YOLOv8 Model Fusion and Transfer Learning: Analysis of Cross-Domain Task Transfer Strategies
发布时间: 2024-09-14 01:06:38 阅读量: 53 订阅数: 26 
# 1. Introduction to the YOLOv8 Model**
The YOLOv8 is one of the most advanced real-time object detection algorithms, known for its speed and high accuracy. It is based on the YOLOv7 architecture and incorporates several improvements, including:
- **Bag of Freebies (BoF)**: A collection of data augmentation and regularization techniques that significantly enhance the model's generalization ability.
- **Deep Supervision**: Supervising features at different stages during training to strengthen the model's gradient flow and feature extraction capabilities.
- **Mish Activation**: A smooth, non-monotonic activation function that improves the model's convergence speed and robustness.
- **Cross-Stage Partial Connections (CSP)**: A connection strategy that reduces the computational load and enhances the model's inference efficiency.
# 2. Model Fusion Strategies
### 2.1 Data Augmentation and Pretraining
#### 2.1.1 Data Augmentation Techniques
Data augmentation involves transforming and perturbing original data to create new training samples, enriching the dataset and improving the model'***mon data augmentation techniques include:
- **Random Cropping**: Randomly cropping out sub-images of different sizes and shapes from the original image.
- **Random Rotation**: Rotating the image at random angles.
- **Random Flipping**: Horizontally or vertically flipping the image.
- **Color Jittering**: Randomly altering the brightness, contrast, and saturation of the image.
- **Noise Addition**: Adding Gaussian or salt-and-pepper noise to the image.
#### 2.1.2 Pretraining Model Selection
A pretrained model is one that has been trained on a large dataset and contains rich feature extraction capabilities. Using a pretrain***monly used pretrained models include:
- **ImageNet**: A large dataset for image classification tasks, containing 1,000 categories.
- **COCO**: A large dataset for object detection and image segmentation tasks, containing 80 categories.
- **VOC**: A medium-sized dataset for object detection tasks, containing 20 categories.
### 2.2 Model Ensemble and Feature Fusion
#### 2.2.1 Model Ensemble Meth***
***mon model ensemble methods include:
- **Average Ensemble**: Taking the average of the prediction results from multiple models.
- **Weighted Ensemble**: Assigning weights to each model based on performance, then calculating the weighted average.
- **Voting Ensemble**: Voting on the prediction results from multiple models, with the majority prevailing.
#### 2.2.2 Feature Fusion Techniques
Featu***mon feature fusion techniques include:
- **Cascade Fusion**: Cascading features extracted by different models at each level.
- **Parallel Fusion**: Connecting features extracted by different models in parallel.
- **Attention Fusion**: Using an attention mechanism to weight and fuse features extracted by different models.
**Code Example:**
```python
import torch
from torchvision.models import resnet50, vgg16
# Model Ensemble: Average Ensemble
model1 = resnet50(pretrained=True)
model2 = vgg16(pretrained=True)
def model_ensemble(x):
output1 = model1(x)
output2 = model2(x)
return (output1 + output2) / 2
# Feature Fusion: Cascade Fusion
model1 = resnet50(pretrained=True)
model2 = vgg16(pretrained=True)
def feature_fusion(x):
feature1 = model1.features(x)
feature2 = model2.features(x)
return torch.cat((feature1, feature2), dim=1)
```
**Logical Analysis:**
- The `model_ensemble` function implements model ensemble, taking the average of the prediction results from two models.
- The `feature_fusion` function implements feature fusion, cascading features extracted by two models at each level.
# 3. Transfer Learning Strategies
### 3.1 Domain Adaptation and Knowledge Distillation
#### 3.1.1 Domain Adaptation Algorithms
**Domain adaptation** refers to the process of transferring a model from a source domain (source dataset and task) to a target domain (target dataset and task), where the data distributions of the source and target domains differ. Domain adaptation algorithms aim to bridge the gap between theoretical domains and improve the model'***
***mon domain adaptation algorithms include:
- **Adversarial Domain Adaptation (ADA)**: Learning the feature distributions of the source and target domains adversarially through generators and discriminators, enabling the model to generate features on the target domain similar to those on the source domain.
- **Maximum Mean Discrepancy (MMD)**: Minimizing the discrepancy between the feature distributions of the source and target domains by calculating the maximum mean differ

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
HC-06蓝牙模块构建无线通信系统指南:从零开始到专家
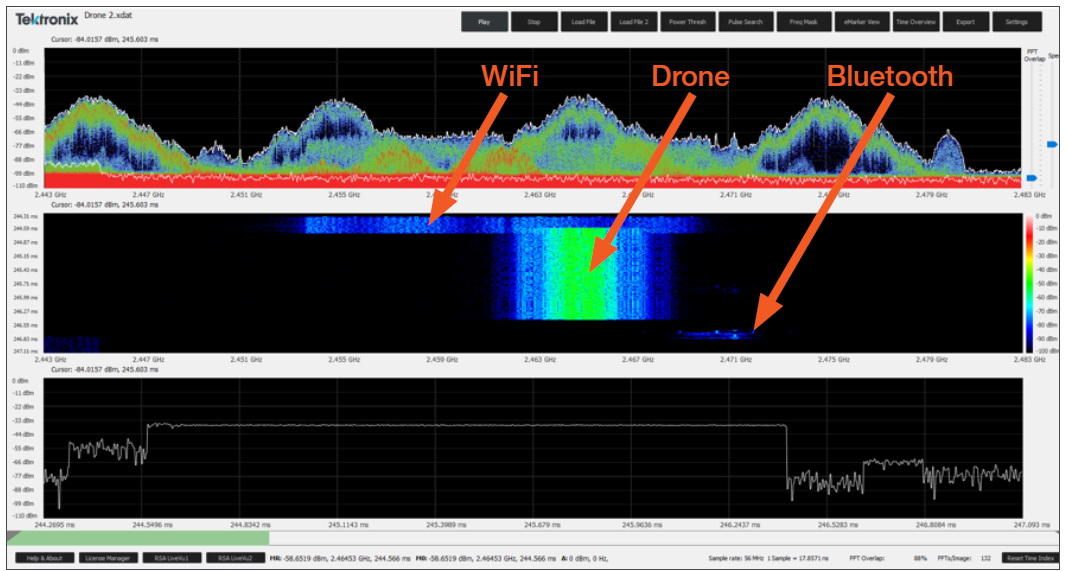
# 摘要
HC-06蓝牙模块作为一种低成本、易配置的无线通信解决方案,在物联网和移动设备应用中得到了广泛使用。本文首先介绍了HC-06模块的基本概念和硬件连接配置方法,包括其硬件接口的连接方式和基本通信参数的设置。随后,文章探讨了HC-06的编程基础,包括蓝牙通信协议的工作原理以及如何通过AT命令和串口编程控制模块。在实践应用案例部分,本文阐述了如何构建基于HC-06的无线数据传输系统以及如何开发手机应
虚拟化技术深入解析
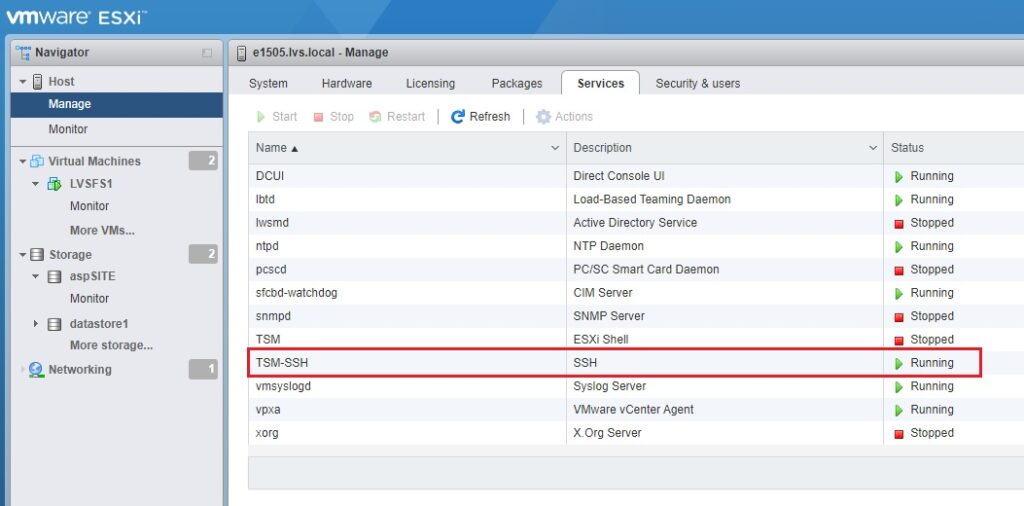
# 摘要
虚拟化技术是当代信息科技领域的重要进步,它通过抽象化硬件资源,允许多个操作系统和应用程序共享同一物理资源,从而提高了资源利用率和系统的灵活性。本文详细介绍了虚拟化技术的分类,包括硬件、操作系统级以及应用程序虚拟化,并比较了各自的优缺点,如资源利用率的提升、系统兼容性和隔离性的优势以及潜在的性能损耗与开销。文章进一步探讨了虚拟化环境的构建和管理方法,以及在企业中的实际应用案例,包括在云计算和数据中心的应用以及在灾难恢复中的作用。
Sew Movifit FC实战案例:解决实际问题的黄金法则
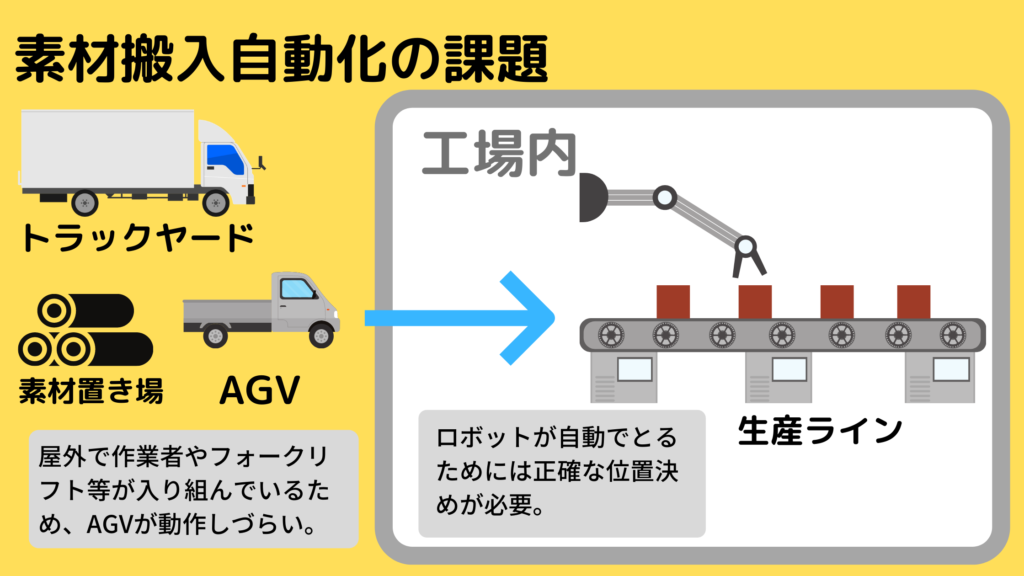
# 摘要
本文全面介绍了Sew Movifit FC的基础知识、理论基础、应用场景、实战案例分析以及高级应用技巧,并对其未来发展趋势进行了展望。Sew Movifit FC作为一种先进的技术设备,其硬件结构和软件组成共同构成了其工作原理的核心。文章详细探讨了Sew Movifit FC在工业自动化、智能家居控制以及能源管理系统等多个领域
软件测试:自动化测试框架搭建与管理的终极指南

# 摘要
自动化测试框架是软件开发中提高测试效率和质量的关键技术之一。本文首先概述了自动化测试框架的基本概念和重要性,探讨了不同类型的框架及其选择原则,并强调了测试流程优化的重要性。随后,文章提供了搭建自动化测试框架的详细实践指导,包括环境准备、代码结构设计和测试脚本编写。进一步,本文深入分析了自动化测试框架的高级应用,如模块化、持续集成以及案
透镜系统中的均匀照明秘诀:高斯光束光束整形技术终极指南

# 摘要
高斯光束作为激光技术中的基础概念,在光学研究和应用中占据重要地位。本文首先介绍了高斯光束的基本知识,包括其数学模型、空间分布以及时间和频率特性。随后,文章深入分析了高斯光束的光束整形技术,阐述了不同光束整形方法的原理、技术及实例应用。此外,本文探讨了均匀照明技术在显微成像、激光加工和光存储领域的实践应用,展示了光束整形技术的实用价值。最后,文章展望了高斯光束整
风险管理在IT项目中的应用:策略与案例研究指南

# 摘要
IT项目风险管理对于确保项目目标的实现至关重要。本文对IT项目风险管理进行了全面概述,详细介绍了项目风险的识别和评估过程,包括使用工具、技术、专家访谈以及团队共识来识别风险,并通过定性和定量的方法进行风险评估。文章还探讨了建立风险模型的分析方法,如敏感性分析和预测分析,并详细阐述了风险应对规划、缓解措施以及监控和报告的重要性。通过
负载均衡从入门到精通:静态和动态请求的高效路由
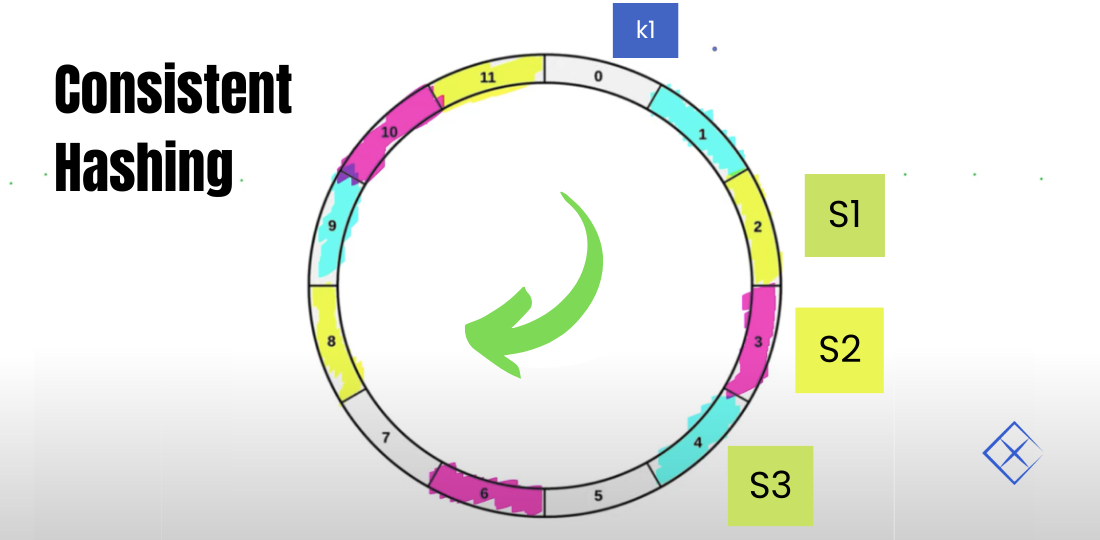
# 摘要
负载均衡是优化数据中心性能和可靠性的关键技术,本文全面探讨了负载均衡的基础原理、实现方法、高级应用以及挑战与未来趋势。首先介绍了负载均衡的基本概念和静态请求负载均衡的策略与实践,随后探讨了动态请求的负载均衡需求及其实现,并深入到高级负载均衡技术和性能调优。文章还分析了负载均衡器的选择与搭建、测试方法和案例研究,并对云计算环境、容器化架构下负载均衡的新特点进行了展望。最后,本文审视了负载均衡在多数据中心
CCS5.5代码编写:提升开发效率的顶级技巧(专家级别的实践方法)

# 摘要
CCS5.5是德州仪器公司推出的高性能集成开发环境,广泛应用于嵌入式系统的开发。本文全面介绍了CCS5.5的快速上手指南、代码编写基础、代码优化与性能提升、高级编译技术及工具链、系统级编程与硬件接口控制,以及专家级别的项目管理和团队协
【Ansys后处理器操作指南】:解决常见问题并优化您的工作流程
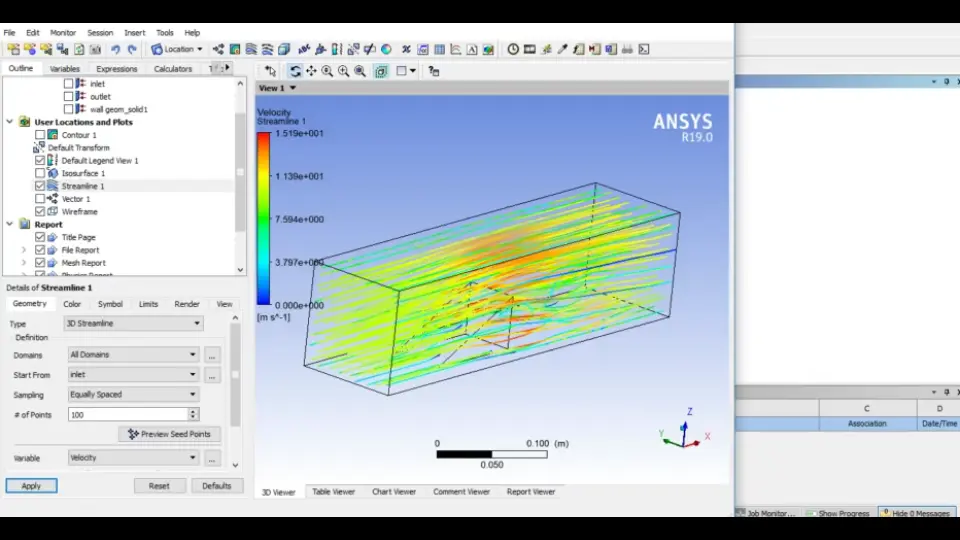
# 摘要
本文详细介绍了Ansys后处理器的功能和操作,从基础使用到高级技巧,再到定制化需求和最佳实践,为用户提供了全面的学习指南。首先,文章介绍了后处理器的界面布局和数据可视化技术,为用户提供直观的数据分析和结果展示能力。接着,文章探讨了提高后处理效率的高级技巧,包括批量处理和参数化分析。此外,文章还讨论了解决常见问题的策略,如性
MATLAB机器视觉应用:工件缺陷检测案例深度分析

# 摘要
本论文深入探讨了MATLAB在机器视觉和工件缺陷检测领域的应用。文章首先介绍了机器视觉的基础知识,随后详细阐述了工件缺陷检测的理论基础,包括其在工业生产中的重要性和发展趋势,以及图像处理和缺陷检测常用算法。第三章通过MATLAB图像处理工具箱的介绍和案例分析,展示了如何在实际中应用这些理论。第四章则探索了深度学习技术在缺陷检测中的作用,并对比分析了不同方法的性能。最后,第五章展望了机器视觉与人
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )