PID调节器精准把控温度:温度控制中的应用实践
发布时间: 2024-07-09 10:23:39 阅读量: 71 订阅数: 46 
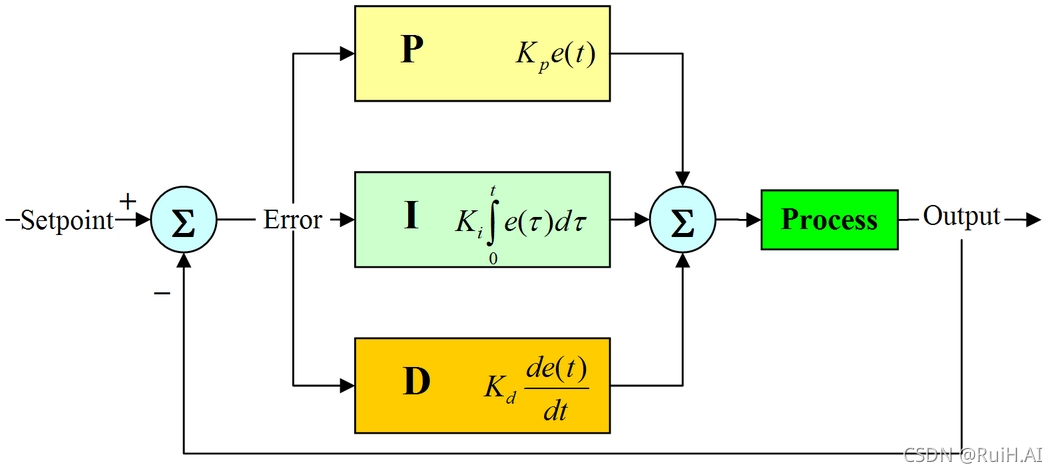
# 1. PID调节器理论基础**
PID调节器(Proportional-Integral-Derivative Controller)是一种反馈控制系统,广泛应用于温度控制等领域。其基本原理是:根据被控对象的偏差(误差)来调整控制输出,从而实现对被控对象的精准控制。
PID调节器由三个基本组成部分组成:比例(P)项、积分(I)项和微分(D)项。P项根据偏差的当前值进行调整,I项根据偏差的累积值进行调整,D项根据偏差变化率进行调整。通过调整这三个参数的比例,可以实现对被控对象的快速响应、平稳控制和抗干扰能力的优化。
# 2. PID调节器实践应用
### 2.1 PID参数的选取和优化
PID调节器的性能很大程度上取决于其参数的选取和优化。有几种方法可以确定合适的PID参数,包括:
#### 2.1.1 Ziegler-Nichols方法
Ziegler-Nichols方法是一种经典且广泛使用的PID参数选取方法。该方法基于阶跃响应的分析,步骤如下:
1. 将PID控制器切换到P控制模式,并将P增益逐渐增加,直到系统出现持续振荡。
2. 记录振荡的周期(T)和振幅(A)。
3. 根据T和A,使用下表确定PID参数:
| 控制器类型 | Kp | Ti | Td |
|---|---|---|---|
| P | 0.5 * Kc | - | - |
| PI | 0.45 * Kc | 0.85 * T | - |
| PID | 0.6 * Kc | 0.5 * T | 0.125 * T |
其中,Kc = 1.2 / A。
**代码块:**
```python
import numpy as np
def ziegler_nichols(T, A):
"""
Ziegler-Nichols方法计算PID参数。
参数:
T: 振荡周期
A: 振荡幅度
返回:
Kp, Ti, Td: PID参数
"""
Kc = 1.2 / A
Kp = 0.5 * Kc
Ti = 0.85 * T
Td = 0.125 * T
return Kp, Ti, Td
```
**逻辑分析:**
该代码块实现了Ziegler-Nichols方法。它接收振荡周期(T)和振幅(A)作为输入,并根据这些值计算PID参数(Kp、Ti、Td)。
#### 2.1.2 试差法
试差法是一种迭代方法,通过逐步调整PID参数来优化系统性能。步骤如下:
1. 将PID控制器切换到P控制模式,并设置一个初始P增益。
2. 观察系统的响应,并根据误差调整P增益。
3. 添加I控制,并调整Ti以减少误差的积分。
4. 添加D控制,并调整Td以减少误差的导数。
**代码块:**
```python
import time
def trial_and_error(pid, error_threshold):
"""
试差法优化PID参数。
参数:
pid: PID控制器对象
error_threshold: 误差阈值
返回:
Kp, Ti, Td: 优化后的PID参数
"""
Kp = 0.1
Ti = 1.0
Td = 0.1
while True:
pid.set_parameters(Kp, Ti, Td)
error = pid.get_error()
if abs(error) < error_threshold:
break
# 调整参数
if error > 0:
Kp += 0.01
else:
Kp -= 0.01
if error > 0:
Ti += 0.1
else:
Ti -= 0.1
if error > 0:
Td += 0.01
else:
Td -= 0.01
return Kp, Ti, Td
```
**逻辑分析:**
该代码块实现了试差法。它接收一个PID控制器对象(pid)和一个误差阈值(error_threshold)作为输入。它迭代地调整PID参数(Kp、Ti、Td),直到误差低于阈值。
# 3.1 温度传感器的选择和安装
**温度传感器的选择**
温度传感器的选择至关重要,因为它直接影响温度控制系统的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《PID 调节器实战指南》专栏深入探讨了 PID 调节器的原理、应用和优化策略。从参数调优秘诀到稳定性提升策略,再到抗干扰性提升秘籍,专栏提供了全面的指南,帮助读者掌握 PID 控制。此外,专栏还展示了 PID 调节器在工业自动化、过程控制、机器人控制、电网稳定、飞行器运行、环境控制、汽车控制、智能家居、工业机器人、伺服系统、温度控制、压力控制、液位控制和速度控制等领域的广泛应用。通过深入剖析实际案例,专栏提供了宝贵的见解和实践指南,帮助读者在各种应用场景中有效利用 PID 调节器,提升控制性能,保障系统稳定,优化工艺流程,并实现智能控制。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
提升系统响应与精准度:比例谐振控制算法优化秘籍
参考资源链接:[比例谐振PR控制器详解:从理论到实践](https://wenku.csdn.net/doc/5ijacv41jb?spm=1055.2635.3001.10343)
#
FANUC机器人通讯调试宝典:日志分析与错误追踪的高效方法
参考资源链接:[FANUC机器人TCP/IP通信设置手册](https://wenku.csdn.net/doc/6401acf8cce7214c316edd05?spm=1055.2635.3001.10343)
# 1. FANUC机器人通信概述
## 1.1 通信协议基础
FANUC机器人通常使用专有通信协议与控制系统进行通信。了解这些协议是确保机器人有效沟通和操作的关键。通信协议定义了信息交换的规则和格式,包括数据包结构、消息类型、传输速率和错误检测机制。
## 1.2 通信硬件组件
通信硬件是机器人通信的物理基础,包括接口、电缆、交换机和路由器等。为了实现高效通信,需要选择合适的
iSecure Center审计功能:合规性监控与审计报告完全解析

参考资源链接:[iSecure Center 安装指南:综合安防管理平台部署步骤](https://wenku.csdn.net/doc/2f6bn25sjv?spm=1055.2635.3001.10343)
# 1. iSecure Center审计功能概述
## 1.1 了解iSecure Center
iSecure Center是一个高效的审计和合规性
STM32F103VET6编程接口设计:ISP与JTAG注意事项详解
参考资源链接:[STM32F103VET6 PCB原理详解:最小系统板与电路布局](https://wenku.csdn.net/doc/6412b795be7fbd1778d4ad36?spm=1055.2635.3001.10343)
# 1. STM32F103VET6硬件概述与接口介绍
## 简介
在嵌入式系统开发中,STM32F103VET6
【ASP.NET Core Web API设计】:构建RESTful服务的最佳实践

参考资源链接:[ASP.NET实用开发:课后习题详解与答案](https://wenku.csdn.net/doc/649e3a1550e8173efdb59dbe?spm=1055.2635.3001.10343)
# 1. ASP.NET
硬盘SMART信息解读:高级用户必备知识
参考资源链接:[硬盘SMART错误警告解决办法与诊断技巧](https://wenku.csdn.net/doc/7cskgjiy20?spm=1055.2635.3001.10343)
# 1. 硬盘与SMART技术概述
硬盘是计算机中存储数据的关键部件,它的稳定性直接关系到整个系统的运行。随着技术的发展,硬盘存储容量和速度不断提升,随之而来的是更高的故障风险。因此,硬盘的健康监测变得至关重要。SMART(Self-Monitoring, Analysis, and Reporting Technology)技术应运而生,它是一种硬盘自我监测、分析和报告技术,目的是通过持续监控硬盘运行状态
电动汽车充电效率提升:SAE J1772标准实施难点的解决方案

参考资源链接:[SAE J1772-2017.pdf](https://wenku.csdn.net/doc/6412b74abe7fbd1778d
【自动编译问题排查】:IDEA编译错误,快速诊断与解决
参考资源链接:[IDEA 开启自动编译设置步骤](https://wenku.csdn.net/doc/646ec8d7d12cbe7ec3f0b643?spm=1055.2635.3001.10343)
# 1. 理解IDEA中的自动编译机制
在使用现代集成开发环境(IDE)如IntelliJ IDEA进行
【PFC5.0高可用性架构设计】:保障业务连续性的策略与技巧

参考资源链接:[PFC5.0用户手册:入门与教程](https://wenku.csdn.net/doc/557hjg39sn?spm=1055.2635.3001.10343)
# 1. PFC5.0高可用性架构概述
PFC5.0高可用性架构作为企业级解决方案的最新突破,旨在为企业提供不间断的业务运行和数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )