Post-processing Techniques in YOLOv8: In-depth Analysis of Non-Maximum Suppression Algorithm
发布时间: 2024-09-14 00:48:55 阅读量: 51 订阅数: 28 

yolov8系列--Real time people counting system in computer vis.zip
# Post-processing Tricks in YOLOv8: In-depth Analysis of the Non-Maximum Suppression Algorithm
## 1. Overview of the Non-Maximum Suppression Algorithm
The Non-Maximum Suppression (NMS) algorithm is a classic technique used in the post-processing phase of object detection. Its purpose is to select the most representative bounding boxes from a set of overlapping detections to enhance detection accuracy and reduce redundancy. NMS works by calculating the overlap between bounding boxes, suppressing those with a higher degree of overlap with the box of highest confidence, thereby keeping the most representative boxes.
## 2. Theoretical Foundations of the NMS Algorithm
### 2.1 Intersection over Union (IoU) Calculation
Within the NMS algorithm, Intersection over Union (IoU) is a critical metric used to measure the overlap between two bounding boxes. The formula for IoU is as follows:
```python
IoU(box1, box2) = area_of_intersection / area_of_union
```
Here, `area_of_intersection` is the area of the intersection between the two bounding boxes, and `area_of_union` is the area of the union of the two bounding boxes.
### 2.2 NMS Algorithm Flow
The basic process of the NMS algorithm is as follows:
1. Obtain all detected bounding boxes based on the output of the object detection model.
2. Calculate the degree of overlap between all bounding boxes using IoU values.
3. Start with the bounding box with the highest IoU value and traverse all bounding boxes in turn.
4. For each bounding box, check the IoU value with previously processed bounding boxes.
5. If the IoU value exceeds the set threshold, suppress that bounding box.
6. Repeat steps 4 and 5 until all bounding boxes have been processed.
### 2.3 Variants of the NMS Algorithm
To enhance the performance and robustness of the NMS algorithm, researchers have proposed various variants, including:
- **Soft-NMS Algorithm:** The Soft-NMS algorithm performs a smooth handling of IoU values, avoiding the problem of bounding box loss caused by hard thresholds.
- **DIoU-NMS Algorithm:** The DIoU-NMS algorithm introduces directional information on top of IoU, making the NMS algorithm more robust to the rotation and deformation of bounding boxes.
- **CIoU-NMS Algorithm:** The CIoU-NMS algorithm further improves upon DIoU-NMS by incorporating information about the distance between centers and the aspect ratio, making the NMS algorithm more robust to changes in the shape of bounding boxes.
These NMS algorithm variants have demonstrated different performance advantages in various object detection tasks, allowing developers to choose based on specific requirements.
## 3. Application of the NMS Algorithm in YOLOv8
### 3.1 YOLOv8 NMS Algorithm Implementation
In YOLOv8, the NMS algorithm is mainly used to filter the candidate boxes output by the object detection model to remove redundant boxes with higher overlap, thereby improving detection accuracy. YOLOv8 employs an NMS implementation based on a greedy algorithm, with the following specific process:
1. **Sort by Confidence:** Sort all candidate boxes in descending order of confidence.
2. **Select the Highest Confidence Box:** Choose the box with the highest confidence as the box to be retained.
3. **Calculate IoU with the Retained Box:** Calculate the IoU (Intersection over Union) between the retained box and all other candidate boxes.
4. **Remove Candidate Boxes with High IoU:** If the IoU of other candidate boxes with the retained box is greater than the set threshold (commonly 0.5), then they are removed.
5. **Repeat Steps 2-4:** Repeat steps 2-4 until all candidate boxes have been processed.
```python
def nms(bboxes, scores, iou_threshold):
"""YOLOv8 NMS algorithm implementation.
Args:
bboxes: Candidate box coordinates, shape [N, 4].
scores: Confidence scores of candidate boxes, shape [N].
iou_threshold: IoU threshold.
Returns:
Indices of retained boxes, shape [K].
"""
# Sort by confidence in descending order
order = scores.argsort()[::-1]
# Initialize the list of retained box indices
keep = []
# Traverse candidate boxes
while order.size > 0:
# Select the box with the highest confidence
i = order[0]
keep.append(i)
# Calculate IoU with the retained box
ious = bbox_iou(bboxes[i], bboxes[order[1:]])
# Remove candidate boxes with high IoU
order = order[1:][ious < iou_threshold]
return keep
```
### 3.2 Impact of the NMS Algorithm on YOLOv8 Detection Accuracy
The NMS algorithm has a significant impact on YOLOv8's detection accuracy. By adjusting the IoU threshold of NMS, a balance can be struck between the number of retained boxes and detection accuracy.
When the IoU threshold is low, more candidate boxes are retained, whi

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
矢量控制技术深度解析:电气机械理论与实践应用全指南
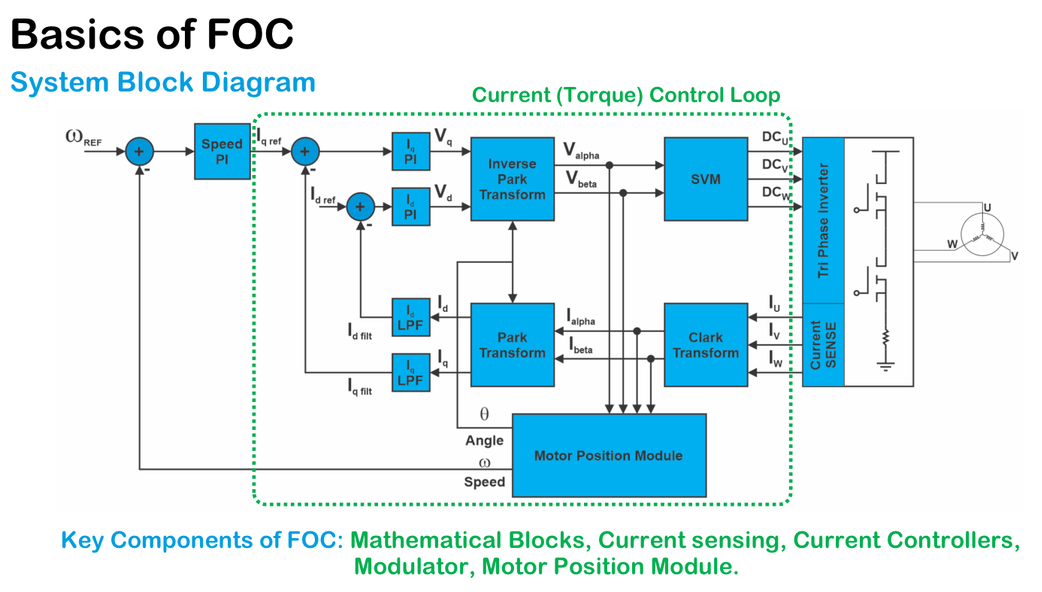
# 摘要
矢量控制技术是电力电子和电气传动领域的重要分支,它通过模拟直流电机的性能来控制交流电机,实现高效率和高精度的电机控制。本文首先概述了矢量控制的基本概念和理论基础,包括电气机械控制的数学模型、矢量变换理论以及相关的数学工具,如坐标变换、PI调节器和PID控制。接着,文章探讨了矢量控制技术在硬件和软件层面的实现,包括电力
【深入解析】:掌握Altium Designer PCB高级规则的优化设置
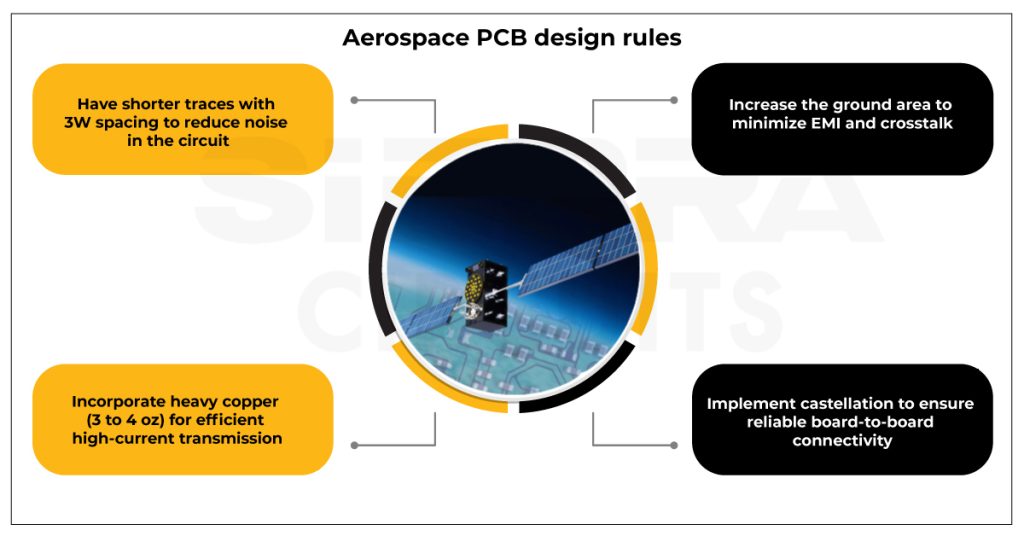
# 摘要
随着电子设备的性能需求日益增长,PCB设计的复杂性和精确性要求也在提升。Altium Designer作为领先的电子设计自动化软件,其高级规则对确保PCB设计质量起着至关重要的作用。本文详细介绍了Altium Designer PCB设计的基础知识、高级规则的理论基础、实际应用、进阶技巧以及优化案例研究,强调了
Oracle11g x32位在Linux下的安全设置:全面保护数据库的秘诀

# 摘要
Oracle 11g数据库安全是保障企业数据资产的关键,涉及多个层面的安全加固和配置。本文从操作系统层面的安全加固出发,探讨了用户和权限管理、文件系统的安全配置,以及网络安全的考量。进一步深入分析了Oracle 11g数据库的安全设置,如身份验证和授权机制、审计策略实施和数据加密技术的应用。文章还介绍了数据库内部的安全策略,包括安全配置的高级选项、防护措
RJ接口升级必备:技术演进与市场趋势的前瞻性分析

# 摘要
RJ接口作为通信和网络领域的重要连接器,其基础知识和演进历程对技术发展具有深远影响。本文首先回顾了RJ接口的发展历史和技术革新,分析了其物理与电气特性以及技术升级带来的高速数据传输与抗干扰能力的提升。然后,探讨了RJ接口在不同行业应用的现状和特点,包括在通信、消费电子和工业领域的应用案例。接着,文章预测了RJ接口市场的未来趋势,包括市场需求、竞争环境和标准化进程。
MATLAB线性方程组求解:这4种策略让你效率翻倍!
# 摘要
MATLAB作为一种高效的数学计算和仿真工具,在解决线性方程组方面展现出了独特的优势。本文首先概述了MATLAB求解线性方程组的方法,并详细介绍了直接法和迭代法的基本原理及其在MATLAB中的实现。直接法包括高斯消元法和LU分解,而迭代法涵盖了雅可比法、高斯-赛德尔法和共轭梯度法等。本文还探讨了矩阵分解技术的优化应用,如QR分解和奇异值分解(SVD),以及它们在提升求解效率和解决实际问题中的作用。最后,通过具体案例分析,本文总结了工程应用中不同类型线性方程组的求解策略,并提出了优化求解效率的建议。
# 关键字
MATLAB;线性方程组;高斯消元法;LU分解;迭代法;矩阵分解;数值稳
【效率提升算法设计】:算法设计与分析的高级技巧
# 摘要
本文全面探讨了算法设计的基础知识、分析技术、高级技巧以及实践应用,并展望了未来算法的发展方向。第一章概述了算法设计的基本概念和原则,为深入理解算法提供了基础。第二章深入分析了算法的时间复杂度与空间复杂度,并探讨了算法的正确性证明和性能评估方法。第三章介绍了高级算法设计技巧,包括分治策略、动态规划和贪心算法的原理和应用。第四章将理论与实践相结合,讨论了数据结构在算法设计中的应用、算法设计模式和优化策略。最后一章聚焦于前
【全面性能评估】:ROC曲线与混淆矩阵在WEKA中的应用

# 摘要
本文从性能评估的角度,系统介绍了ROC曲线和混淆矩阵的基本概念、理论基础、计算方法及其在WEKA软件中的应用。首先,本文对ROC曲线进行了深入
MTi故障诊断到性能优化全攻略:保障MTi系统稳定运行的秘诀

# 摘要
本文系统地阐述了MTi系统的故障诊断和性能调优的理论与实践。首先介绍了MTi系统故障诊断的基础知识,进而详细分析了性能分析工具与方法。实践应用章节通过案例研究展示了故障诊断方法的具体操作。随后,文章讨论了MTi系统性能调优策略,并提出了保障系统稳定性的措施。最后,通过案例分析总结了经验教训,为类似系统的诊断和优化提供了宝贵的参考。本文
数字电路实验三进阶课程:高性能组合逻辑设计的7大技巧

# 摘要
组合逻辑设计是数字电路设计中的核心内容,对提升系统的性能与效率至关重要。本文首先介绍了组合逻辑设计的基础知识及其重要性,随后深入探讨了高性能组合逻辑设计的理论基础,包括逻辑门的应用、逻辑简化原理、时间分析及组合逻辑电路设计的优化。第三章详细阐述了组合逻辑设计的高级技巧,如逻辑电路优化重构、流水线技术的结合以及先进设计方法学的应用。第四章通过实践应用探讨了设计流程、仿真验证
【CUDA图像处理加速技术】:中值滤波的稀缺优化策略与性能挑战分析

# 摘要
随着并行计算技术的发展,CUDA已成为图像处理领域中加速中值滤波算法的重要工具。本文首先介绍了CUDA与图像处理基础,然后详细探讨了CUDA中值滤波算法的理论和实现,包括算法概述、CUDA的并行编程模型以及优化策略。文章进一步分析了中值滤波算法面临的性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )