【Spark中的Reducer Join】:深入原理与性能优化
发布时间: 2024-10-31 07:02:08 阅读量: 1 订阅数: 6 

# 1. Reducer Join简介与概念
## 1.1 Reducer Join的定义
Reducer Join是一种在大数据处理框架中常见的分布式join操作方法。它主要利用了MapReduce编程模型中的Shuffle机制,通过Reducer端完成数据的合并操作。与传统的Map端join相比,Reducer Join特别适用于数据量较大的场景。
## 1.2 Reducer Join的优势
Reducer Join的优势在于其灵活性和通用性。它不依赖于数据的具体结构,能够处理具有不同key的数据集。同时,Reducer Join适用于无法在Map端完成join的情况,如某些键值的数据非常庞大,导致内存溢出。
## 1.3 Reducer Join的应用场景
在实际应用中,Reducer Join常用于需要跨数据分区进行复杂关联的场景,如在处理跨日志数据时进行用户行为分析,或者在数据仓库中进行维度表与事实表的连接。它的应用不仅限于单个集群内的数据集,也广泛应用于跨集群的数据处理任务。
# 2. Reducer Join的工作原理
Reducer Join是分布式计算中处理大数据集关联操作的重要技术,尤其在Spark等大数据处理框架中广泛应用。这一章节将详细介绍Reducer Join的执行流程、内部机制以及如何通过代码实现。
## 2.1 Reducer Join的执行流程
### 2.1.1 数据预处理
Reducer Join在执行之前,需要对数据进行预处理,以确保关联操作的准确性和高效性。数据预处理包括清洗、转换等步骤,目标是让要关联的数据能够匹配,并尽可能减少不必要的数据量。
```python
# 示例代码:数据预处理
# 假设我们有两个DataFrame df1 和 df2,我们需要移除两个DataFrame中不需要的列,并且过滤掉一些不符合要求的数据行
df1_cleaned = df1.drop('unnecessary_column').filter('valid_data_condition')
df2_cleaned = df2.drop('unnecessary_column').filter('valid_data_condition')
```
在上述代码中,`drop` 方法用于移除不需要的列,`filter` 方法用于过滤数据,确保数据符合预处理的条件。预处理后数据能够有效地减少不必要的数据传输,从而提高Reducer Join的效率。
### 2.1.2 数据分发与聚合
数据预处理后,接下来是数据分发和聚合的步骤。在Reducer Join中,Shuffle过程是关键,它负责将需要关联的数据分配到相同的Reducer节点。
```python
# 示例代码:数据分发与聚合
# 假设我们有两个已经预处理过的DataFrame df1_cleaned 和 df2_cleaned,它们需要根据某个共同的键进行Reducer Join
df1_cleaned.createOrReplaceTempView('table1')
df2_cleaned.createOrReplaceTempView('table2')
# 执行Reducer Join操作
result_df = spark.sql("""
SELECT t1.*, t2.*
***
***mon_key = ***mon_key
""")
```
在此代码中,通过`createOrReplaceTempView` 创建临时视图,并使用Spark SQL的`JOIN`操作来进行Reducer Join。`common_key`表示两个数据集关联的键。
## 2.2 Reducer Join的内部机制
### 2.2.1 Shuffle过程分析
在Reducer Join中,Shuffle过程负责将数据根据关联键重新分配。每个键值对应的数据会被发送到指定的Reducer节点上进行处理。
```mermaid
flowchart LR
subgraph Shuffl过程
A[Map端Shuffle开始] --> |按key分组| B[Shuffle写入磁盘]
B --> |网络传输| C[Reduce端Shuffle读取]
C --> |聚合数据| D[Reducer开始处理]
end
```
Shuffle过程使得分散在不同节点上的数据根据关联键聚拢,这是Reducer Join能够进行关联操作的前提。为了优化性能,合理控制Shuffle阶段的数据量和网络传输至关重要。
### 2.2.2 Map端和Reduce端的协同
Reducer Join的高效执行依赖于Map端和Reduce端的紧密协同。Map端负责处理原始数据并输出中间键值对,而Reduce端则负责接收这些键值对并进行最终的数据聚合。
```python
# 示例代码:Map端输出键值对
map_output = df.rdd.flatMap(lambda record: [(record['key'], record) for key in record.keys()])
# 示例代码:Reduce端聚合数据
def reduce_func(key, values):
# 对于每个键值对,执行聚合操作
aggregated_data = aggregate(values)
return aggregated_data
reduced_data = map_output.reduceByKey(reduce_func)
```
在上述示例代码中,Map端通过`flatMap`函数输出中间键值对,而Reduce端则通过`reduceByKey`函数聚合具有相同键的数据。
## 2.3 Reducer Join的代码实现
### 2.3.1 使用Spark原生API实现Reducer Join
Spark原生API提供了灵活的方式来实现Reducer Join。通过定义Map和Reduce函数,开发者可以精确控制数据处理过程。
```python
# 示例代码:使用Spark原生API实现Reducer Join
from pyspark import SparkContext
sc = SparkContext.getOrCreate()
# 定义Map函数
def map_function(record):
# 输出中间键值对
return [(record['key'], record['value']) for key in record.keys()]
# 定义Reduce函数
def reduce_function(key, values):
# 聚合相同键值的数据
return sum(values)
# 执行Map和Reduce操作
rdd = sc.parallelize(data).flatMap(map_function).reduceByKey(reduce_function)
```
在这个示例中,我们使用了Spark的RDD API。首先通过`parallelize`将数据转换为RDD,然后通过`flatMap`和`reduceByKey`来实现Map和Reduce过程。
### 2.3.2 使用Spark SQL实现Reducer Join
Spark SQL的加入为实现Reducer Join提供了更高级、更易读的方式。Spark SQL在执行时会将逻辑计划转换为物理执行计划,并且优化查询性能。
```python
# 示例代码:使用Spark SQL实现Reducer Join
from pyspark.sql import SparkSess
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MapReduce中的Combiner与Reducer选择策略:如何判断何时使用Combiner
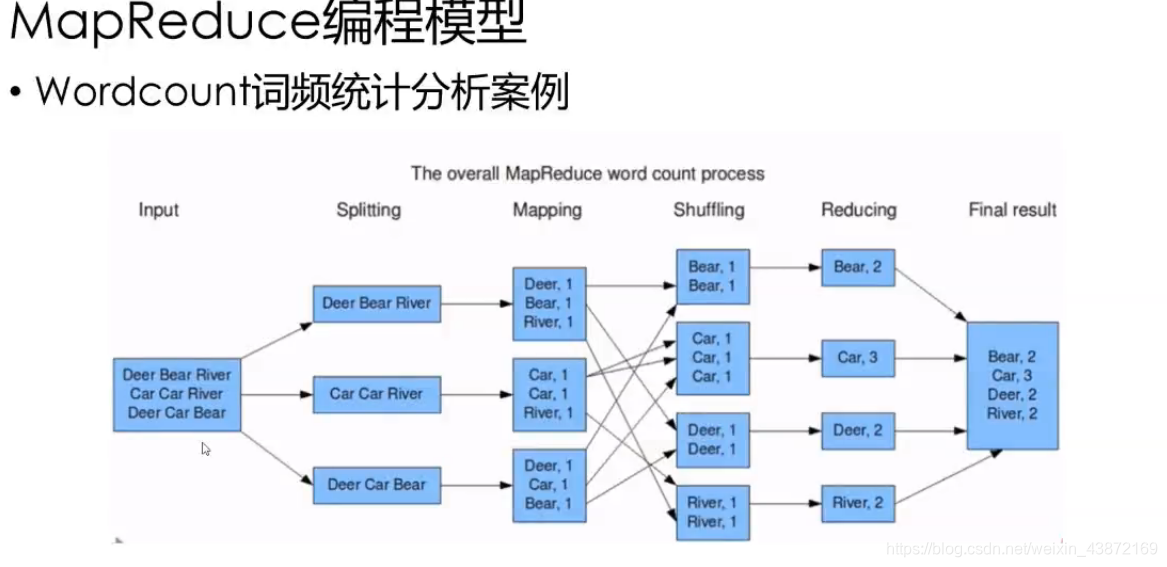
# 1. MapReduce框架基础
MapReduce 是一种编程模型,用于处理大规模数据集
MapReduce自定义分区:规避陷阱与错误的终极指导

# 1. MapReduce自定义分区的理论基础
MapReduce作为一种广泛应用于大数据处理的编程模型,其核心思想在于将计算任务拆分为Map(映射)和Reduce(归约)两个阶段。在MapReduce中,数据通过键值对(Key-Value Pair)的方式被处理,分区器(Partitioner)的角色是决定哪些键值对应该发送到哪一个Reducer。这种机制至关
MapReduce与大数据:挑战PB级别数据的处理策略

# 1. MapReduce简介与大数据背景
## 1.1 大数据的定义与特性
大数据(Big Data)是指传统数据处理应用软件难以处
【数据仓库Join优化】:构建高效数据处理流程的策略

# 1. 数据仓库Join操作的基础理解
## 数据库中的Join操作简介
在数据仓库中,Join操作是连接不同表之间数据的核心机制。它允许我们根据特定的字段,合并两个或多个表中的数据,为数据分析和决策支持提供整合后的视图。Join的类型决定了数据如何组合,常用的SQL Join类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。
## SQL Joi
项目中的Map Join策略选择
# 1. Map Join策略概述
Map Join策略是现代大数据处理和数据仓库设计中经常使用的一种技术,用于提高Join操作的效率。它主要依赖于MapReduce模型,特别是当一个较小的数据集需要与一个较大的数据集进行Join时。本章将介绍Map Join策略的基本概念,以及它在数据处理中的重要性。
Map Join背后的核心思想是预先将小数据集加载到每个Map任
【MapReduce数据处理】:掌握Reduce阶段的缓存机制与内存管理技巧

# 1. MapReduce数据处理概述
MapReduce是一种编程模型,旨在简化大规模数据集的并行运算。其核心思想是将复杂的数据处理过程分解为两个阶段:Map(映射)阶段和Reduce(归约)阶段。Map阶段负责处理输入数据,生成键值对集合;Reduce阶段则对这些键值对进行合并处理。这一模型在处理大量数据时,通过分布式计算,极大地提
跨集群数据Shuffle:MapReduce Shuffle实现高效数据流动

# 1. MapReduce Shuffle基础概念解析
## 1.1 Shuffle的定义与目的
MapReduce Shuffle是Hadoop框架中的关键过程,用于在Map和Reduce任务之间传递数据。它确保每个Reduce任务可以收到其处理所需的正确数据片段。Shuffle过程主要涉及数据的排序、分组和转移,目的是保证数据的有序性和局部性,以便于后续处理。
MapReduce小文件处理:数据预处理与批处理的最佳实践

# 1. MapReduce小文件处理概述
## 1.1 MapReduce小文件问题的普遍性
在大规模数据处理领域,MapReduce小文件问题普遍存在,严重影响
【集群资源优化】:掌握分片大小与作业调度的平衡艺术

# 1. 集群资源优化的理论基础
在现代IT架构中,集群资源优化是提高系统性能和可用性的关键。集群由多个独立的节点组成,这些节点协同工作,共同承担计算任务。优化的目标是确保集群中的资源得到高效利用,以应对日益增长的数据处理需求。
## 1.1 集群资源优化的重
【大数据精细化管理】:掌握ReduceTask与分区数量的精准调优技巧

# 1. 大数据精细化管理概述
在当今的信息时代,企业与组织面临着数据量激增的挑战,这要求我们对大数据进行精细化管理。大数据精细化管理不仅关系到数据的存储、处理和分析的效率,还直接关联到数据价值的最大化。本章节将概述大数据精细化管理的概念、重要性及其在业务中的应用。
大数据精细化管理涵盖从数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )