
BAI et al.: GIFT: TOWARDS SCALABLE 3D SHAPE RETRIEVAL 1259
II. RELATED WORK
3D shape retrieval has been extensively investigated for a long
time, and plenty of algorithms were proposed for 3D model pre-
processing, feature extraction, shape matching, etc. A thorough
and exhausted review of those algorithms is unrealistic. There-
fore, we mainly focus on projection-based methods which have
a close relationship with our work.
Light Field Descriptor (LFD) [15], composed of Zernike mo-
ments and Fourier descriptors, is one of the most representa-
tive projection-based algorithms. Its basic assumption is that
if two 3D shapes are similar, they also look similar from all
viewpoints. Vranic et al. [27] define a composite shape descrip-
tor, which is generated using depth buffer images, silhouettes,
and ray-extents of a polygonal mesh. In [11], a novel descrip-
tor called PANORAMA is proposed. It projects 3D shapes to
the lateral surface of a cylinder, and describes the obtained
panoramic view by 2D Discrete Fourier Transform and 2D Dis-
crete Wavelet Transform. To ensure the rotation invariance as
far as possible, Continuous PCA (CPCA) and Normals PCA
(NPCA) [17] are both applied to 3D shapes before rendering the
projection. Daras et al. [28] propose Compact Multi-view De-
scriptor (CMVD), where 18 characteristic views are described
by 2D Polar-Fourier Transform, 2D Zernike Moments, and 2D
Krawtchouk Moments.
Meanwhile, some researchers consider borrowing the devel-
opment of feature learning in natural image analysis, so as to at-
tain discriminative representations of projections. For example,
Furuya et al. [29] introduce the Bag of visual Words (BoW) [14]
to 3D shape retrieval, where local descriptors [21] are extracted
on depth projections of 3D shapes and encoded into histogram
feature via vector quantization. By putting the visual descrip-
tors from different projections in one bag, Vectors of Locally
Aggregated Tensors (VLAT) [16] is investigated to produce an
equal-sized feature for each 3D shape. Tabia et al. [30], [31]
firstly explore the usage of covariance matrices of descriptors,
instead of the descriptors themselves, in 3D shape analysis.
Bai et al. [32] introduce a two layer coding framework which
jointly encodes a pair of views. By doing so, the spatial ar-
rangement of multiple views is captured which is shown to be
rotation-invariant.
Since deep learning has been proven to be a powerful tool
in many computer vision and pattern recognition topics, there
is an growing interest to leverage this popular paradigm in
3D shape community. As an extension of PANORAMA [11],
Shi et al. [33] choose to pool the response of each row of
feature map so that the deep panoramic representation re-
mains unchanged when the 3D shape rotates with regard to
its principal axis. Multi-view Convolutional Neural Networks
(MVCNN) [34] sets a view pooling layer in the architecture
of CNN to aggregate the multiple view representations. Note
that some deep-learning-based algorithms do not learn from
projections of shapes. For example, Wu et al. [9] perform 3D
Convolution on voxel grid of shapes with Deep Belief Network.
They also construct a large scale 3D shape repository called
ModelNet. In [35]–[38], deep learning is applied to mid-level
shape descriptors, instead of raw shape data.
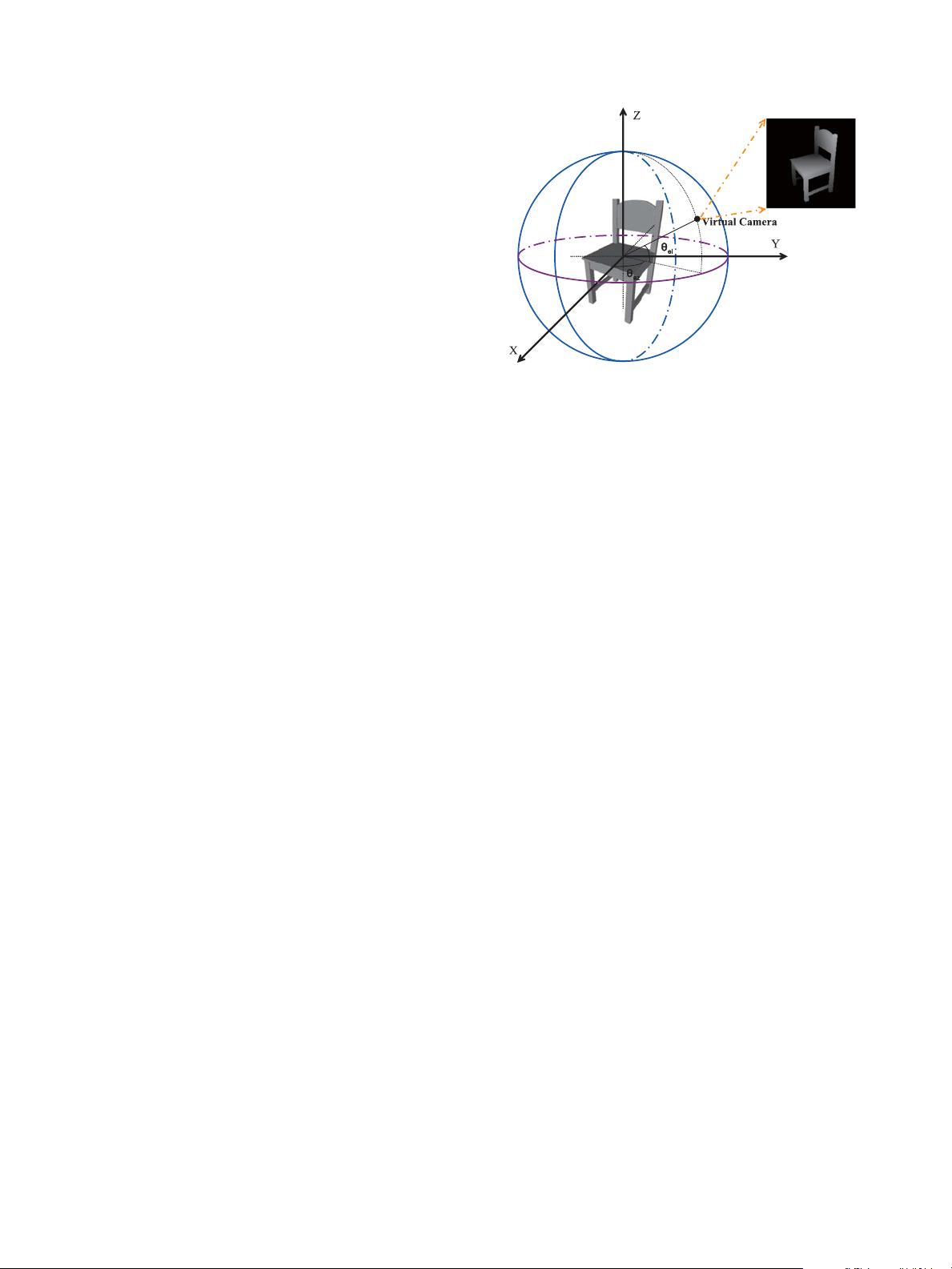
Fig. 2. Illustration of projection rendering. θ
az
is the polar angle in xy plane
and θ
el
is the angle between the camera and xy plane.
Besides, there are also some works which focus on the opti-
mal matching strategy (e.g., clock matching [39], vector extrap-
olation matching [40], random forest [41], elastic net match-
ing [ 42]), discriminative view selection (e.g., adaptive views
clustering [43]), feature fusion (e.g., 2D/3D Hybrid [44], Hybrid
BoW [45], ZFDR [46]) and re-ranking (Multi-Feature Anchor
Manifold Ranking [47], diffusion process [23]).
As opposed to the above algorithms concerning retrieval ac-
curacy only, we establish a shape search system which attaches
more importance to retrieval efficiency.
III. P
ROPOSED SEARCH ENGINE
In this section, the details of each component of the proposed
search engine are given.
A. Projection Rendering
Prior to projection rendering, pose normalization for each 3D
shape is needed in order to attain invariance to some common
geometrical transformations. However, unlike many previous
algorithms [11], [17], [44] that require rotation normalization
using some Principal Component Analysis (PCA) techniques,
we only normalize the scale and the translation in our system.
Our concerns are two-fold: 1) PCA techniques are not always
stable, especially when dealing with some specific geometrical
characteristics such as symmetries, large planar or bumpy sur-
faces; 2) the view feature used in our system can tolerate the
rotation issue to a certain extent, though cannot be completely
invariant to such changes. In fact, we observe that if enough
projections (more than 25 in our experiments) are used, one can
already achieve reliable retrieval performances.
The projection procedure is as follows. Firstly, as illustrated
in Fig. 2, we place the centroid of each 3D shape at the origin
of a spherical coordinate system, and resize the maximum polar
distance of the points on the surface of the shape to unit length.
Then, we evenly divide [0, 2π] into 8 parts to get the values of
θ
az
, and divide [0,π] into 8 parts to get the values of θ
el
.For
each pair (θ
az
,θ
el
), a virtual camera is set on the unit sphere.
剩余14页未读,继续阅读

weixin_38718223
- 粉丝: 11
- 资源: 930
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


