An Introduction to YOLOv8: The Evolutionary Journey of Convolutional Neural Networks
发布时间: 2024-09-14 00:37:55 阅读量: 44 订阅数: 38 
# Introduction to YOLOv8: The Evolution of Convolutional Neural Networks
## 1. Introduction to YOLOv8
YOLOv8 is one of the most advanced real-time object detection algorithms, ***pared to previous YOLO versions, YOLOv8 has significantly improved in both accuracy and speed. It employs advanced convolutional neural network architectures and training techniques, enabling efficient object detection across various application scenarios.
## 2. The Evolution of Convolutional Neural Networks
### 2.1 Early Convolutional Neural Networks
#### 2.1.1 LeNet-5
LeNet-5, proposed in 1998, is an early convolutional neural network widely recognized as a pioneer of modern CNNs. It was primarily used for handwritten digit recognition and had the following features:
- **Convolutional Layers:** LeNet-5 used multiple convolutional layers, each consisting of a set of filters to extract local features from the image.
- **Pooling Layers:** Following the convolutional layers were pooling layers, which reduced the size of the feature maps and increased robustness.
- **Fully Connected Layers:** After the pooling layers were fully connected layers, which mapped the extracted features to the output categories.
#### 2.1.2 AlexNet
AlexNet, proposed in 2012, was another early CNN that achieved groundbreaking results in the ImageNet image recognition competition. Features of AlexNet included:
- **Deeper Network Structure:** AlexNet was deeper than LeNet-5, with 8 convolutional layers and 3 fully connected layers.
- **ReLU Activation Function:** AlexNet utilized the ReLU activation function, enhancing the network's non-linear capabilities.
- **Data Augmentation:** AlexNet employed data augmentation techniques such as cropping, flipping, and color jittering to increase the diversity of training data.
### 2.2 Intermediate Convolutional Neural Networks
#### 2.2.1 VGGNet
VGGNet, proposed in 2014, is renowned for its simple yet effective structure. Features of VGGNet included:
- **Deeper Network Structure:** VGGNet was deeper than AlexNet, featuring 16 or 19 convolutional layers.
- **Small Convolutional Kernels:** VGGNet used 3x3 small convolutional kernels, which helped reduce the number of parameters and improve computational efficiency.
- **Max Pooling:** VGGNet employed max pooling layers, effectively reducing the size of the feature maps.
#### 2.2.2 ResNet
ResNet, proposed in 2015, addressed the vanishing gradient problem in deep networks by introducing residual connections. Features of ResNet included:
- **Residual Connections:** ResNet added residual connections between convolutional layers, allowing gradients to flow directly from input to output.
- **Shortcut Connections:** ResNet also utilized shortcut connections, enabling interaction between feature maps at different layers.
- **Batch Normalization:** ResNet employed batch normalization layers, which helped stabilize the training process and accelerate convergence.
### 2.3 Late Convolutional Neural Networks
#### 2.3.1 InceptionNet
InceptionNet, proposed in 2014, is a CNN that extracts different features from images using multiple parallel paths. Features of InceptionNet included:
- **Parallel Paths:** InceptionNet used multiple parallel paths, each extracting features with convolutional kernels of different sizes.
- **Pooling Layers:** InceptionNet employed pooling layers between parallel paths, helping reduce the size of feature maps.
- **Global Average Pooling:** InceptionNet used global average pooling layers, converting feature maps into fixed-sized vectors.
#### 2.3.2 Transformer
Transformer, proposed in 2017, is a neural network architecture initially used for natural language processing tasks. However, it has also been applied to computer vision tasks, including object detection. Features of the Transformer included:
- **Self-Attention Mechanism:** The Transformer used a self-attention mechanism, allowing interaction between different positions within the feature maps.
- **Positional Encoding:** The Transformer used positional encoding to help the model learn the relative positions of elements within the feature maps.
- **Multi-Head Attention:** The Transformer employed multi-head attention, allowing the model to extract various different representations from the feature maps.
## 3. Theoretical Foundations of YOLOv8
### 3.1 Principles of Object Detection Algorithms
Object detection algorithms aim to identify and locate interesting objects within images or videos. The basic principles include:
#### 3.1.1 Bounding Box Prediction
The bounding box prediction module is responsible for predicting the bounding boxes of target objects. It outputs a vector through a convolutional layer, containing four values for each target object: `[x_min, y_min, x_max, y_max]`. These values represent the coordinates of the top-left and bottom-right corners of the target object.
#### 3.1.2 Classification Prediction
The classification prediction module is responsible for predicting the class of each target object. It outputs a vector through a convolutional layer, containing the probabilities of each target object belonging to different classes.
### 3.2 Network Structure of YOLOv8
The YOLOv8 network structure mainly consists of three parts:
#### 3.2.1 Backbone Network
The backbone network is responsible for extracting features from the image. It uses a pre-trained convolutional neural network, such as ResNet or EfficientNet, as the base network.
#### 3.2.2 Neck Network
The neck network is responsible for fusing features from different levels of the backbone network. It uses a bottom-up path and a top-down path to connect feature maps at different levels.
#### 3.2.3 Head Network
The head network is responsible for predicting the bounding boxes and classes of target objects. It uses a series of convolutional layers and fully connected layers to process the feature maps output by the neck network.
### Code Example
The following code example demonstrates the YOLOv8 network structure:
```python
import torch
class YOLOv8(nn.Module):
def __init__(self, backbone, neck, head):
super(YOLOv8, self).__init__()
self.backbone = backbone
self.neck = neck
self.head = head
def forward(self, x):
features = self.backbone(x)
features = self.neck(features)
predictions = self.head(features)
return predictions
```
### Logical Analysis
This code defines a YOLOv8 model consisting of a backbone network, neck network, and head network. The `forward()` method passes the input image `x` through the backbone network to extract features. These features are then passed through the neck network for fusion before being passed to the head network for prediction.
### Parameter Description
- `backbone`: Backbone network, such as ResNet or EfficientNet.
- `neck`: Neck network, such as FPN or PAN.
- `head`: Head network responsible for predicting the bounding boxes and classes of target objects.
## 4. Practical Applications of YOLOv8
### 4.1 Object Detection D***
***monly used object detection datasets include:
- **COCO Dataset:** The COCO (Common Objects in Context) dataset contains over 2 million images with 91 object categories. Each image is annotated with bounding boxes and object categories.
- **VOC Dataset:** The VOC (Pascal Visual Object Classes) dataset contains over 20,000 images with 20 object categories. Each image is annotated with bounding boxes and object categories.
### 4.2 Training and Evaluation of YOLOv8
#### 4.2.1 Training Parameter Settings
When training the YOLOv8 model, the following training parameters need to be set:
- **Learning Rate:** The learning rate controls the speed at which the model updates. A learning rate of 0.001 or smaller is commonly used.
- **Batch Size:** The batch size is the number of images used in each model update. A batch size of 32 or 64 is commonly used.
- **Iterations:** Iterations refer to the number of times the model is trained. A commonly used iteration count is 100,000 or more.
#### 4.2.2 Evaluation Metrics
After training the model, the following metrics are used to evaluate the model's performance:
- **Mean Average Precision (mAP):** mAP is a comprehensive accuracy measure for object detection models. It is calculated as the average precision across all object categories.
- **Frames Per Second (FPS):** FPS measures the speed at which the model processes images. It indicates how many images the model can process per second.
### 4.3 Deployment and Optimization of YOLOv8
#### 4.3.1 Selection of Deployment Platforms
YOLOv8 models can be deployed on various platforms, including:
- **CPU:** CPUs offer lower computational power but are cost-effective.
- **GPU:** GPUs offer higher computational power but are more expensive.
- **TPU:** TPUs are specialized hardware designed for machine learning tasks. They offer the highest computational power but at the highest cost.
#### 4.3.2 Optimization Strategies
After deploying the YOLOv8 model, the following strategies can be used for optimization:
- **Quantization:** Quantization is the process of converting a floating-point model to an integer model. This can reduce the model's size and memory usage, thereby increasing inference speed.
- **Pruning:** Pruning is the process of removing unimportant weights from the model. This can decrease the model's size and memory usage, thereby increasing inference speed.
- **Fusion:** Fusion is the process of merging multiple models into a single model. This can reduce inference time and memory usage.
**Code Block:**
```python
import tensorflow as tf
# Load the YOLOv8 model
model = tf.keras.models.load_model("yolov8.h5")
# Load the image
image = tf.keras.preprocessing.image.load_img("image.jpg")
image = tf.keras.preprocessing.image.img_to_array(image)
# Predict the objects in the image
predictions = model.predict(image)
# Parse the prediction results
for prediction in predictions:
class_id = prediction[0]
confidence = prediction[1]
x1, y1, x2, y2 = prediction[2:]
# Draw the bounding box
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
```
**Logical Analysis:**
This code block demonstrates how to use the YOLOv8 model to detect objects in an image. It first loads the model, then loads the image and converts it to a NumPy array. Next, it uses the model to predict the objects in the image. Finally, it parses the prediction results and draws the bounding boxes of the objects.
**Parameter Description:**
- `model`: The YOLOv8 model to be used.
- `image`: The image to be predicted.
- `predictions`: A list of predicted objects in the image.
- `class_id`: The class ID of the object.
- `confidence`: The confidence level of the prediction.
- `x1, y1, x2, y2`: The coordinates of the object's bounding box.
## 5. Future Development of YOLOv8
### 5.1 Algorithm Improvements
There is still room for improvement in the YOLOv8 algorithm, primarily focusing on accuracy enhancement and speed optimization.
**5.1.1 Accuracy Enhancement**
***Introduce New Attention Mechanisms:** Attention mechanisms can help models focus on important areas of the image, thereby improving detection accuracy.
***Optimize Loss Functions:** Design new loss functions to better measure the prediction errors of the model, guiding the model to learn more accurate features.
***Explore New Network Structures:** Investigate deeper and wider network structures to extract richer feature information and enhance detection accuracy.
### 5.1.2 Speed Optimization
***Lightweight Models:** Reduce the computational load of the model through techniques such as pruning and quantization to increase inference speed.
***Parallel Training:** Utilize multi-GPU or distributed training technologies to shorten model training time and improve training efficiency.
***Optimize Inference Process:** Reduce overhead during the inference process through code optimization, data preprocessing optimization, etc., to increase inference speed.
### 5.2 Expansion of Application Areas
The application areas of YOLOv8 are not limited to object detection but can also be extended to other fields, such as:
**5.2.1 Security Monitoring**
***Person Detection:** Detect people in images or videos for scenarios such as security, personnel statistics, etc.
***Vehicle Detection:** Detect vehicles in images or videos for traffic management, violation identification, etc.
***Object Recognition:** Detect objects in images or videos for inventory management, stock-taking, etc.
**5.2.2 Autonomous Driving**
***Pedestrian Detection:** Detect pedestrians on the road for pedestrian avoidance functions in autonomous driving systems.
***Vehicle Detection:** Detect vehicles on the road for vehicle tracking and avoidance functions in autonomous driving systems.
***Traffic Sign Recognition:** Detect traffic signs on the road for traffic rule recognition functions in autonomous driving systems.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
模型验证的艺术:使用R语言SolveLP包进行模型评估
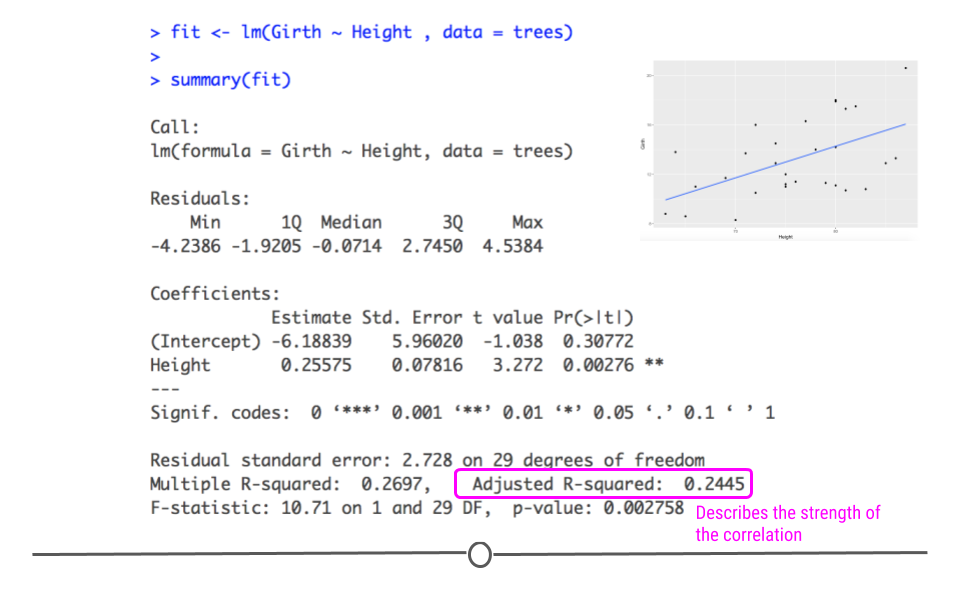
# 1. 线性规划与模型验证简介
## 1.1 线性规划的定义和重要性
线性规划是一种数学方法,用于在一系列线性不等式约束条件下,找到线性目标函数的最大值或最小值。它在资源分配、生产调度、物流和投资组合优化等众多领域中发挥着关键作用。
```mermaid
flowchart LR
A[问题定义] --> B[建立目标函数]
B --> C[确定约束条件]
C --> D[
R语言数据包安全使用指南:规避潜在风险的策略
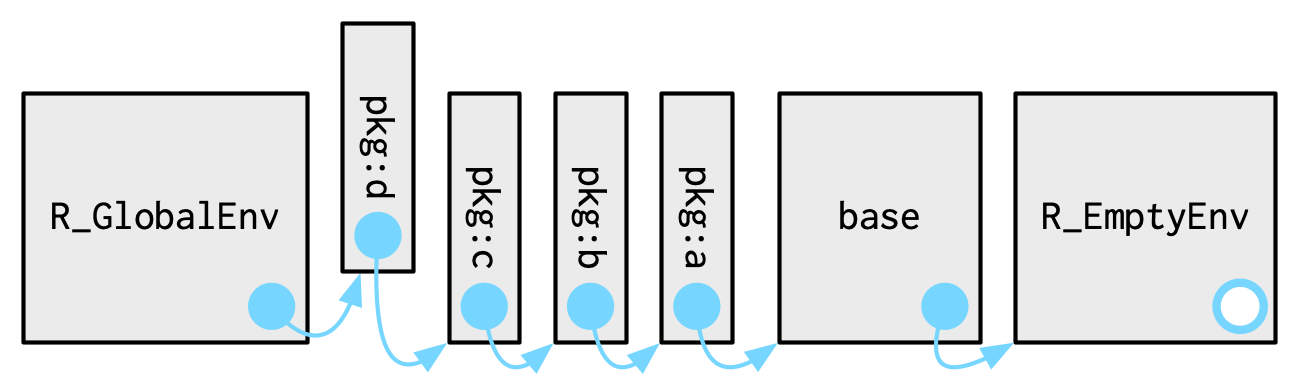
# 1. R语言数据包基础知识
在R语言的世界里,数据包是构成整个生态系统的基本单元。它们为用户提供了一系列功能强大的工具和函数,用以执行统计分析、数据可视化、机器学习等复杂任务。理解数据包的基础知识是每个数据科学家和分析师的重要起点。本章旨在简明扼要地介绍R语言数据包的核心概念和基础知识,为
R语言数据包多语言集成指南:与其他编程语言的数据交互(语言桥)

# 1. R语言数据包的基本概念与集成需求
## R语言数据包简介
R语言作为统计分析领域的佼佼者,其数据包(也称作包或库)是其强大功能的核心所在。每个数据包包含特定的函数集合、数据集、编译代码等,专门用于解决特定问题。在进行数据分析工作之前,了解如何选择合适的数据包,并集成到R的
R语言与SQL数据库交互秘籍:数据查询与分析的高级技巧
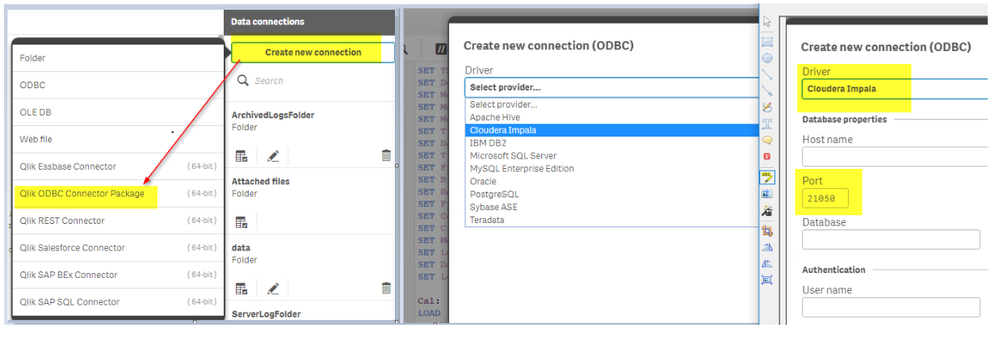
# 1. R语言与SQL数据库交互概述
在数据分析和数据科学领域,R语言与SQL数据库的交互是获取、处理和分析数据的重要环节。R语言擅长于统计分析、图形表示和数据处理,而SQL数据库则擅长存储和快速检索大量结构化数据。本章将概览R语言与SQL数据库交互的基础知识和应用场景,为读者搭建理解后续章节的框架。
## 1.
R语言数据包性能监控:实时跟踪使用情况的高效方法
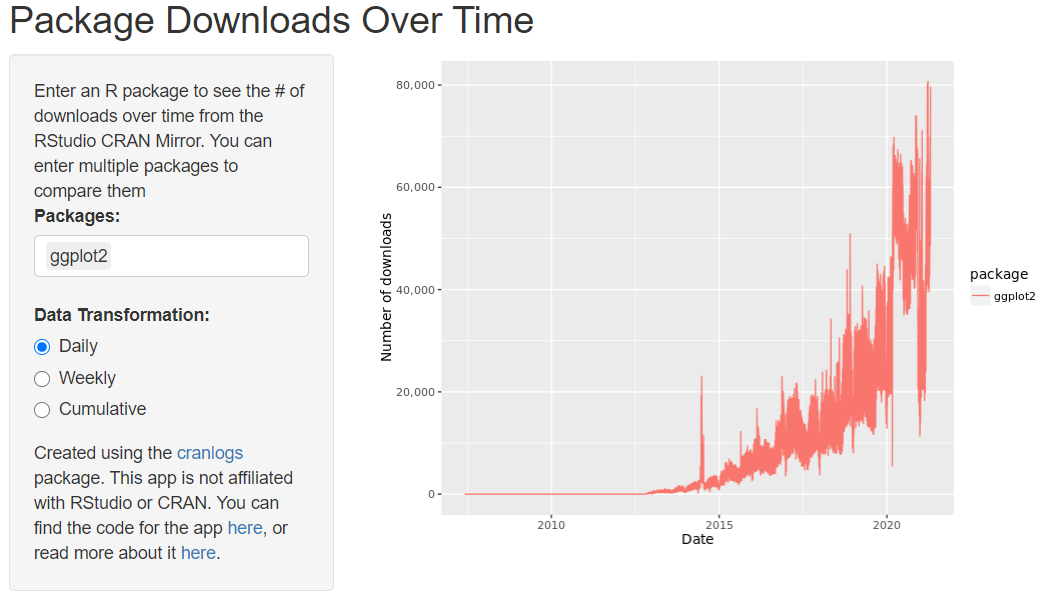
# 1. R语言数据包性能监控概述
在当今数据驱动的时代,对R语言数据包的性能进行监控已经变得越来越重要。本章节旨在为读者提供一个关于R语言性能监控的概述,为后续章节的深入讨论打下基础。
## 1.1 数据包监控的必要性
随着数据科学和统计分析在商业决策中的作用日益增强,R语言作为一款强大的统计分析工具,其性能监控成为确保数据处理效率和准确性的重要环节。性能监控能够帮助我们识别潜在的瓶颈,及时优化数据包的使用效率,提
【R语言地理信息数据分析】:chinesemisc包的高级应用与技巧
# 1. R语言与地理信息数据分析概述
R语言作为一种功能强大的编程语言和开源软件,非常适合于统计分析、数据挖掘、可视化以及地理信息数据的处理。它集成了众多的统计包和图形工具,为用户提供了一个灵活的工作环境以进行数据分析。地理信息数据分析是一个特定领域
【Tau包社交网络分析】:掌握R语言中的网络数据处理与可视化
# 1. Tau包社交网络分析基础
社交网络分析是研究个体间互动关系的科学领域,而Tau包作为R语言的一个扩展包,专门用于处理和分析网络数据。本章节将介绍Tau包的基本概念、功能和使用场景,为读者提供一个Tau包的入门级了解。
## 1.1 Tau包简介
Tau包提供了丰富的社交网络分析工具,包括网络的创建、分析、可视化等,特别适合用于研究各种复杂网络的结构和动态。它能够处理有向或无向网络,支持图形的导入和导出,使得研究者能够有效地展示和分析网络数据。
## 1.2 Tau与其他网络分析包的比较
Tau包与其他网络分析包(如igraph、network等)相比,具备一些独特的功能和优势。
模型结果可视化呈现:ggplot2与机器学习的结合
# 1. ggplot2与机器学习结合的理论基础
ggplot2是R语言中最受欢迎的数据可视化包之一,它以Wilkinson的图形语法为基础,提供了一种强大的方式来创建图形。机器学习作为一种分析大量数据以发现模式并建立预测模型的技术,其结果和过程往往需要通过图形化的方式来解释和展示。结合ggplot2与机器学习,可以将复杂的数据结构和模型结果以视觉友好的形式展现
【R语言多条件绘图】:lattice包分面绘图与交互设计的完美融合
# 1. R语言与lattice包简介
R语言是一种用于统计分析、图形表示以及报告生成的编程语言和软件环境。它因具有强大的数据处理能力和丰富的图形表现手段而广受欢迎。在R语言中,lattice包是一个专门用于创建多变量条件图形的工具,其设计理念基于Trellis图形系统,为研究人员提供了一种探索性数据分析的强大手段。
## 1.1 R语言的特点
R语言的主要特点包括:
- 开源:R是开源软件,社区支持强大,不断有新功能和包加入。
- 数据处理:R语言拥有丰富的数据处理功能,包括数据清洗、转换、聚合等。
- 可扩展:通过包的形式,R语言可以轻易地扩展新的统计方法和图形功能。
## 1.
R语言tm包中的文本聚类分析方法:发现数据背后的故事

# 1. 文本聚类分析的理论基础
## 1.1 文本聚类分析概述
文本聚类分析是无监督机器学习的一个分支,它旨在将文本数据根据内容的相似性进行分组。文本数据的无结构特性导致聚类分析在处理时面临独特挑战。聚类算法试图通过发现数据中的自然分布来形成数据的“簇”,这样同一簇内的文本具有更高的相似性。
## 1.2 聚类分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )