Applications of Autocorrelation Function in Signal Processing: Noise Reduction, Pattern Recognition
发布时间: 2024-09-15 17:56:51 阅读量: 37 订阅数: 31 

《COMSOL顺层钻孔瓦斯抽采实践案例分析与技术探讨》,COMSOL模拟技术在顺层钻孔瓦斯抽采案例中的应用研究与实践,comsol顺层钻孔瓦斯抽采案例 ,comsol;顺层钻孔;瓦斯抽采;案例,COM
# Basic Concepts of the Autocorrelation Function**
The Autocorrelation Function (ACF) is a mathematical tool used in signal processing to describe the similarity between a signal and its offset version. It measures the correlation of a signal at different time lags, providing valuable insights into the signal's periodicity, trends, and noise.
The definition of ACF is:
```
Rxx(τ) = E[X(t) * X(t + τ)]
```
where:
* X(t) is the signal
* τ is the time lag
* E[.] denotes the expected value
The graph of the autocorrelation function is typically a symmetric function with a peak at τ = 0, indicating complete correlation between the signal and itself. As τ increases, the correlation usually decreases, suggesting a diminishing similarity between the signal at different time lags.
# Applications of the Autocorrelation Function in Noise Reduction**
**2.1 Types and Characteristics of Noise**
Noise is a common干扰 factor in signal processing that can affect the quality and effectiveness of the signal. There are various types of noise, including:
- **Gaussian Noise:** Has a normal distribution with random amplitudes that follow a normal distribution.
- **White Noise:** Has a flat power spectral density across all frequencies, with constant power.
- **Pink Noise:** Has a power spectral density that increases with decreasing frequency, characterized by more low-frequency components.
- **Burst Noise:** Features sudden, aperiodic pulses with large amplitudes.
**2.2 Principles of the Autocorrelation Function in Noise Reduction**
The autocorrelation function can be used to describe the correlation between a signal and its shifted version at different time lags. For noise signals, due to their randomness, the autocorrelation function typically reaches a maximum at zero lag and rapidly decays with increasing lag.
By leveraging this property of the autocorrelation function, filters can be designed to eliminate noise. These filters extract components similar to the noise autocorrelation function from the signal through convolution operations, thereby filtering them out.
**2.3 An Application Example of the Autocorrelation Function: Noise Filtering**
Below is a code example of using the autocorrelation function for noise filtering:
```python
import numpy as np
import scipy.signal as sig
# Generate a noisy signal
signal = np.random.randn(1000) + 0.5 * np.random.randn(1000)
# Compute the autocorrelation function of the signal
autocorr = sig.correlate(signal, signal, mode='same')
# Design the filter
filter_kernel = np.exp(-np.abs(autocorr))
# Filter the signal
filtered_signal = sig.convolve(signal, filter_kernel, mode='same')
# Plot the original signal and the filtered signal
plt.plot(signal, label='Original signal')
plt.plot(filtered_signal, label='Filtered signal')
plt.legend()
plt.show()
```
**Code Logic Analysis:**
1. Generate a noisy signal using `numpy.random.randn()`.
***pute the autocorrelation function using `scipy.signal.correlate()`.
3. Design a filter kernel based on the autocorrelation function, using its values as weights.
4. Filter the signal using `scipy.signal.convolve()`.
5. Plot the original and filtered signals for comparison.
**Parameter Explanation:**
- `signal`: The input signal.
- `mode`: Convolution mode, 'same' means the output signal has the same length as the input signal.
- `filter_kernel`: The filter kernel.
# Applications of the Autocorrelation Function in Pattern Recognition**
**3.1 Basic Principles of Pattern Recognition**
Pattern recognition is a significant branch of computer science aimed at enabling computers to recognize and understand various patterns. Patterns can be images, speech, text, or other forms of data. Pattern recognition is widely applied in many fields, such as image processing, speech recognition, natural language processing, and bioinformatics.
The basic principle of pattern recognition involves comparing input data with known patterns and determining which pattern the input data belongs to based on similarity measures. Similarity measures can be Euclidean distance, cosine similarity, or other metrics.
**3.2 Principles of the Autocorrelation Function in Pattern Recognition**
The autocorrelation function can be used to measure the similarity between two signals. For a given signal x(n), its autocorrelation function is defined as:
```
Rxx(m) = E[x(n)x(n + m)]
```
where E denotes the expected value and m is the time shift.
The value of the autocorrelation function indicates the similarity of the signal at different time shifts. If two signals have similar patterns, their autocorrelation function will r

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
解决组合分配难题:偏好单调性神经网络实战指南(专家系统协同)

# 摘要
本文旨在探讨解决组合分配难题的方法,重点关注偏好单调性理论在优化中的应用以及神经网络的实战应用。文章首先介绍了偏好单调性的定义、性质及其在组合优化中的作用,接着深入探讨了如何
WINDLX模拟器案例研究:3个真实世界的网络问题及解决方案

# 摘要
本文对WINDLX模拟器进行了全面概述,并深入探讨了网络问题的理论基础与诊断方法。通过对比OSI七层模型和TCP/IP模型,分析了网络通信中常见的问题及其分类。文中详细介绍了网络故障诊断技术,并通过案例分析方法展示了理论知识在实践中的应用。三个具体案例分别涉及跨网络性能瓶颈、虚拟网络隔离失败以及模拟器内网络服务崩溃的背景、问题诊断、解决方案实施和结果评估。最后,本文展望了W
【FREERTOS在视频处理中的力量】:角色、挑战及解决方案

# 摘要
FreeRTOS在视频处理领域的应用日益广泛,它在满足实时性能、内存和存储限制、以及并发与同步问题方面面临一系列挑战。本文探讨了FreeRTOS如何在视频处理中扮演关键角色,分析了其在高优先级任务处理和资源消耗方面的表现。文章详细讨论了任务调度优化、内存管理策略以及外设驱动与中断管理的解决方案,并通过案例分析了监控视频流处理、实时视频转码
ITIL V4 Foundation题库精讲:考试难点逐一击破(备考专家深度剖析)
# 摘要
ITIL V4 Foundation作为信息技术服务管理领域的重要认证,对从业者在理解新框架、核心理念及其在现代IT环境中的应用提出了要求。本文综合介绍了ITIL V4的考试概览、核心框架及其演进、四大支柱、服务生命周期、关键流程与功能以及考试难点,旨在帮助考生全面掌握ITIL V4的理论基础与实践应用。此外,本文提供了实战模拟
【打印机固件升级实战攻略】:从准备到应用的全过程解析

# 摘要
本文综述了打印机固件升级的全过程,从前期准备到升级步骤详解,再到升级后的优化与维护措施。文中强调了环境检查与备份的重要性,并指出获取合适固件版本和准备必要资源对于成功升级不可或缺。通过详细解析升级过程、监控升级状态并进行升级后验证,本文提供了确保固件升级顺利进行的具体指导。此外,固件升级后的优化与维护策略,包括调整配置、问题预防和持续监控,旨在保持打印机最佳性能。本文还通过案
【U9 ORPG登陆器多账号管理】:10分钟高效管理你的游戏账号

# 摘要
本文详细探讨了U9 ORPG登陆器的多账号管理功能,首先概述了其在游戏账号管理中的重要性,接着深入分析了支持多账号登录的系统架构、数据流以及安全性问题。文章进一步探讨了高效管理游戏账号的策略,包括账号的组织分类、自动化管理工具的应用和安全性隐私保护。此外,本文还详细解析了U9 ORPG登陆器的高级功能,如权限管理、自定义账号属性以及跨平台使用
【编译原理实验报告解读】:燕山大学案例分析
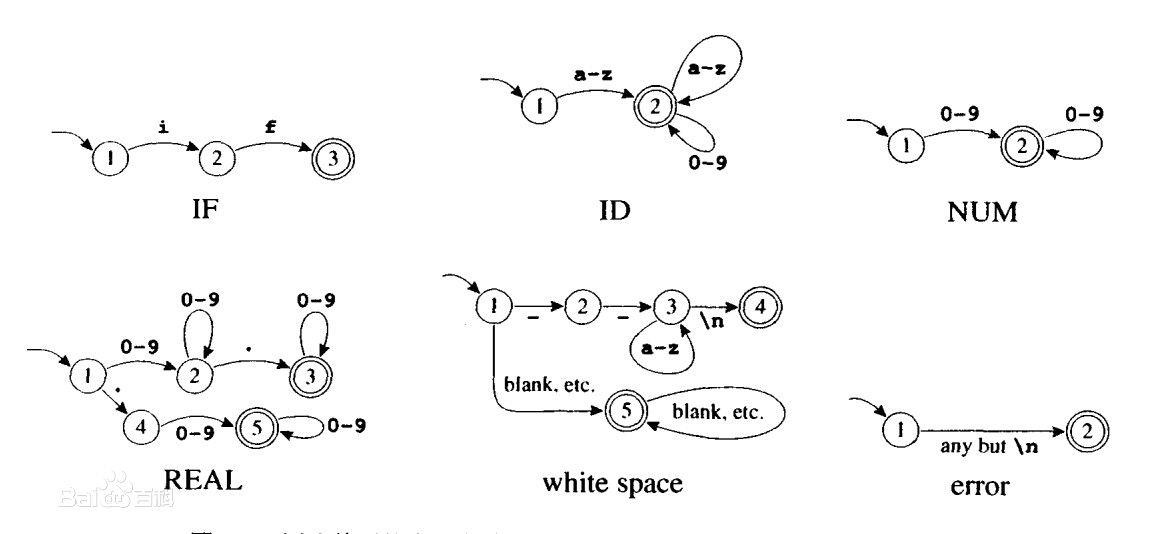
# 摘要
本文是关于编译原理的实验报告,首先介绍了编译器设计的基础理论,包括编译器的组成部分、词法分析与语法分析的基本概念、以及语法的形式化描述。随后,报告通过燕山大学的实验案例,深入分析了实验环境、工具以及案例目标和要求,详细探讨了代码分析的关键部分,如词法分析器的实现和语法分析器的作用。报告接着指出了实验中遇到的问题并提出解决策略,最后展望了编译原理实验的未来方向,包括最新研究动态和对
【中兴LTE网管升级与维护宝典】:确保系统平滑升级与维护的黄金法则

# 摘要
本文详细介绍了LTE网管系统的升级与维护过程,包括升级前的准备工作、平滑升级的实施步骤以及日常维护的策略。文章强调了对LTE网管系统架构深入理解的重要性,以及在升级前进行风险评估和备份的必要性。实施阶段,作者阐述了系统检查、性能优化、升级步骤、监控和日志记录的重要性。同时,对于日常维护,本文提出监控KPI、问题诊断、维护计划执行以及故障处理和灾难恢复措施。案例研究部分探讨了升级维护实践中的挑战与解决方案。最后,文章展望了LT
故障诊断与问题排除:合泰BS86D20A单片机的自我修复指南
# 摘要
本文系统地介绍了故障诊断与问题排除的基础知识,并深入探讨了合泰BS86D20A单片机的特性和应用。章节二着重阐述了单片机的基本概念、硬件架构及其软件环境。在故障诊断方面,文章提出了基本的故障诊断方法,并针对合泰BS86D20A单片机提出了具体的故障诊断流程和技巧。此外,文章还介绍了问题排除的高级技术,包括调试工具的应用和程序自我修复技术。最后,本文就如何维护和优化单片
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )