AdaBoost算法调参秘籍:提升性能的实战指南
发布时间: 2024-08-20 12:22:30 阅读量: 80 订阅数: 41 

果壳处理器研究小组(Topic基于RISCV64果核处理器的卷积神经网络加速器研究)详细文档+全部资料+优秀项目+源码.zip

# 1. AdaBoost算法概述**
AdaBoost(Adaptive Boosting)是一种迭代式集成学习算法,通过加权投票的方式将多个弱分类器组合成一个强分类器。其核心思想是:
* 对于每个训练样本,根据其误分类程度分配权重。
* 在每次迭代中,选择一个弱分类器,该分类器对具有较高权重的样本具有更好的分类效果。
* 更新样本权重,使误分类样本的权重增加,正确分类样本的权重减少。
* 重复上述过程,直到达到预定义的迭代次数或满足停止条件。
# 2. AdaBoost算法调参基础
### 2.1 算法参数详解
AdaBoost算法的核心参数主要包括基分类器类型和弱分类器权重。
#### 2.1.1 基分类器类型
基分类器是AdaBoost算法中用于构建弱分类器的基本分类器。常见的基分类器类型包括:
- **决策树:**决策树是一种基于树形结构的分类器,它将数据递归地划分为更小的子集,直到每个子集中的数据都属于同一类。
- **支持向量机:**支持向量机是一种基于超平面的分类器,它通过找到将不同类别的样本分开的最佳超平面来进行分类。
- **朴素贝叶斯:**朴素贝叶斯是一种基于贝叶斯定理的分类器,它假设特征之间相互独立。
基分类器的选择对AdaBoost算法的性能有很大影响。不同的基分类器具有不同的优点和缺点,需要根据具体的数据集和任务进行选择。
#### 2.1.2 弱分类器权重
弱分类器权重是AdaBoost算法中用于衡量每个弱分类器重要性的参数。权重较大的弱分类器对最终分类结果的影响更大。
弱分类器权重由弱分类器的分类误差率决定。误差率较小的弱分类器具有较大的权重。AdaBoost算法通过迭代地更新弱分类器权重来提高算法的整体性能。
### 2.2 评价指标与调参目标
AdaBoost算法的调参目标是找到一组参数,使算法在给定数据集上达到最佳性能。常用的评价指标包括:
- **分类准确率:**正确分类样本数与总样本数之比。
- **F1-Score:**精确率和召回率的调和平均值。
- **ROC曲线:**受试者工作特征曲线,用于评估分类器在不同阈值下的性能。
调参的目的是通过调整算法参数,优化这些评价指标。
**代码块:**
```python
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 导入数据
data = ...
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2)
# 构建AdaBoost分类器
clf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=100)
# 训练分类器
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算分类准确率
accuracy = accuracy_score(y_test, y_pred)
print("分类准确率:", accuracy)
```
**逻辑分析:**
这段代码演示了如何使用scikit-learn库构建和评估一个AdaBoost分类器。
1. `AdaBoostClassifier`类被实例化,其中`base_estimator`参数指定了基分类器类型(这里是决策树),`n_estimators`参数指定了弱分类器的数量。
2. `fit`方法用于训练分类器,它使用训练数据更新弱分类器权重。
3. `predict`方法用于预测测试集上的标签。
4. `accuracy_sco

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 AdaBoost 算法和集成学习方法在实际应用中的强大威力。通过一系列实战指南和案例分析,专栏揭示了 AdaBoost 算法在图像分类、人脸识别、文本分类、异常检测、推荐系统、自然语言处理、医疗诊断、金融预测、计算机视觉和语音识别等领域的应用潜力。此外,专栏还深入分析了 AdaBoost 算法的数学基础、调参技巧和扩展应用,帮助读者全面掌握这一集成学习利器。通过了解 AdaBoost 算法与其他集成学习方法的优劣势,读者可以根据实际应用场景选择最合适的算法,提升机器学习模型的性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
台达触摸屏宏编程:入门到精通的21天速成指南

# 摘要
本文系统地介绍了台达触摸屏宏编程的全面知识体系,从基础环境设置到高级应用实践,为触摸屏编程提供了详尽的指导。首先概述了宏编程的概念和触摸屏环境的搭建,然后深入探讨了宏编程语言的基础知识、宏指令和控制逻辑的实现。接下来,文章介绍了宏编程实践中的输入输出操作、数据处理以及与外部设备的交互技巧。进阶应用部分覆盖了高级功能开发、与PLC的通信以及故障诊断与调试。最后,通过项目案例实战,展现了如何将理论知识应用
信号完整性不再难:FET1.1设计实践揭秘如何在QFP48 MTT中实现

# 摘要
本文综合探讨了信号完整性在高速电路设计中的基础理论及应用。首先介绍信号完整性核心概念和关键影响因素,然后着重分析QFP48封装对信号完整性的作用及其在MTT技术中的应用。文中进一步探讨了FET1.1设计方法论及其在QFP48封装设计中的实践和优化策略。通过案例研究,本文展示了FET1.1在实际工程应用中的效果,并总结了相关设计经验。最后,文章展望了FET
【MATLAB M_map地图投影选择】:理论与实践的完美结合
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/3470884/1024px-Robinson_projection_SW.0.jpg)
# 摘要
M_map工具包是一种在MATLAB环境下使用的地图投影软件,提供了丰富的地图投影方法与定制选项,用
打造数据驱动决策:Proton-WMS报表自定义与分析教程
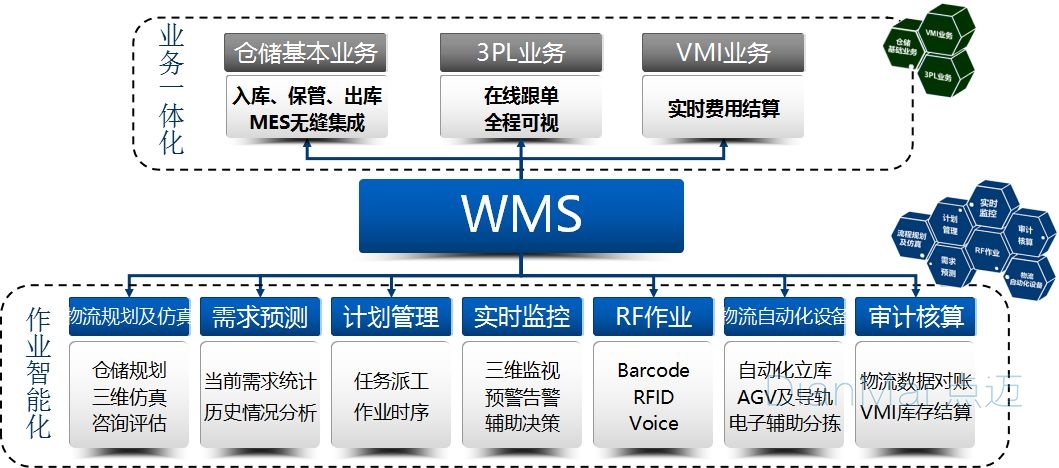
# 摘要
本文旨在全面介绍Proton-WMS报表系统的设计、自定义、实践操作、深入应用以及优化与系统集成。首先概述了报表系统的基本概念和架构,随后详细探讨了报表自定义的理论基础与实际操作,包括报表的设计理论、结构解析、参数与过滤器的配置。第三章深入到报表的实践操作,包括创建过程中的模板选择、字段格式设置、样式与交互设计,以及数据钻取与切片分析的技术。第四章讨论了报表分析的高级方法,如何进行大数据分析,以及报表的自动化
【DELPHI图像旋转技术深度解析】:从理论到实践的12个关键点

# 摘要
图像旋转是数字图像处理领域的一项关键技术,它在图像分析和编辑中扮演着重要角色。本文详细介绍了图像旋转技术的基本概念、数学原理、算法实现,以及在特定软件环境(如DELPHI)中的应用。通过对二维图像变换、旋转角度和中心以及插值方法的分析
RM69330 vs 竞争对手:深度对比分析与最佳应用场景揭秘

# 摘要
本文全面比较了RM69330与市场上其它竞争产品,深入分析了RM69330的技术规格和功能特性。通过核心性能参数对比、功能特性分析以及兼容性和生态系统支持的探讨,本文揭示了RM69330在多个行业中的应用潜力,包括消费电子、工业自动化和医疗健康设备。行业案例与应用场景分析部分着重探讨了RM69330在实际使用中的表现和效益。文章还对RM69330的市场表现进行了评估,并提供了应
无线信号信噪比(SNR)测试:揭示信号质量的秘密武器!
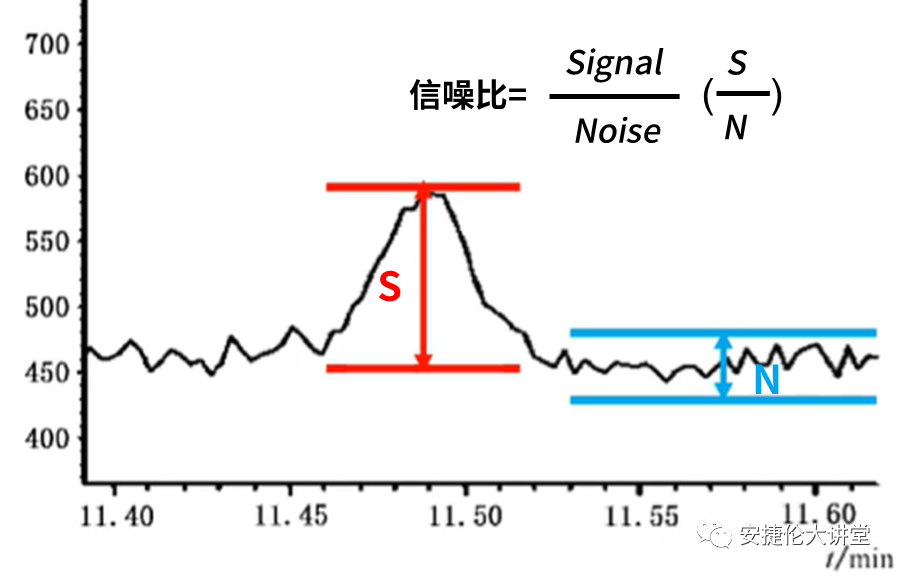
# 摘要
无线信号信噪比(SNR)是衡量无线通信系统性能的关键参数,直接影响信号质量和系统容量。本文系统地介绍了SNR的基础理论、测量技术和测试实践,探讨了SNR与无线通信系统性能的关联,特别是在天线设计和5G技术中的应用。通过分析实际测试案例,本文阐述了信噪比测试在无线网络优化中的重要作用,并对信噪比测试未来的技术发展趋势和挑战进行
【UML图表深度应用】:Rose工具拓展与现代UML工具的兼容性探索
# 摘要
本文系统地介绍了统一建模语言(UML)图表的理论基础及其在软件工程中的重要性,并对经典的Rose工具与现代UML工具进行了深入探讨和比较。文章首先回顾了UML图表的理论基础,强调了其在软件设计中的核心作用。接着,重点分析了Rose工具的安装、配置、操作以及在UML图表设计中的应用。随后,本文转向现代UML工具,阐释其在设计和配置方面的
台达PLC与HMI整合之道:WPLSoft界面设计与数据交互秘笈
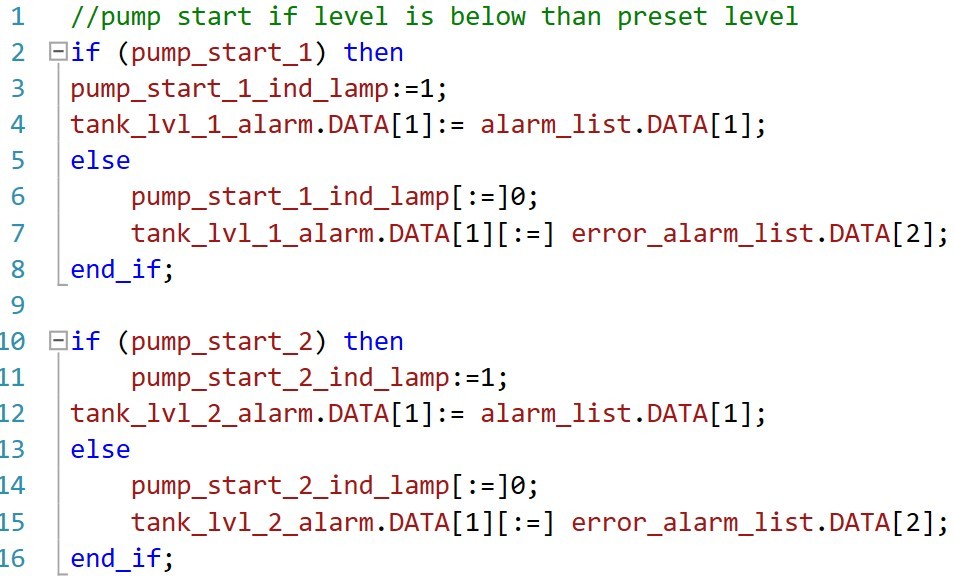
# 摘要
本文旨在提供台达PLC与HMI交互的深入指南,涵盖了从基础界面设计到高级功能实现的全面内容。首先介绍了WPLSoft界面设计的基础知识,包括界面元素的创建与布局以及动态数据的绑定和显示。随后深入探讨了WPLSoft的高级界面功能,如人机交互元素的应用、数据库与HMI的数据交互以及脚本与事件驱动编程。第四章重点介绍了PLC与HMI之间的数据交互进阶知识,包括PLC程序设计基础、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )