可解释人工智能:如何设计可解释的机器学习管道:从数据预处理到模型部署
发布时间: 2024-08-22 23:45:21 阅读量: 18 订阅数: 11 
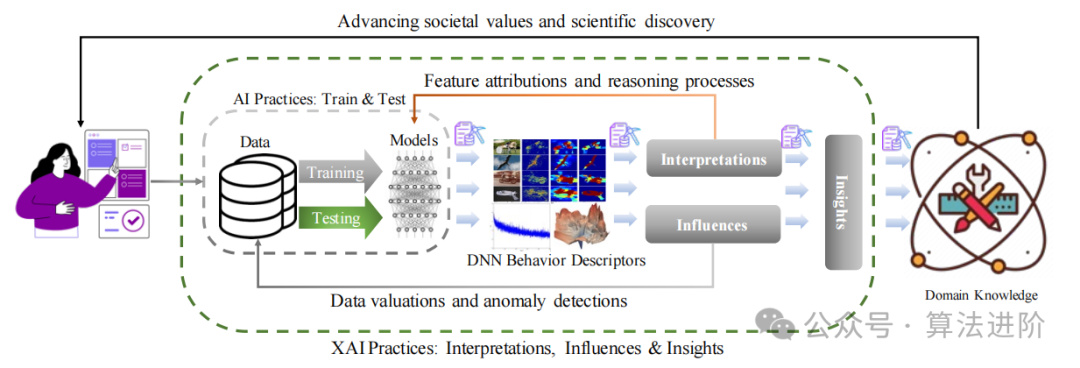
# 1. 可解释人工智能概述
可解释人工智能(XAI)是人工智能(AI)的一个子领域,它旨在使机器学习模型和算法的可理解和解释。XAI 对于理解 AI 系统的决策过程至关重要,从而提高透明度、可信度和问责制。
XAI 涉及开发技术和方法,使 AI 模型能够以人类可以理解的方式解释其预测和决策。这包括提供有关模型输入、输出和内部工作原理的信息。通过可解释性,我们可以评估模型的可靠性、识别潜在的偏差并确保模型符合道德准则。
# 2. 可解释机器学习管道的理论基础
### 2.1 可解释性度量和方法
可解释性度量是衡量机器学习模型可解释程度的标准。常见的可解释性度量包括:
- **局部可解释性 (LIME)**:通过扰动输入数据并观察模型输出的变化来解释单个预测。
- **SHAP (SHapley Additive Explanations)**:使用博弈论中的 Shapley 值来衡量每个特征对模型预测的影响。
- **决策树和规则集**:使用决策树或规则集来表示模型,从而提供易于理解的解释。
可解释性方法是用于提高机器学习模型可解释性的技术。这些方法包括:
- **特征重要性**:识别对模型预测影响最大的特征。
- **局部可解释模型 (LIM)**:训练一个局部模型来解释单个预测。
- **对抗性示例**:生成欺骗模型的输入,以了解模型的弱点。
### 2.2 机器学习模型的可解释性技术
不同的机器学习模型具有不同的可解释性技术。以下是一些常见模型的可解释性技术:
| 模型类型 | 可解释性技术 |
|---|---|
| **线性模型** | 特征重要性、局部可解释模型 |
| **决策树** | 决策树、规则集 |
| **随机森林** | 特征重要性、局部可解释模型 |
| **支持向量机** | 局部可解释模型、对抗性示例 |
| **神经网络** | 局部可解释模型、对抗性示例、梯度解释 |
**代码块:**
```python
import shap
# 加载数据
data = pd.read_csv('data.csv')
# 训练模型
model = RandomForestClassifier()
model.fit(data[['feature1', 'feature2']], data['target'])
# 使用 SHAP 解释模型
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(data[['feature1', 'feature2']])
# 可视化 SHAP 值
shap.plots.waterfall(shap_values)
```
**逻辑分析:**
这段代码使用 SHAP (SHapley Additive Explanations) 来解释一个随机森林分类模型。SHAP 值表示每个特征对模型预测的影响。瀑布图可视化了这些影响,显示了特征如何共同影响模型输出。
**参数说明:**
- `shap.TreeExplainer(mod
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了可解释人工智能 (XAI) 技术,旨在让机器学习模型能够解释其决策背后的逻辑。文章涵盖了 XAI 的概念、实践、技术栈、应用场景、应对偏见和歧视的挑战、增强模型透明度和可信度的技术、在医疗保健、金融和制造业中的应用、分析过程和解决方案、评估和选择可解释模型的方法、应对模型漂移和概念漂移的策略、设计可解释机器学习管道的方法、在监管和合规中的作用,以及 XAI 在实践中的挑战和机遇。通过揭开人工智能模型的黑匣子,XAI 赋能决策者,提升信任,并促进人工智能的负责任发展。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Research on the Application of ST7789 Display in IoT Sensor Monitoring System
# Introduction
## 1.1 Research Background
With the rapid development of Internet of Things (IoT) technology, sensor monitoring systems have been widely applied in various fields. Sensors can collect various environmental parameters in real-time, providing vital data support for users. In these mon
Financial Model Optimization Using MATLAB's Genetic Algorithm: Strategy Analysis and Maximizing Effectiveness
# 1. Overview of MATLAB Genetic Algorithm for Financial Model Optimization
Optimization of financial models is an indispensable part of financial market analysis and decision-making processes. With the enhancement of computational capabilities and the development of algorithmic technologies, it has
ode45 Solving Differential Equations: The Insider's Guide to Decision Making and Optimization, Mastering 5 Key Steps
# The Secret to Solving Differential Equations with ode45: Mastering 5 Key Steps
Differential equations are mathematical models that describe various processes of change in fields such as physics, chemistry, and biology. The ode45 solver in MATLAB is used for solving systems of ordinary differentia
Time Series Chaos Theory: Expert Insights and Applications for Predicting Complex Dynamics
# 1. Fundamental Concepts of Chaos Theory in Time Series Prediction
In this chapter, we will delve into the foundational concepts of chaos theory within the context of time series analysis, which is the starting point for understanding chaotic dynamics and their applications in forecasting. Chaos t
MATLAB Genetic Algorithm Automatic Optimization Guide: Liberating Algorithm Tuning, Enhancing Efficiency
# MATLAB Genetic Algorithm Automation Guide: Liberating Algorithm Tuning for Enhanced Efficiency
## 1. Introduction to MATLAB Genetic Algorithm
A genetic algorithm is an optimization algorithm inspired by biological evolution, which simulates the process of natural selection and genetics. In MATLA
YOLOv8 Practical Case: Lesion Detection and Segmentation in Medical Imaging
# 1. Introduction to YOLOv8
YOLOv8 is the latest version of the You Only Look Once (YOLO) object detection algorithm, ***pared to previous YOLO versions, YOLOv8 introduces many improvements, including:
- **Enhanced backbone network:** YOLOv8 uses CSPDarknet53 as its backbone network, which is an e
Peripheral Driver Development and Implementation Tips in Keil5
# 1. Overview of Peripheral Driver Development with Keil5
## 1.1 Concept and Role of Peripheral Drivers
Peripheral drivers are software modules designed to control communication and interaction between external devices (such as LEDs, buttons, sensors, etc.) and the main control chip. They act as an
MATLAB Legends and Financial Analysis: The Application of Legends in Visualizing Financial Data for Enhanced Decision Making
# 1. Overview of MATLAB Legends
MATLAB legends are graphical elements that explain the data represented by different lines, markers, or filled patterns in a graph. They offer a concise way to identify and understand the different elements in a graph, thus enhancing the graph's readability and compr
Vibration Signal Frequency Domain Analysis and Fault Diagnosis
# 1. Basic Knowledge of Vibration Signals
Vibration signals are a common type of signal found in the field of engineering, containing information generated by objects as they vibrate. Vibration signals can be captured by sensors and analyzed through specific processing techniques. In fault diagnosi
【Practical Exercise】MATLAB Nighttime License Plate Recognition Program
# 2.1 Histogram Equalization
### 2.1.1 Principle and Implementation
Histogram equalization is an image enhancement technique that improves the contrast and brightness of an image by adjusting the distribution of pixel values. The principle is to transform the image histogram into a uniform distrib
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )