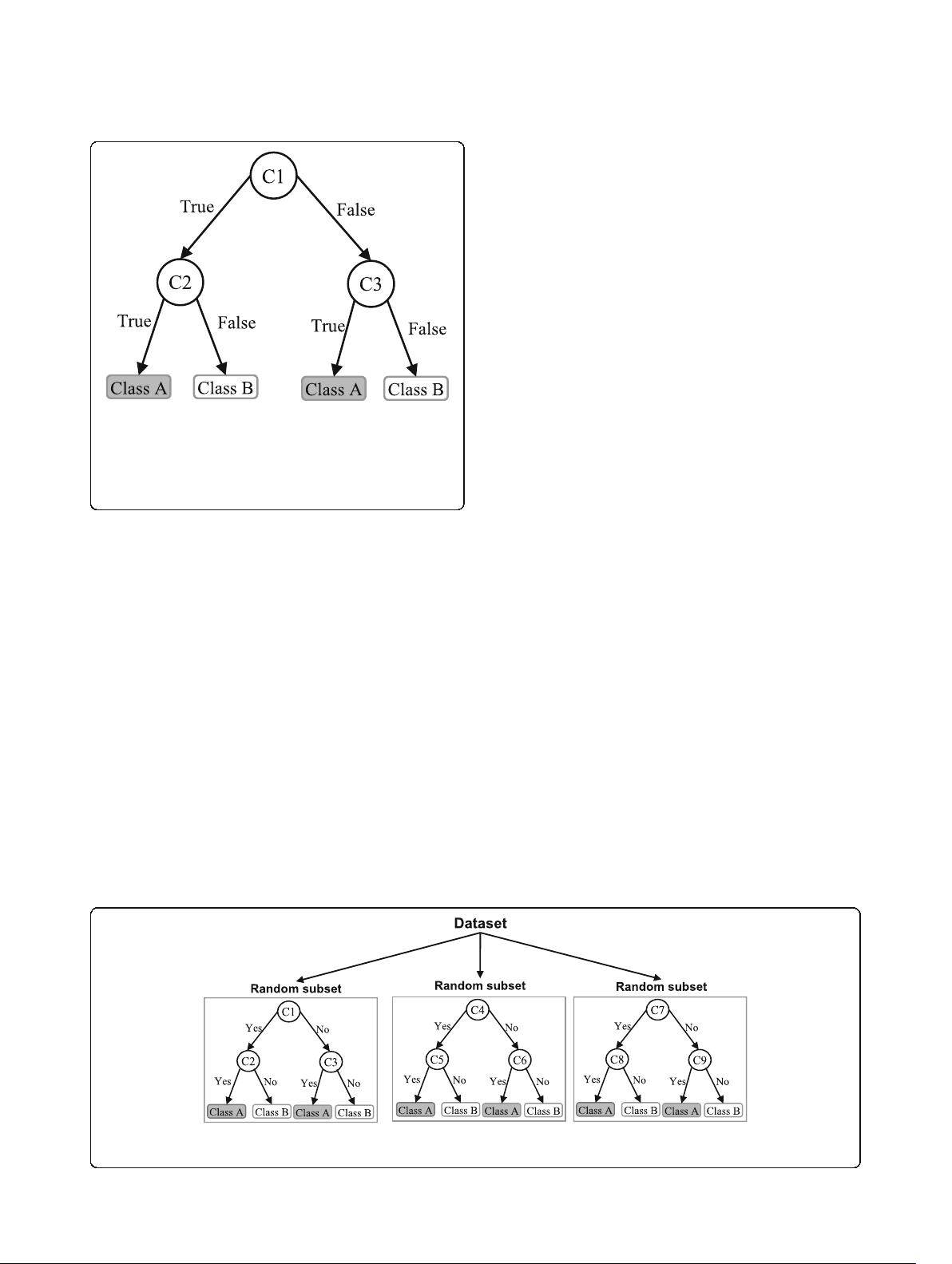
Fig. 3 An illustration of a Decision tree. Each variable (C1, C2, and
C3) is represented by a circle and the decision outcomes (Class A
and Class B) are shown by rectangles. In order to successfully classify
a sample to a class, each branch is labelled with either ‘True’ or
‘False’ based on the outcome value from the test of its
ancestor node
Fig. 4 An illustration of a Random forest which consists of three different decision trees. Each of those three decision trees was trained using a
random subset of the training data
Uddin et al. BMC Medical Informatics and Decision Making (2019) 19:281 Page 4 of 16
剩余15页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2025-03-06 上传

Data+Science+Insight
- 粉丝: 1w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Saber仿真下的简化Buck环路分析与TDsa扫频
- Spring框架下使用FreeMarker发邮件实例解析
- Cocos2d捕鱼达人路线编辑器开发指南
- 深入解析CSS Flex布局与特性的应用
- 小学生加减法题库自动生成软件介绍
- JS颜色选择器示例:跨浏览器兼容性
- ios-fingerprinter:自动化匹配iOS配置文件与.p12证书
- 掌握移动Web前端高效开发技术要点
- 解决VS中OpenGL程序缺失GL/glut.h文件问题
- 快速掌握POI技术,轻松编辑Excel文件
- 实用ASCII码转换工具:轻松实现数制转换与查询
- Oracle ODBC补丁解决数据源配置问题
- C#集成连接器的开发与应用
- 电子书制作教程:你的文档整理助手
- OpenStack计费监控:使用collectd插件收集统计信息
- 深入理解SQL Server 2008 Reporting Services
