Applications of Autocorrelation Function in Bioinformatics: Gene Expression and Disease Diagnosis
发布时间: 2024-09-15 18:03:24 阅读量: 34 订阅数: 32 

Influence of laser pulse on the autocorrelation function of H in a strong electric field
# 1. The Concept and Principle of Autocorrelation Function
The autocorrelation function (ACF) is a statistical tool used to measure the correlation between observations in a time series separated by specific time intervals. It is essentially a measure of self-similarity that can reveal the presence of periodicity, trends, or randomness within the data.
The calculation of ACF involves correlating the time series with shifted versions of itself at different time lags. Time lag refers to the interval between two observations. By calculating the correlation coefficients at all possible lags, we obtain an autocorrelation function that shows how correlation changes with the time lag.
The shape of the autocorrelation function can provide important information about the characteristics of the time series. For example, a strong positive correlation peak in the ACF indicates the presence of periodicity or trends in the data, while a rapidly decaying ACF suggests that the data is random.
# 2. The Application of Autocorrelation Function in Gene Expression Analysis
The autocorrelation function plays a crucial role in gene expression analysis as it can reveal the temporal correlation of gene expression patterns. By analyzing the autocorrelation of gene expression sequence data, researchers can identify patterns of gene expression, thus gaining insight into gene regulatory mechanisms and disease development.
### 2.1 Preprocessing of Gene Expression Sequence Data
Before applying the autocorrelation function for gene expression analysis, preprocessing of the raw sequence data is necessary to ensure data quality and comparability.
#### 2.1.1 Sequence Quality Control and Filtering
Sequence quality control and filtering are the first steps in preprocessing aimed at removing low-quality sequence reads. Low-quality sequence reads often contain errors or are missing, ***mon sequence quality control tools include FastQC and Trimmomatic.
#### 2.1.2 Data Normalization and Standardization
Data normalization and standardization are another important preprocessing step. Normalization brings sequence read counts from different samples to a common level, ***mon methods for normalization and standardization include RPKM (Reads Per Kilobase per Million mapped reads) and TPM (Transcripts Per Million).
### 2.2 Using Autocorrelation Function to Identify Gene Expression Patterns
The preprocessed gene expression sequence data can be used to calculate the autocorrelation function. The ACF measures the correlation between different time points within the sequence, thus revealing gene expression patterns.
#### 2.2.1 Calculation of Autocorrelation Coefficient
The autocorrelation coefficient is a quantitative measure of autocorrelation, calculated by the formula:
```
ρ(τ) = ∑(x_i - x̄)(x_{i+τ} - x̄) / ∑(x_i - x̄)^2
```
Where τ is the time interval, x_i is the value at the ith time point in the sequence, and x̄ is the mean of the sequence.
#### 2.2.2 Identification and Classification of Gene Expression Patterns
By calculating the autocorrelation coefficient, gene expression patterns can be identified. A positive autocorrelation coefficient indicates positive correlation between adjacent time points in the sequence, suggesting that gene expression has periodicity or trends. A negative autocorrelation coefficient indicates negative correlation between adjacent time points, suggesting that gene expression has anti-periodicity or randomness.
The autocorrelation function can also be used to classify gene expression patterns. For example, by comparing the autocorrelation functions of different genes, genes can be classified into categories such as periodically expressed genes, trend-expressed genes, randomly expressed genes, etc. Such classification aids in studying gene regulatory mechanisms and disease develop

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
GSM中TDMA调度挑战全解:技术细节与应对策略
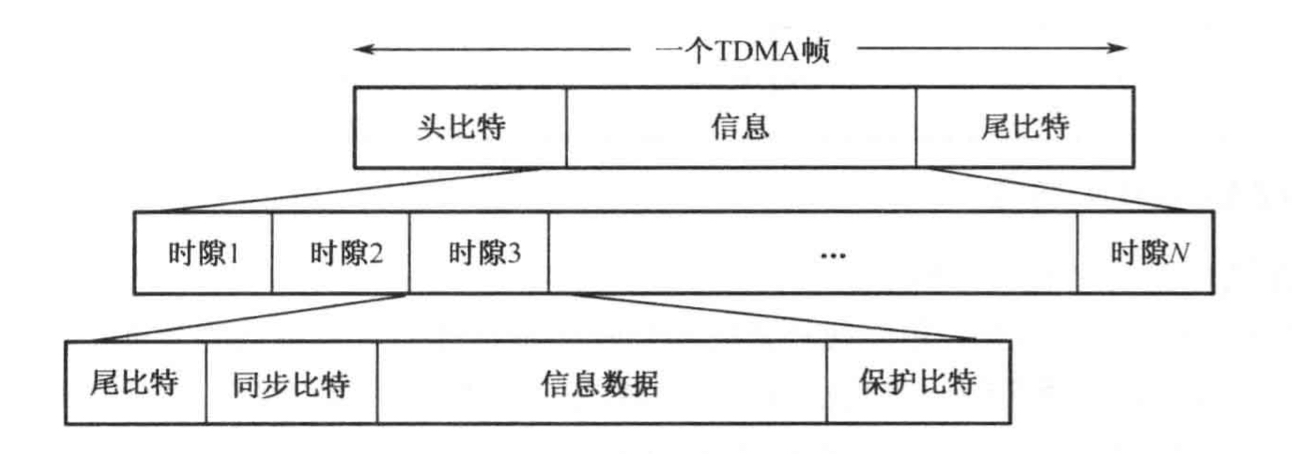
# 摘要
本文全面概述了时分多址(TDMA)技术在GSM网络中的应用与机制,并深入探讨了其调度角色,包括TDMA调度原理、GSM网络中的实施细节,频谱效率及网络容量问题。同时,针对TDMA调度面临的技术挑战,如信号干扰、移动性管理、安全性及隐私问题进行了详细分析。通过案例分析,本文还展示了TDMA调度的实际部署和优化策略,并探讨了未来的展望。
单播传输局限性大破解:解决方法与优化技巧全揭秘
# 摘要
单播传输虽然在数据通信中广泛使用,但其局限性在大规模网络应用中逐渐显现,如带宽利用率低和资源消耗大。多播传输技术作为一种有效的替代方案,能够优化网络资源使用,提高带宽利用率和传输效率,降低网络延迟和成本。本文详细探讨了多播传输的原理、优势、部署、配置技巧以及优化策略,强调了其在实际应用中的成功案例,并对多播技术的未来发展趋势进行了展望,包括新兴技术的应用和跨域多播的挑战。同时,本文还关注了多播安全
SX-DSV03244_R5_0C参数调优实战:专家级步骤与技巧

# 摘要
SX-DSV03244_R5_0C参数调优是提高系统性能与响应速度、优化资源利用的关键技术。本文首先概述了参数调优的目标与重要性,随后详细探讨了相关理论基础,包括性能评估指标、调优方法论及潜在风险。接着,本文
Unicode编码表维护秘籍:如何应对更新与兼容性挑战

# 摘要
Unicode编码作为全球文本信息统一表示的基础,对信息交换和存储有着深远的影响。本文首先介绍了Unicode编码的基本概念、历史发展,然后深入探讨了Unicode编码表的理论基础,包括其结构、分类、更新机制以及兼容性问题。接着,本文详细描述了Unicode编码表的维护实践,涉及更新工具、兼容性测试
【Python效率提升】:优化你的日期计算代码,让它飞起来

# 摘要
本文全面介绍了Python日期时间模块的使用、性能优化以及高级处理技巧。首先概述了日期时间模块的基本构成和功能,随后深入探讨了日期时间对象
【云原生安全终极指南】:构建坚不可摧的云环境的15个必备技巧

# 摘要
随着云计算的普及,云原生安全问题日益凸显,成为行业关注的焦点。本文首先概述了云原生安全的总体框架,随后深入探讨了云安全的理论基础,包括架构原则、关键概念以及云服务模型的安全考量。接着,本文详细介绍了云原生安全实践中的安全配置管理、身份验证与访问控制、数据加密与密钥管理等方面。此外,本文还对云原
【双闭环直流电机控制系统:全攻略】:从原理到应用,掌握PID调速核心
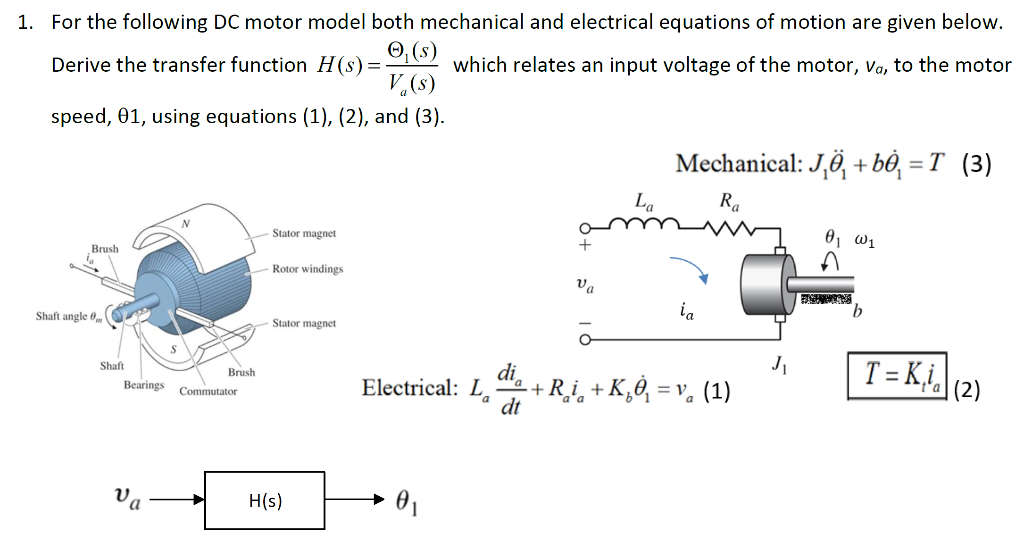
# 摘要
双闭环直流电机控制系统是现代工业自动化领域中不可或缺的一部分,其精确控制与稳定性对工业生产质量及效率具有重大影响。本论文首先介绍了双闭环直流电机控制系统的基本概念及其与单闭环控制系统的对比。接着,深入探讨了直流电机的工作原理、数学模型以及控制理论基础,包括系统稳定性分析和PID控制器的原理与应用。在设计与实现方面,论文详细阐述了双闭环控制系
欧陆590直流调速器故障快速诊断与排除指南:实用技巧大公开

# 摘要
本文系统介绍了欧陆590直流调速器的基本结构、故障诊断基础及实用技巧。首先概述了欧陆590直流调速器的硬件组成与软件配置,并对电气、机械以及控制系统常见故障进行了分类分析。接着,详细介绍了故障诊断工具的选择使用、故障代码解读、信号追踪分析以及参数设置对于故障排除的重要性。通过对典型故障案例的分析,分享了现场快速处理技巧和预防措施。文章最后探讨了高级故障排除技术,包括
倒计时线报机制深度解析:秒杀活动公平性的技术保障

# 摘要
倒计时线报机制作为在线秒杀等高并发场景的关键技术,确保了公平性和一致性,对于提升用户体验和系统性能至关重要。本文首先介绍了倒计时线报机制的理论基础,包括其定义、原理、公平性保障以及与一致性模型的关系。接着,详细探讨了该机制的技术实现,涵盖实时更新同步、请求处理与流量控制、数据一致性保障
【性能优化实战】:Linux环境下IBM X3850服务器性能调优全攻略

# 摘要
本文系统地介绍了Linux服务器性能调优的方法和实践,涵盖了从硬件资源监控到应用程序优化的多个层面。首先概述了Linux服务器性能调优的重要性,随后详细分析了硬件监控、系统负载分析及优化策略。在系统级性能调优策略章节,本研究深入探讨了内核参数调整、系统服务管理及文件系
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )