【进阶】生成器与迭代器的使用
发布时间: 2024-06-27 15:57:17 阅读量: 67 订阅数: 115 

深入讲解Python中的迭代器和生成器
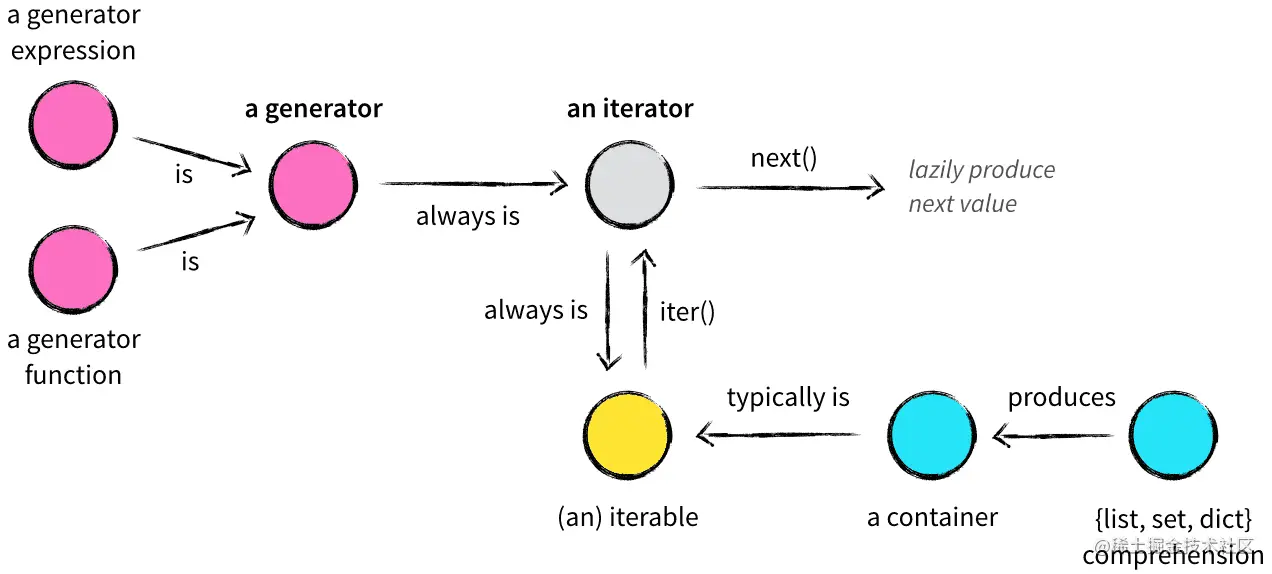
# 2.1 生成器的创建和使用
### 2.1.1 生成器函数的定义和语法
生成器函数是一种特殊的函数,它使用 `yield` 关键字来生成一个序列值。与普通函数不同,生成器函数不会立即返回结果,而是逐个生成值,直到 `yield` 关键字耗尽或遇到 `return` 语句。
生成器函数的语法如下:
```python
def generator_function():
# 生成器函数体
yield value1
yield value2
...
return
```
在生成器函数体中,`yield` 关键字后面跟要生成的下一个值。当调用生成器函数时,它不会执行整个函数,而是返回一个生成器对象。
# 2. 生成器与迭代器的实现和使用技巧
### 2.1 生成器的创建和使用
#### 2.1.1 生成器函数的定义和语法
生成器函数是通过 `yield` 关键字定义的特殊函数。`yield` 关键字用于暂停函数的执行,并将当前值返回给调用者。当调用者再次调用生成器函数时,函数将从 `yield` 处继续执行。
```python
def generate_numbers(n):
for i in range(n):
yield i
```
在这个示例中,`generate_numbers` 是一个生成器函数,它将生成从 0 到 `n-1` 的数字序列。`yield` 关键字将暂停函数的执行,并将当前值 `i` 返回给调用者。
#### 2.1.2 生成器函数的执行和迭代
生成器函数可以通过 `next()` 函数或 for 循环进行迭代。
```python
# 使用 next() 函数迭代生成器
generator = generate_numbers(5)
for i in range(5):
print(next(generator))
# 使用 for 循环迭代生成器
for i in generate_numbers(5):
print(i)
```
在第一个示例中,`next()` 函数用于逐个获取生成器中的值。在第二个示例中,for 循环用于自动迭代生成器并打印每个值。
### 2.2 迭代器的创建和使用
#### 2.2.1 迭代器对象的定义和语法
迭代器对象是实现了 `__iter__()` 和 `__next__()` 方法的对象。`__iter__()` 方法返回迭代器对象本身,`__next__()` 方法返回当前值并移动到下一个值。
```python
class MyIterator:
def __init__(self, data):
self.data = data
self.index = 0
def __iter__(self):
return self
def __next__(self):
if self.index < len(self.data):
value = self.data[self.index]
self.index += 1
return value
else:
raise StopIteration
```
在这个示例中,`MyIterator` 类实现了 `__iter__()` 和 `__next__()` 方法,使其成为一个迭代器对象。
#### 2.2.2 迭代器对象的遍历和操作
迭代器对象可以通过 for 循环进行遍历。
```python
iterator = MyIterator([1, 2, 3, 4, 5])
for i in iterator:
print(i)
```
在上面的示例中,for 循环将自动调用迭代器对象的 `__next__()` 方法,并打印每个值。
# 3.1 生成器的应用场景
#### 3.1.1 惰性求值和内存优化
生成器最大的优势之一是惰性求值,这意味着它只在需要时才计算值。这可以显著优化内存使用,尤其是在处理大型数据集或无限序列时。
例如,以下生成器生成斐波那契数列:
```python
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
```
这个生成器不会一次性计算出整个数列,而是只在需要时才计算下一个值。这使得它可以处理无限的斐波那契数列,而无需占用大量内存。
#### 3.1.2 流式处理和数据管道
生成器非常适合流式处理和数据管道。它们允许我们以一种内存高效的方式处理数据,而无需将整个数据集加载到内存中。
例如,以下生成器从文件流中读取行:
```python
def read_lines(filename):
with open(filename) as f:
while True:
line = f.readline()
if not line:
break
yield line
```
这个生成器每次只读取一行,然后将其传递给后续处理步骤。这使得我们可以处理非常大的文件,而无需将整个文件加载到内存中。
### 3.2 迭代器的应用场景
#### 3.2.1 遍历集合和数据结构
迭代器最常见的应用场景是遍历集合和数据结构。它们提供了统一的接口来访问不同类型的数据结构中的元素。
例如,以下代码使用迭代器遍历列表:
```python
my_list = [1, 2, 3, 4, 5]
for item
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了全面的 Python 自动化运维知识,涵盖了从基础到进阶的各个方面。专栏中的文章提供了详细的教程和示例,帮助读者快速掌握 Python 在运维自动化中的应用。
基础部分涵盖了 Python 环境安装、字符串处理、列表和字典的高级用法、控制流、函数、模块和包的使用、文件读写操作、文件和目录管理、os 库的使用、shutil 库的高级文件管理操作、字符串操作和正则表达式、CSV 文件、JSON 数据、XML 数据、基本数据处理和转换方法、HTTP 请求和响应处理、requests 库的 API 调用、TCP_UDP 网络编程、定时任务和批处理任务脚本、argparse 库的命令行参数处理。
进阶部分深入探讨了面向对象编程、类的继承和多态、装饰器、生成器和迭代器、上下文管理器、多线程编程、线程同步和锁机制、多进程编程、进程间通信和共享数据、异步编程、高级网络编程、socket 编程、网络数据的序列化和反序列化、pickle 数据持久化、远程调用和 RPC、SQLite 数据库、SQLAlchemy 关系型数据库操作、MySQL 和 PostgreSQL 数据库的高级技巧、MongoDB 操作、logging 模块、异常处理和调试技巧、健壮的 Python 脚本编写、Fabric 库的远程服务器管理、paramiko 的 SSH 远程操作、自动化部署脚本、Ansible 配置管理、SaltStack 的 Python 接口和应用、Puppet 的基础和高级用法、监控系统状态的脚本编写。
实战演练部分提供了实际操作指南,涵盖了 Fabric 自动化任务管理、Paramiko 远程文件传输、Ansible 自动化部署、SaltStack 自动化配置管理、Puppet 运维自动化项目、CPU 使用率监控脚本、内存使用情况监控脚本、磁盘使用情况监控和报警脚本、Python 发送邮件报警、SMSGateway 进行 SMS 报警、Prometheus 监控系统的 Python 接口、Grafana 数据可视化、Flask 基础 Web 应用开发、Django API 服务、网页爬虫、Selenium 浏览器自动化、AWS SDK 云资源管理、Terraform 与 Python 集成管理云基础设施、Jenkins 的 CI/CD 自动化脚本编写、Docker 和 Kubernetes 容器化管理。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【西数硬盘维修WDR5.3新手指南】:一步步教你基础入门和工具使用

# 摘要
本文系统介绍了西数硬盘维修软件WDR5.3的操作流程和技巧。文章首先概述了硬盘的工作原理和常见故障类型,随后详细阐释了WDR5.3软件的基本理论知识、操作实践、进阶技巧以及性能优化方法。通过详细分析真实案例,本文评估了维修前后的硬盘性能和数据恢复成功率。最后,文章总结了维修过程中的成功和失败经验,并对硬盘维修行业未来的发展趋势进行了展望。
# 关键字
硬盘维修;WDR5.3软件;故障诊断;数据恢复;性能
编程传奇:雷军如何用汇编代码重塑编程世界

# 摘要
本文全面探讨了汇编语言编程的历史演变、基础理论、编程实践技巧、雷军与汇编语言的关联故事以及其现代应用和未来展望。文章第一章回顾了汇编语言的发展历程
【BSF服务部署策略】:从理论到实际的转变

# 摘要
BSF服务部署策略是一个关键领域,涉及服务的概念、优势、部署环境、配置、优化和故障处理。本文全面概述了BSF服务的部署策略,提供了基础理论知识,并介绍了配置和优化的实际方法。文中还探讨了BSF服务的安全策略、集群部署和API集成
【智能电网新纪元】:继电保护技术的革新与IT融合
# 摘要
智能电网与继电保护技术是电力系统现代化的两大核心领域。本文首先概述了智能电网与继电保护技术的基本概念和理论基础,随后探讨了继电保护技术的创新进展和可靠性分析,同时分析了IT技术在继电保护领域的应用以及智能化系统架构和网络安全策略。在智能电网的IT技术融合实践章节,文章讨论了通信协议标准、IT系统实践案例和可持续发展策略。最后,文章展望了未来电网技术的发展方向,电网智能化面临的挑战和对策,并提出了创新与实践
【GMDSS通信原理揭秘】:深入理解与模拟实践技巧
# 摘要
本文综述了全球海上遇险与安全系统(GMDSS)的通信技术,覆盖了硬件构成、通信协议、信号处理、模拟仿真,以及系统的安全与可靠性分析。在硬件构成方面,详细探讨了GMDSS主要设备的功能与分类、通信终端技术,以及导航设备与辅助系统。通信协议与信号部分介绍了GMDSS的标准协议、信号编码与调制技术,以及安全与紧急通信流程。模拟与仿真是通过软件进行通信测试和场景模拟,重点在于实验结果的分析与验证。安全与可靠性
【硬盘克隆进阶】:深入理解扇区级复制,个性化Ghost设置详解

# 摘要
随着信息技术的飞速发展,硬盘克隆技术已成为数据备份、迁移与恢复的重要手段。本文首先概述了硬盘克隆的基本概念及其在数据保护中的作用。随后,深入分析了扇区级复制的理论基础,包括硬盘结构、扇区定义及其复制原理。在个性化Ghost设置部分,本文详细介绍了Ghost软件的操作方法、硬件加速技巧以及扇区映射和错误检测的技术。通过实践操作部分,本文指导读者如何手动和通过自
FT232H接口设计:硬件与软件的考量要点

# 摘要
FT232H作为一种常用的USB转串口芯片,在数据通信领域发挥着重要作用。本文首先概述了FT232H接口的基本概念及其工作原理,然后深入分析了硬件设计的关键考量,包括电气特性、电源管理、PCB设计等。接着,文章探讨了软件驱动开发中固件与驱动架构、跨平台兼容性以及高级通信协议实现的重要性。通过不同领域应用实例的分析,展示了F
研发部门绩效考核案例研究:构建高效研发团队的KPI系统秘籍

# 摘要
绩效考核在研发团队管理中扮演着至关重要的角色,它直接关联到团队的工作效率和目标达成。本文深入探讨了KPI(关键绩效指标)与研发团队绩效之间的紧密联系,以及如何设计有效的KPI体系以确保其与组织目标的一致性。文章通过具体实践案例,分析了建立高效研发团队KPI系统的过程,并指出
【网络启动故障不求人】:一步步教你排查与解决PXE和GHOST常见问题

# 摘要
网络启动技术是现代IT基础设施部署中不可或缺的一部分,本文旨在探讨网络启动技术的基础原理、故障排查以及高级应用。首先,介绍了PXE启动技术及其故障排查,包括PXE的工作原理、常见故障类型和排查方法。接着,深入分析了GHOST部署中遇到的故障问题及其解决策略。此外,本文还探讨了网络启动的高级应用,例如集中管理和自动化部署,以及如何通过工具
STM32定时器高级应用:HAL库定时技巧与案例分析
# 摘要
本文系统地探讨了STM32微控制器中定时器的功能、配置和应用。首先,介绍了定时器的基本工作原理和HAL库提供的API函数,以及定时器配置参数的详细解析。随后,本文深入阐述了定时器编程技巧,包括如何精确配置定时器时间和实现高级应用。文章进一步分析了定时器在不同应用场景中的实际运用,比如通信
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )