随机化算法的并行化与分布式实现:提升算法效率与可扩展性
发布时间: 2024-08-24 18:42:04 阅读量: 11 订阅数: 12 
# 1. 随机化算法概述
随机化算法是一种利用随机性来解决计算问题的算法。与确定性算法不同,随机化算法在执行过程中引入随机性,从而获得更优的性能或解决原本无法解决的问题。随机化算法广泛应用于各种领域,包括大数据分析、科学计算、机器学习和密码学等。
随机化算法的主要优点在于其速度和效率。通过引入随机性,随机化算法可以避免陷入局部最优解,从而找到更优的解或以更快的速度找到可接受的解。此外,随机化算法通常具有并行化的潜力,使其能够在多核处理器或分布式系统上高效执行。
# 2. 随机化算法的并行化
### 2.1 共享内存并行化
共享内存并行化是一种并行化技术,它允许多个线程或进程访问同一块共享内存。这种技术通常用于小型并行系统,例如多核计算机。
**2.1.1 OpenMP并行化**
OpenMP是一种流行的共享内存并行化编程模型。它提供了一组编译器指令,允许程序员指定并行代码块。OpenMP编译器会将这些指令转换为并行代码,以便在多核计算机上执行。
```c++
#include <omp.h>
int main() {
int sum = 0;
int n = 1000000;
int i;
#pragma omp parallel for reduction(+:sum)
for (i = 0; i < n; i++) {
sum += i;
}
printf("Sum: %d\n", sum);
return 0;
}
```
**代码逻辑分析:**
* `#pragma omp parallel for reduction(+:sum)` 指令指定一个并行循环。
* `for` 循环中的每个迭代都将由不同的线程执行。
* `reduction(+:sum)` 子句指定将每个线程的局部 `sum` 变量相加,并存储在共享变量 `sum` 中。
**2.1.2 线程池并行化**
线程池并行化是一种共享内存并行化技术,它使用一个线程池来管理并行任务。线程池中的线程等待任务,然后执行它们。这种技术通常用于大型并行系统,例如具有数百个核心的计算机。
```python
import concurrent.futures
def task(i):
return i * i
def main():
with concurrent.futures.ThreadPoolExecutor() as executor:
results = executor.map(task, range(1000000))
print(list(results))
if __name__ == "__main__":
main()
```
**代码逻辑分析:**
* `concurrent.futures.ThreadPoolExecutor()` 创建一个线程池。
* `executor.map(task, range(1000000))` 将 `task` 函数映射到 `range(1000000)` 中的每个值,并使用线程池并行执行这些任务。
* `list(results)` 将结果列表转换为一个列表。
### 2.2 分布式并行化
分布式并行化是一种并行化技术,它允许多个计算机协同工作以解决一个问题。这种技术通常用于大型并行系统,例如集群或云计算环境。
**2.2.1 MPI并行化**
MPI(消息传递接口)是一种流行的分布式并行化编程模型。它提供了一组函数,允许程序员在不同的计算机之间发送和接收消息。MPI程序员可以使用这些函数来创建分布式并行算法。
```c++
#include <mpi.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int sum = 0;
int n = 1000000;
int i;
for (i = rank; i < n; i += size) {
sum += i;
}
MPI_Reduce(&sum, &global_sum, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0) {
printf("Global sum: %d\n", global_sum);
}
MPI_Finalize();
return 0;
}
```
**代码逻辑分析:**
* `MPI_Init()` 初始化 MPI 环境。
* `MPI_Comm_rank()` 和 `MPI_Comm_size()` 获取当前进程的秩和并行进程的总数。
* 每个进程计算一个局部和。
* `MPI_Reduce()` 将局部和相加并存储在 `global_sum` 中。
* 进程 0 打印全局和。
* `MPI_Finalize()` 终止 MPI 环境。
**2.2.2 Hadoop并行化**
Hadoop是一种分布式计算框架,它允许程序员编写分布式并行算法。Hadoop使用一个主节点和多个工作节点来处理数据。主节点协调工作节点,而工作节点执行计算任务。
```java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoo
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了随机化算法的原理、应用和实战。它涵盖了广泛的主题,包括:
* MySQL数据库性能优化技巧
* MySQL死锁问题的解决之道
* MySQL索引失效的分析和解决方案
* 表锁问题的全面解析
* 随机化算法的入门指南
* 随机化算法的数学基础
* 随机化算法的类型和分类
* 随机化算法在排序、搜索、优化中的应用
* 随机化算法的复杂度分析
* 随机化算法的并行化和分布式实现
* 随机化算法在图像处理、机器学习、金融和人工智能中的应用
* 随机化算法与近似算法的关联
* 随机化算法在IT领域的变革
通过深入浅出的讲解和丰富的实战案例,本专栏旨在帮助读者理解随机化算法的原理,掌握其应用场景,并提升算法效率和性能。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32 Microcontroller Project Real Book: From Hardware Design to Software Development, Creating a Complete Microcontroller Project
# STM32 Microcontroller Project Practical Guide: From Hardware Design to Software Development, Crafting a Complete Microcontroller Project
## 1. Introduction to the STM32 Microcontroller Project Practical
### 1.1 Brief Introduction to STM32 Microcontroller
The STM32 microcontroller is a series of
Setting up a Cluster Environment with VirtualBox: High Availability Applications
# 1. High Availability Applications
## 1. Introduction
Constructing highly available applications is a crucial component in modern cloud computing environments. By building a cluster environment, it is possible to achieve high availability and load balancing for applications, enhancing system stab
MATLAB Version Best Practices: Tips for Ensuring Efficient Use and Enhancing Development Productivity
# Overview of MATLAB Version Best Practices
MATLAB version management is the process of managing relationships and transitions between different versions of MATLAB. It is crucial for ensuring software compatibility, improving code quality, and simplifying collaboration. MATLAB version management in
【递归到迭代的转换】:JS树遍历算法的革命性改进
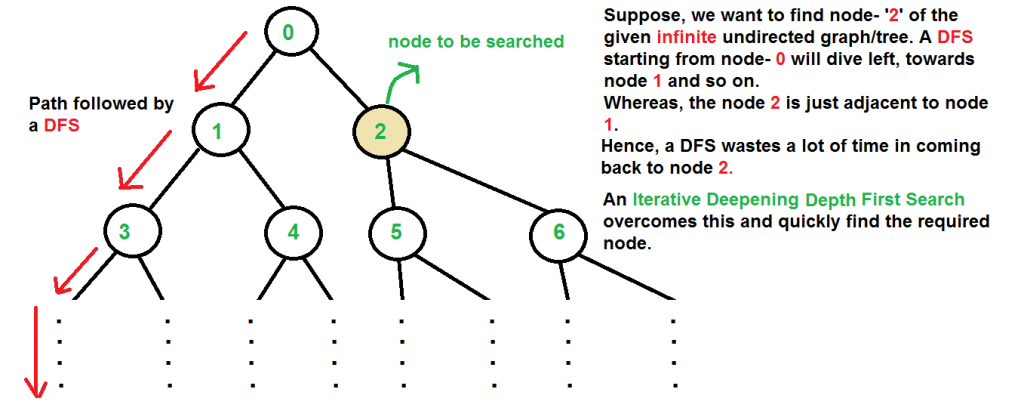
# 1. 树遍历算法概述
在计算机科学中,树是一种重要的数据结构,它以分层的方式存储数据,类似于自然界中的树木。树遍历算法是指系统地访问树中每个节点的过程。在本章中,我们将概述树遍历的基本概念和不同类型的遍历方法。
## 树数据结构简介
树是由节点组成的层次结构,每个节点包含数据和指向其子节点的引用。在树数据结构中,一个节点可能有零个或多个子节点,但只有一个父节点(除了根节点,它没有父节点)。树遍历算法可以分为两大
【数据结构深入理解】:优化JavaScript数据删除过程的技巧

# 1. JavaScript数据结构概述
## 1.1 前言
JavaScript作为Web开发的核心语言,其数据结构的处理能力对于构建高效、可维护的应用程序至关重要。在接下
【Application Analysis of Causal Inference】: The Application of Causal Inference and Counterfactual Reasoning in Linear Regression
# 1. Introduction to the Application of Causal Inference and Counterfactual Reasoning in Linear Regression
In practical data analysis, causal inference and counterfactual reasoning are among the important methods for evaluating causal relationships between events. In linear regression, applying cau
The Application of OpenCV and Python Versions in Cloud Computing: Version Selection and Scalability, Unleashing the Value of the Cloud
# 1. Overview of OpenCV and Python Versions
OpenCV (Open Source Computer Vision Library) is an open-source library of algorithms and functions for image processing, computer vision, and machine learning tasks. It is closely integrated with the Python programming language, enabling developers to eas
【构建响应式Web应用】:深入探讨高效JSON数据结构处理技巧
# 1. 响应式Web应用概述
响应式Web设计是当前构建跨平台兼容网站和应用的主流方法。本章我们将从基础概念入手,探讨响应式设计的必要性和核心原则。
## 1.1 响应式Web设计的重要性
随着移动设备的普及,用户访问网页的设备越来越多样化。响应式Web设计通过灵活的布局和内容适配,确保
MATLAB Normal Distribution Image Processing: Exploring the Application of Normal Distribution in Image Processing
# MATLAB Normal Distribution Image Processing: Exploring the Application of Normal Distribution in Image Processing
## 1. Overview of MATLAB Image Processing
Image processing is a discipline that uses computer technology to analyze, process, and modify images. MATLAB, as a powerful scientific comp
Application of Edge Computing in Multi-Access Communication
# 1. Introduction to Edge Computing and Multi-access Communication
## 1.1 Fundamental Concepts and Principles of Edge Computing
Edge computing is a computational model that pushes computing power and data storage closer to the source of data generation or the consumer. Its basic principle involves
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )